

阿里DATA X 简单使用
阿里DATA X的简单使用
1、主页
https://github.com/alibaba/DataX
2、简介(来自官网)
- DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
- DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
- 为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
3、框架设计(来自官网)
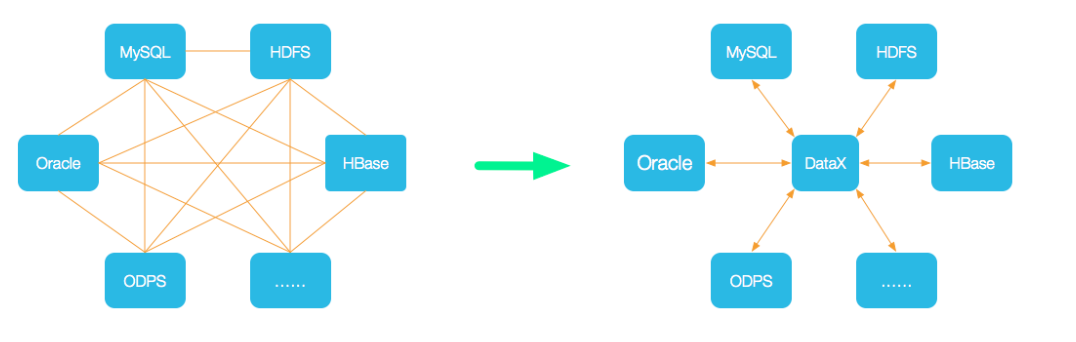

- DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
4、核心架构
见:https://github.com/alibaba/DataX/blob/master/introduction.md
5、快速安装启动
5.1、环境准备
-
Liunx
-
安装java环境

-
安装python环境(参考:https://www.cnblogs.com/lemon-feng/p/11208435.html)


-
5.2、推荐采用直接下载的方法安装编译(楼主使用git的方法出现了一些问题)
-
解压压缩包(在/usr/local下 mkdir datax)

-
解压完毕
6、读(以postgresql为例子)
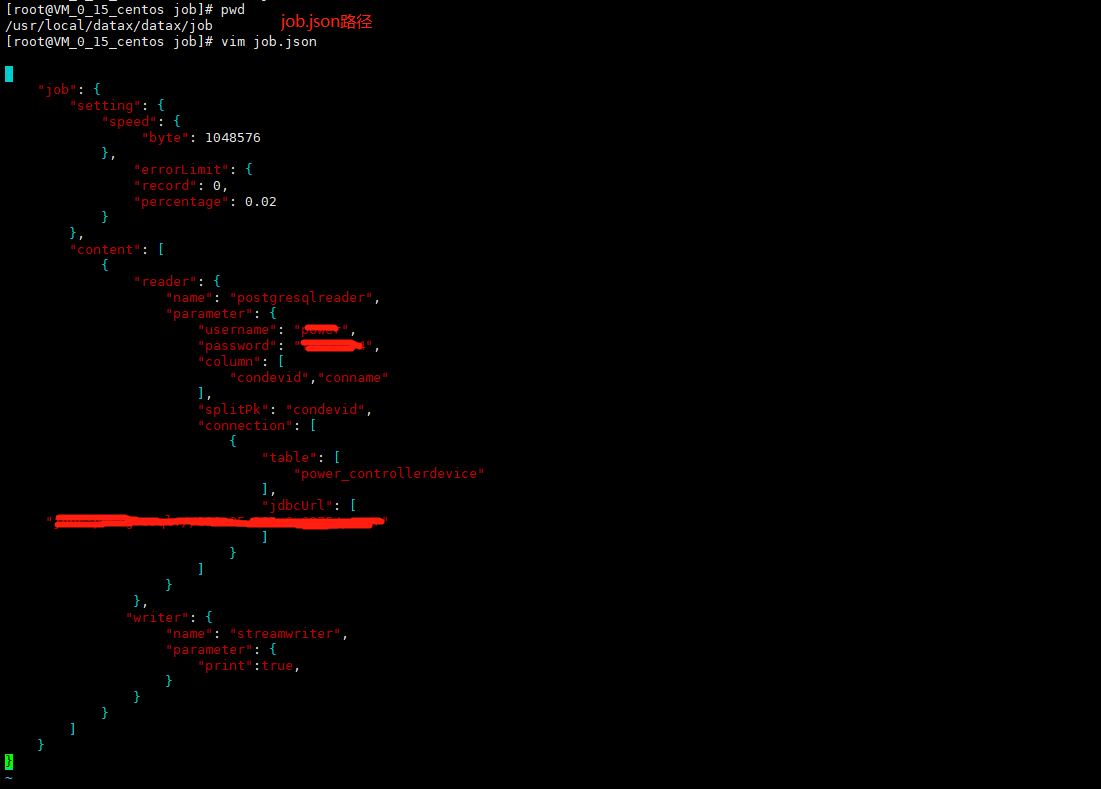
6.1、配置job(具体参数如下)
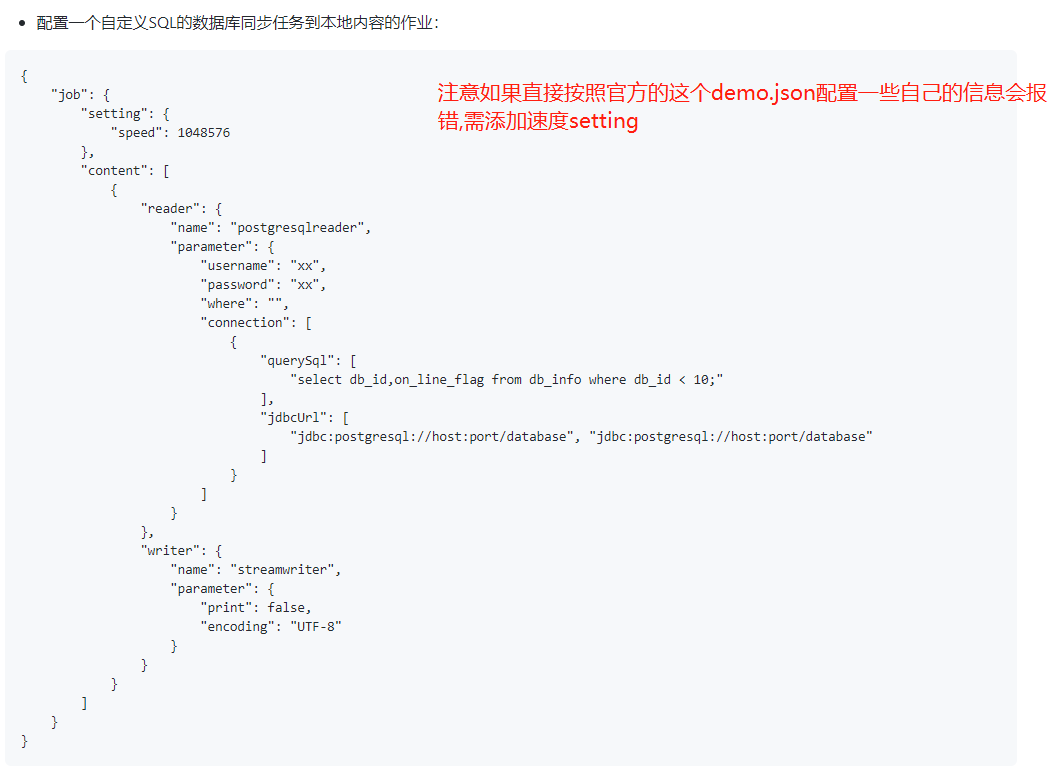
配置一个从PostgreSQL数据库同步抽取数据到本地的作业:(参数说明请看官网:https://github.com/alibaba/DataX/blob/master/postgresqlreader/doc/postgresqlreader.md)
{
"job": {
"setting": {
"speed": {
//设置传输速度,单位为byte/s,DataX运行会尽可能达到该速度但是不超过它.
"byte": 1048576
},
//出错限制
"errorLimit": {
//出错的record条数上限,当大于该值即报错。
"record": 0,
//出错的record百分比上限 1.0表示100%,0.02表示2%
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "postgresqlreader",
"parameter": {
// 数据库连接用户名
"username": "xx",
// 数据库连接密码
"password": "xx",
"column": [
"id","name"
],
//切分主键
"splitPk": "id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:postgresql://host:port/database"
]
}
]
}
},
"writer": {
//writer类型
"name": "streamwriter",
//是否打印内容
"parameter": {
"print":true,
}
}
}
]
}
}
6.2、启动DATA X

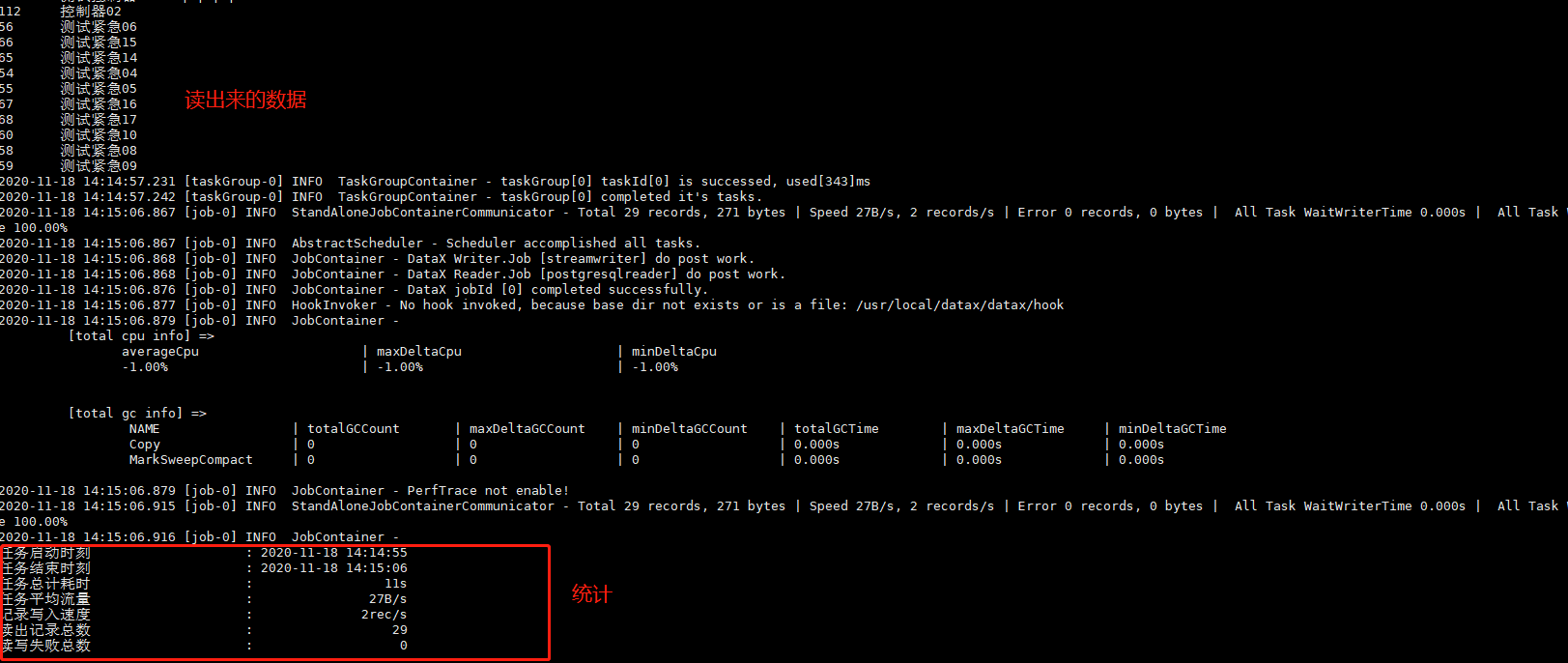
注意:

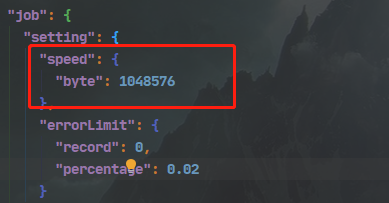
7、写
7.1、配置job
参数说明请看官网:https://github.com/alibaba/DataX/blob/master/postgresqlwriter/doc/postgresqlwriter.md
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19880808,
"type": "long"
},
{
"value": "1988-08-08 08:08:08",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "xx",
"password": "xx",
"column": [
"id",
"name"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://127.0.0.1:3002/datax",
"table": [
"test"
]
}
]
}
}
}
]
}
}
7.2、执行job
python datax.py ../job/job3.json
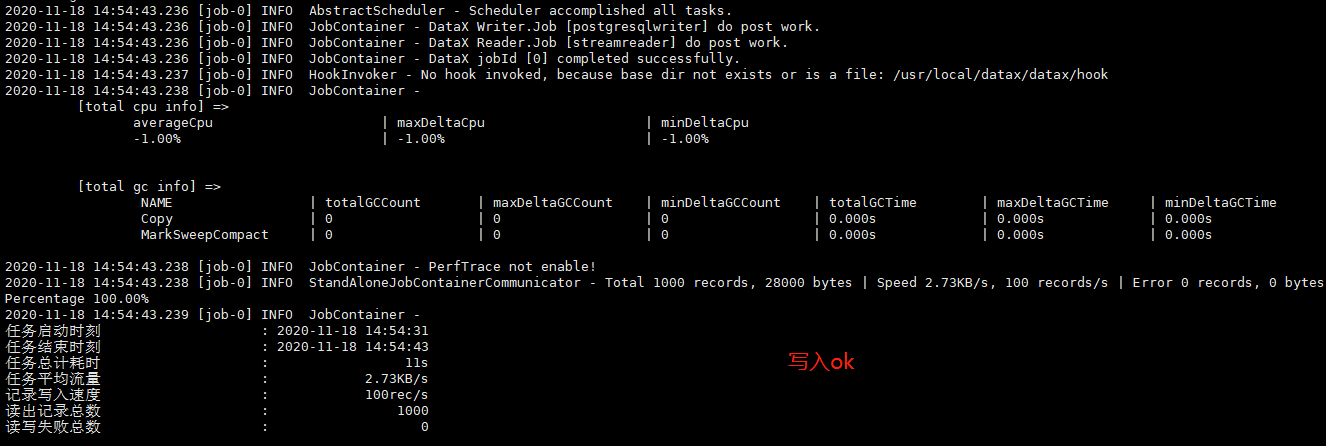
执行success
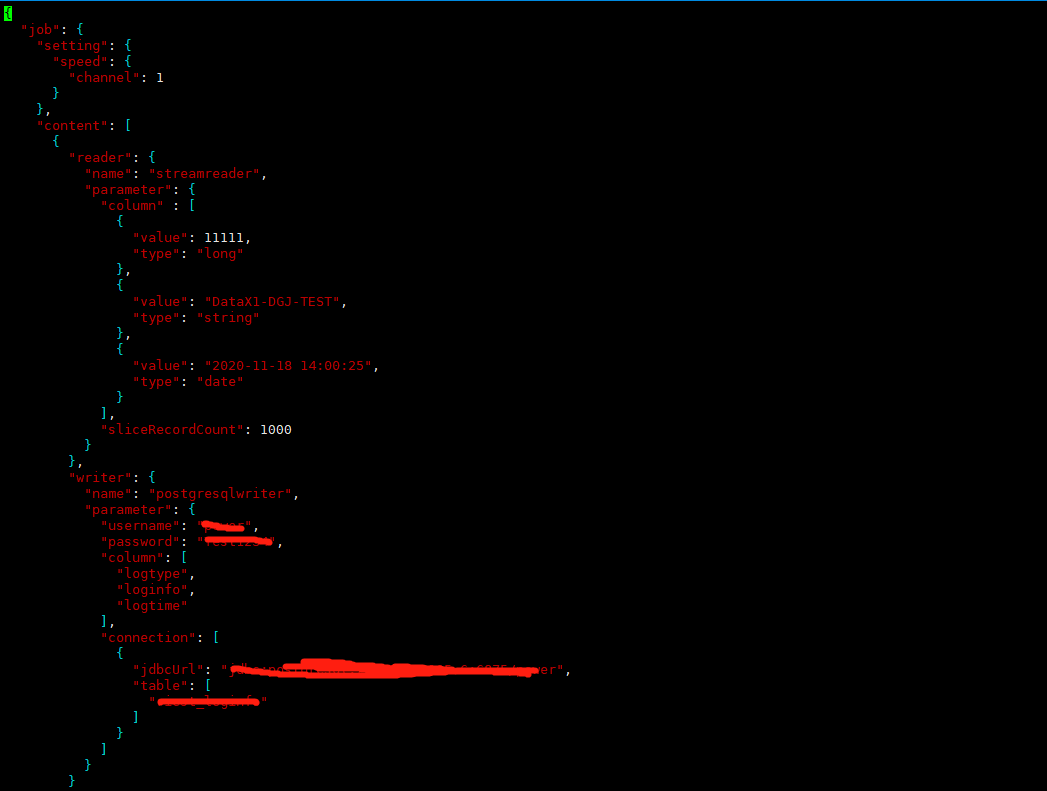
8、读写同步
8.1、配置job(配置的参数详解官网)
该job就是从一个库读数据同时写到写另外一个库之中
{
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "postgresqlreader",
"parameter": {
"username": "XXX",
"password": "XXX",
"where": "",
"connection": [
{
"querySql": [
"select
auserid, ausername, atime, muserid, musername,
mtime, tenantid, tenantname,aorgid, aorgname, auserlevel, aorglink,
aorgnamelink, conname, condevcode, condevsn,conregcode, condevtypeid,
condevtypename, condevtypefullname, posid, poslevel, posname,poslink,
posnamelink, termcount, comid, comkey, online, constate, linetime,
devlinkrun,emerswitch, setopenclosebycon
from power_controllerdevice;"
],
"jdbcUrl": [
"XXX"
]
}
]
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "XXX",
"password": "XXX",
"column": [
"auserid", "ausername", "atime", "muserid", "musername",
"mtime", "tenantid", "tenantname","aorgid", "aorgname", "auserlevel", "aorglink",
"aorgnamelink", "conname", "condevcode", "condevsn","conregcode", "condevtypeid",
"condevtypename", "condevtypefullname", "posid", "poslevel", "posname","poslink",
"posnamelink", "termcount", "comid", "comkey", "online", "constate", "linetime",
"devlinkrun","emerswitch", "setopenclosebycon"
],
"preSql": [
"delete from XXX"
],
"connection": [
{
"jdbcUrl": "XXX",
"table": [
"XXX"
]
}
]
}
}
}
]
}
}
8.2、执行job

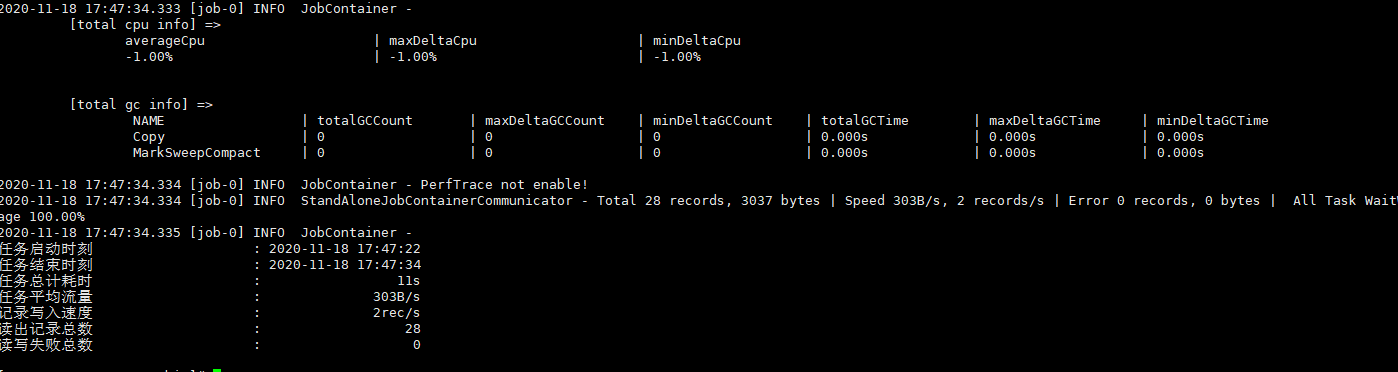
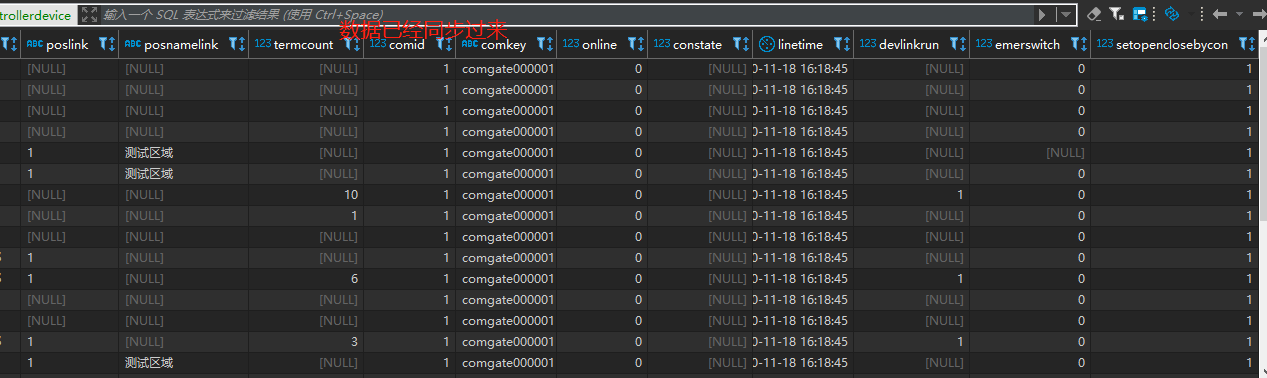
To Be Continued

