
爬虫可以用到requests以及美味汤
美味汤支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是lxml。
一、下载更新
直接pip install 安装即可
--pip install requests
--pip install beautifulsoup4
安装完毕之后即可开始爬虫之旅了
二、如何使用
1、可以先用requests去请求得到网站,也可以自己保存,随自己喜欢来,解析方式有4种,其他可能会使用其他插件,如下,常用html.parser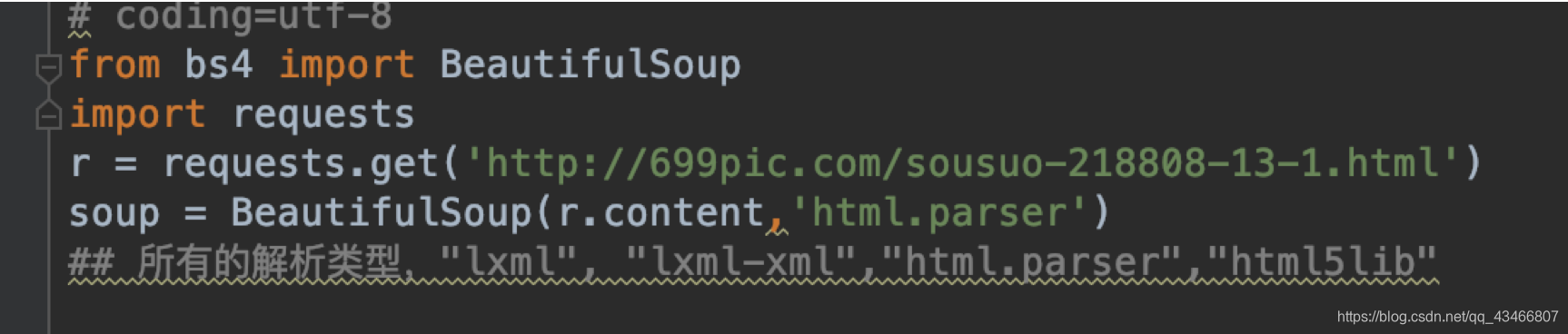
2、Beautfiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:tag,NavigableString,BeautifulSoup,Comment。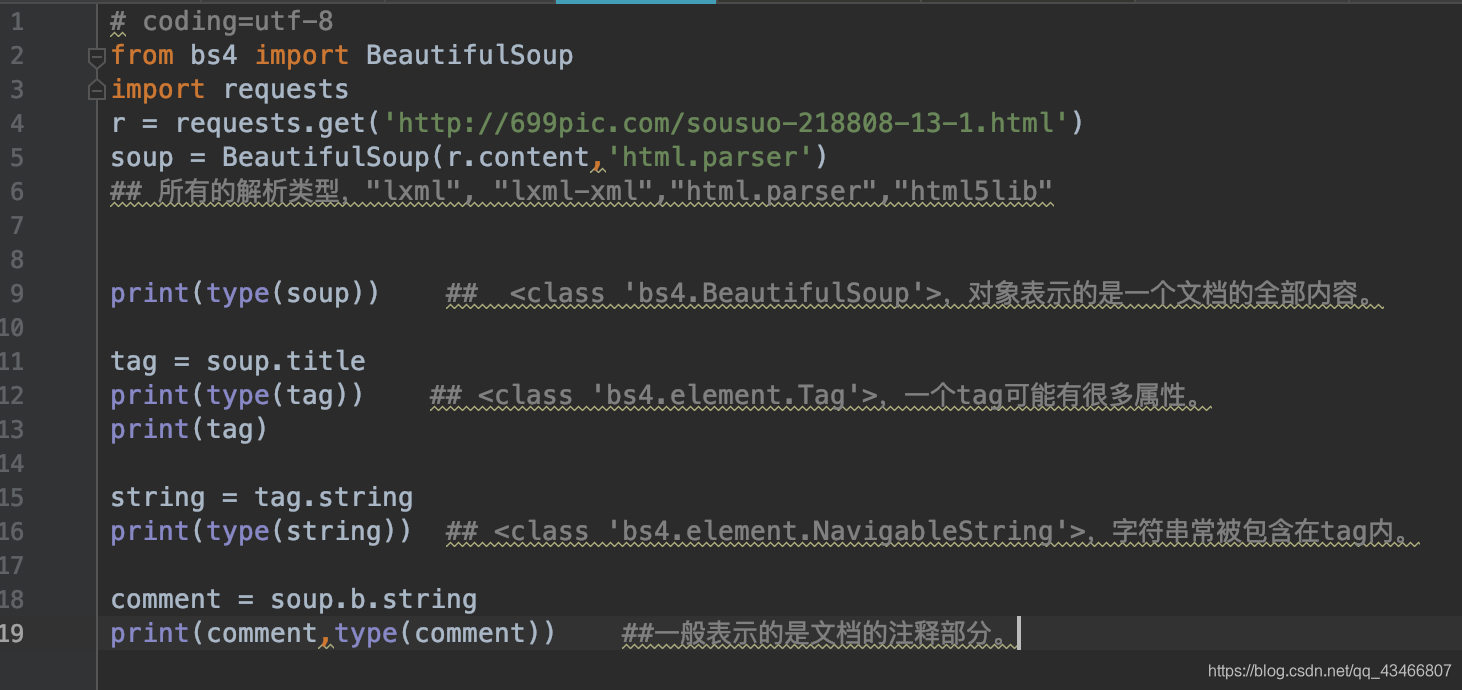
3、tag详解
—可以通过点取属性的方式获取tag,并且可以多次调用。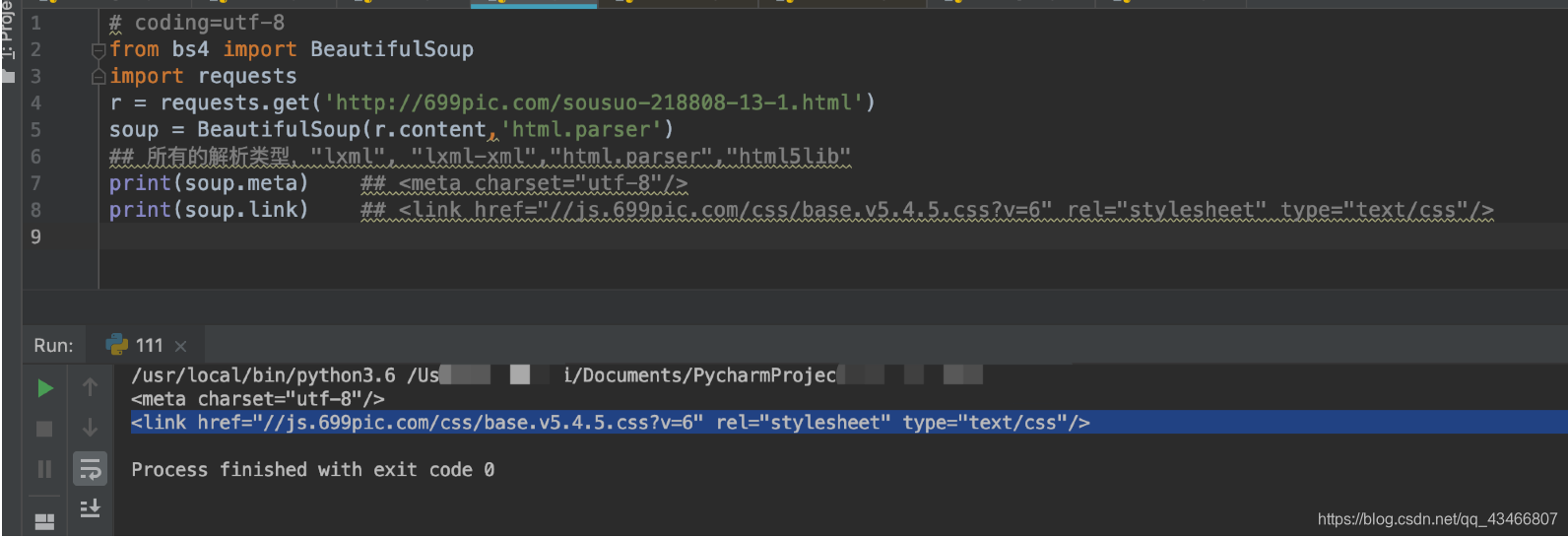
—通过点取属性的方式只能获取当前名字的第一个tag: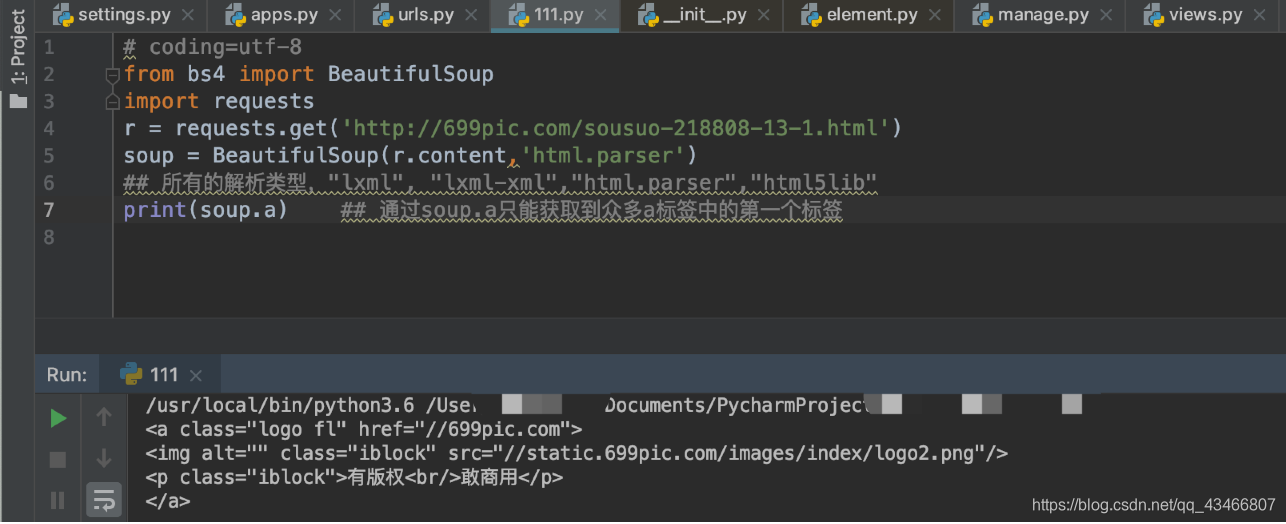
—如果想获取所有的a标签
4、find_all( name , attrs , recursive , text , **kwargs )
id=,class_=,href=*,name=标签(默认的参数)
–name参数
name参数可以查找所有名字为name的tag,比如title\head\body\p等等,常用法为find_all(‘标签名称’)
–keyword参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性.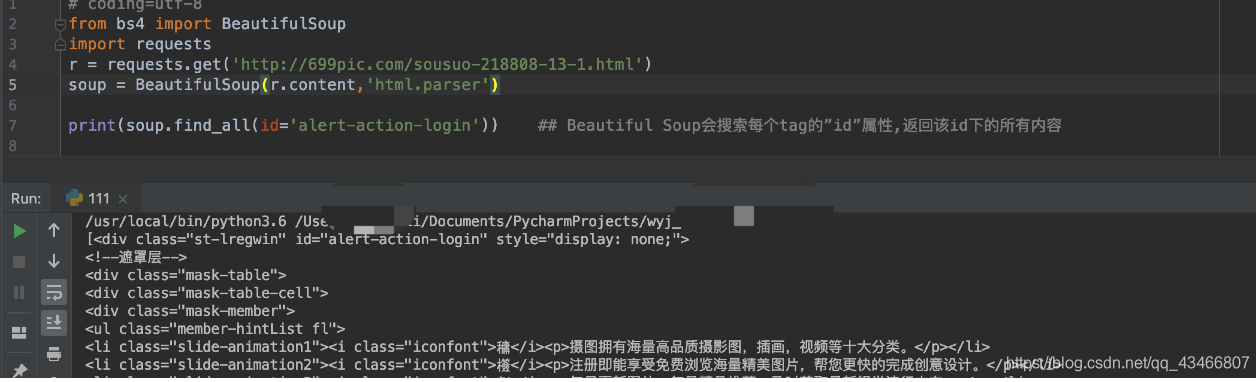
–如果传入 href 参数,Beautiful Soup会搜索每个tag的”href”属性: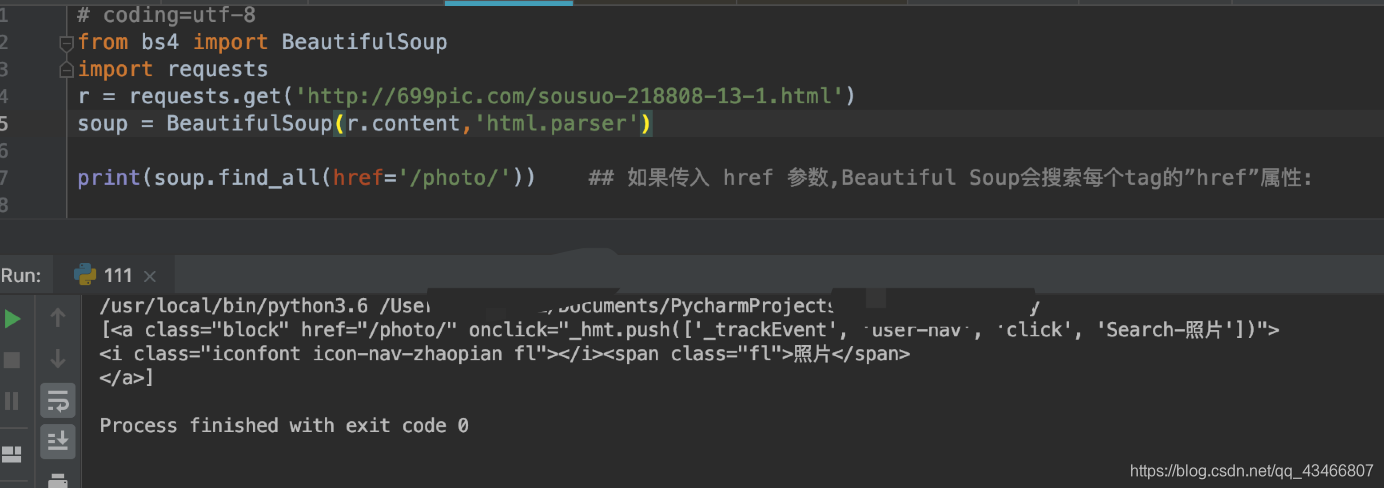
–搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
-查找所有包含 id 属性的tag,无论 id 的值是什么: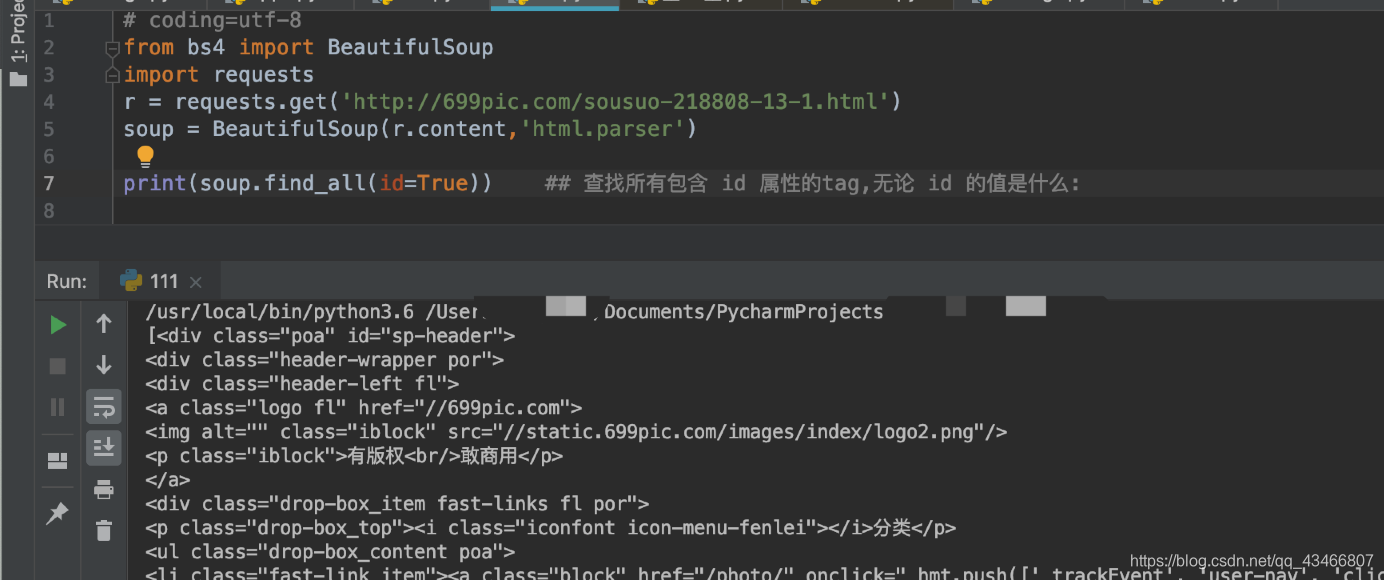
–使用多个指定名字的参数可以同时过滤tag的多个属性: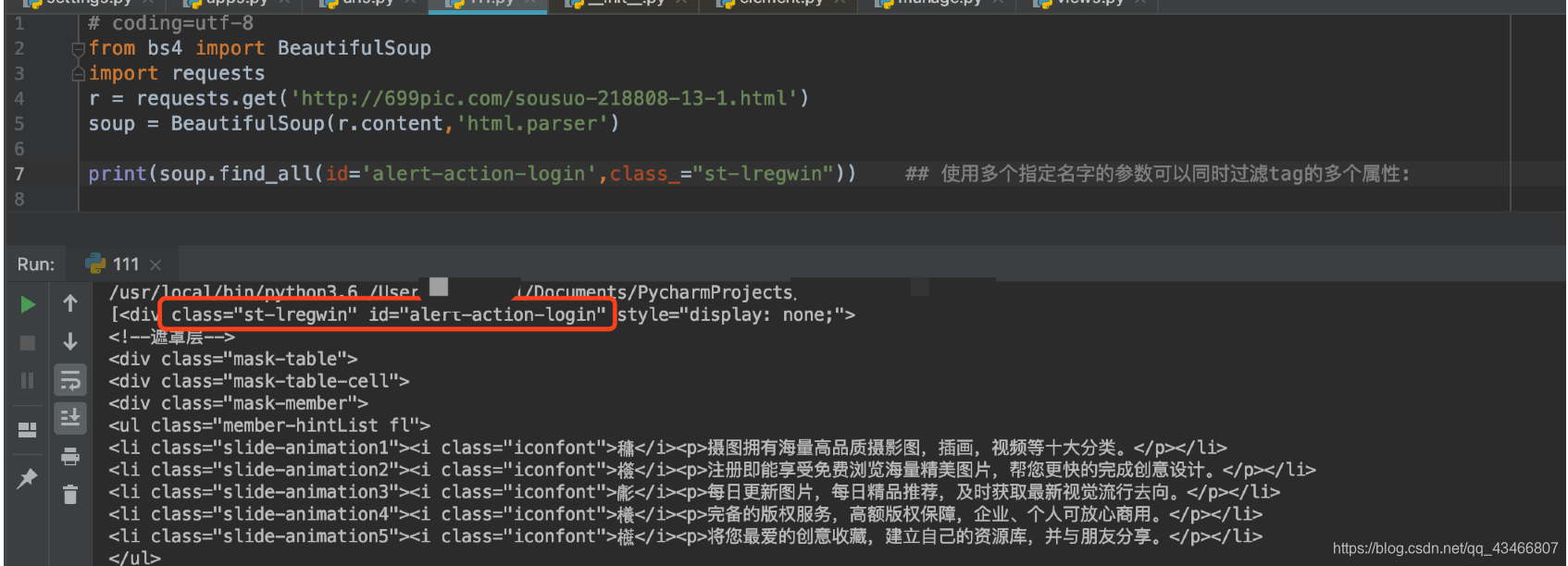
–class由于与Python关键字冲突,因此在beatifulsoup中为class_
class_ 参数同样接受不同类型的 过滤器 ,字符串,正则表达式,方法或 True
–text参数可以搜索文档中的字符串内容
与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True。
5、像调用 find_all() 一样调用tag
find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的:
soup.find_all("a")
soup("a")
这两行代码也是等价的:
soup.title.find_all(text=True)
soup.title(text=True)
CSS选择器
Beautiful Soup支持大部分的CSS选择器 [6] ,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数,即可使用CSS选择器的语法找到tag:
soup.select(“title”)
[<title>The Dormouse's story</title>]
soup.select("p nth-of-type(3)")
[<p class="story">...</p>]
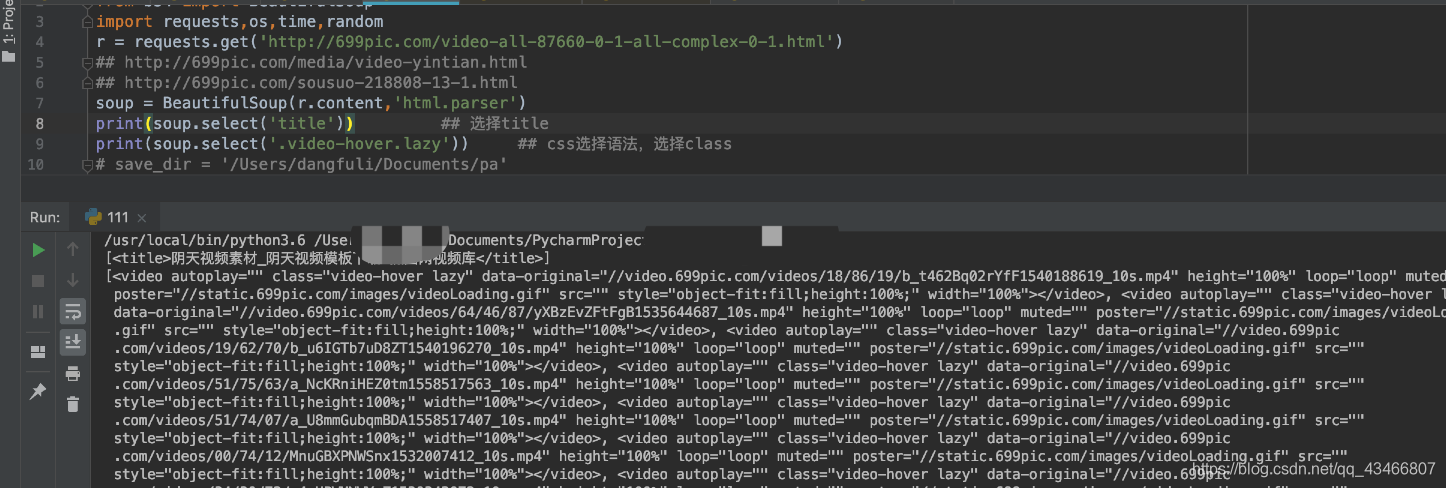
通过tag标签逐层查找:
soup.select(“body a”) 找一级

soup.select(“html head title”) 可以找子标签,相对路径即可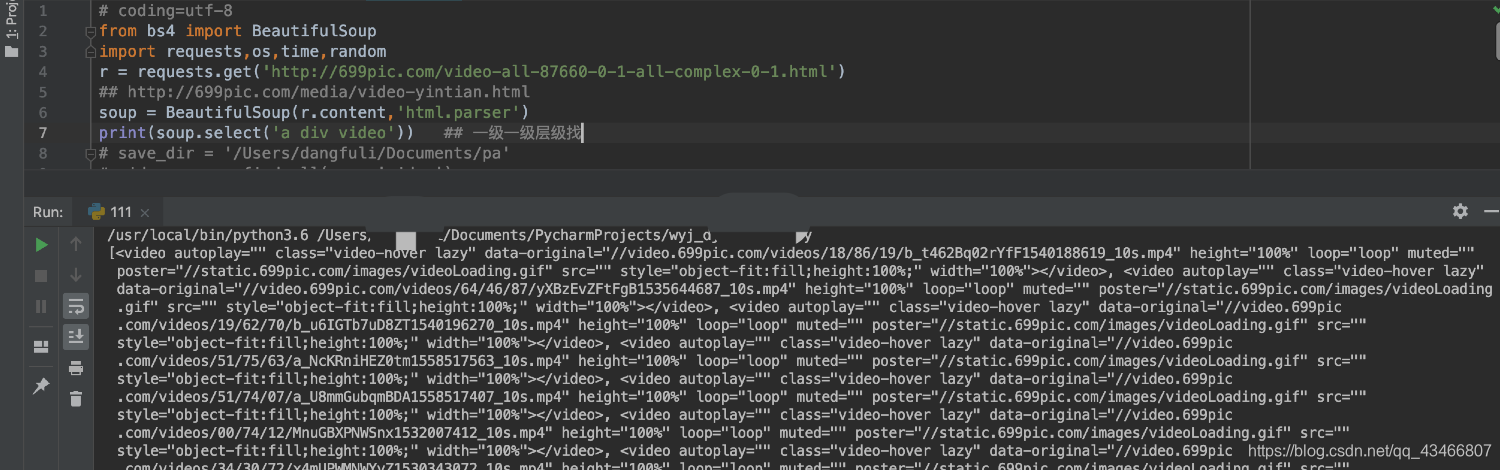
soup.select(“p > a”)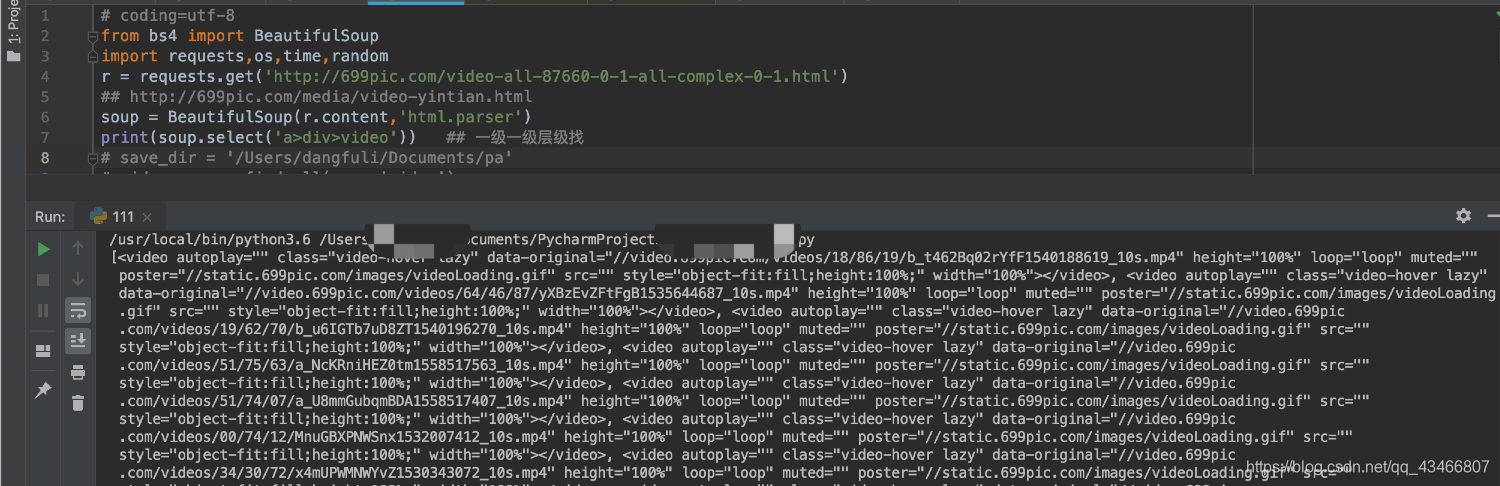
soup.select(“p > a:nth-of-type(2)”)
soup.select(“p > #link1”)
css所支持的,这里都可以用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号