RabbitMQ 快速复习
RabbitMQ学习笔记
1、消息队列概述
1.1 为什么学习消息队列
队列的主要作用是消除高并发访问高峰,加快网站的响应速度。
在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下,会对数据库造成巨大的压力,同时也使得系统响应延迟加剧。
1.2 什么是消息中间件
介绍:消息队列就是基础数据结构中的“先进先出”的一种数据机构。想一下,生活中买东西,需要排队,先排的人先买消费,就是典型的“先进先出”。

在项目中,可将一些无需即时返回且耗时的操作提取出来,进行异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
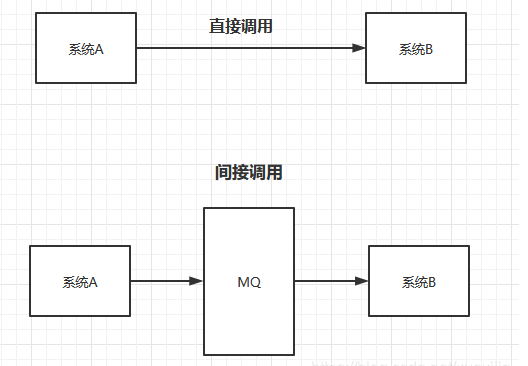
1.3 消息队列应用场景
首先我们先说一下消息中间件的主要的作用:
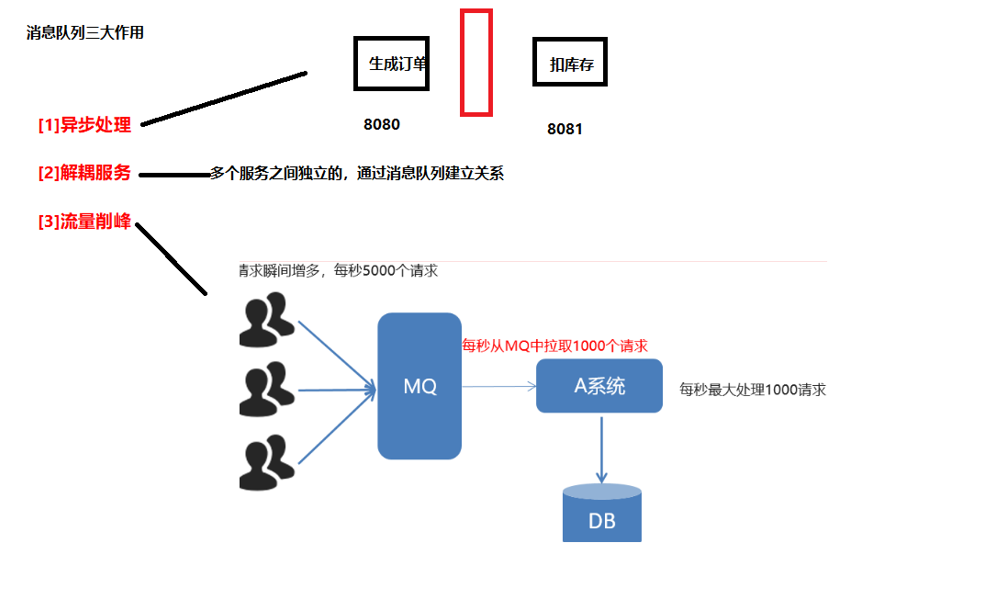
1.3.1 异步处理
场景说明:用户注册后,需要发注册邮件和注册短信,传统的做法有两种:串行和并行。但此做法的缺陷也很明显:邮件和短信对用户正常的使用网站没有任何影响,客户端没有必要等着其发送完成才显示注册成功,应该是写入数据库后就返回。引入消息队列,基本上各个节点都可以以异步的方式去处理,这样一来就能降低响应时间。
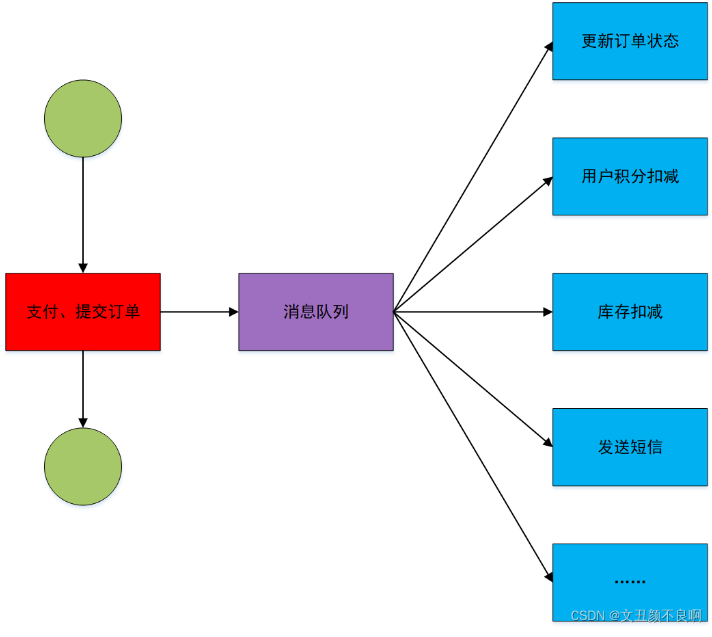
1.3.2 解耦服务
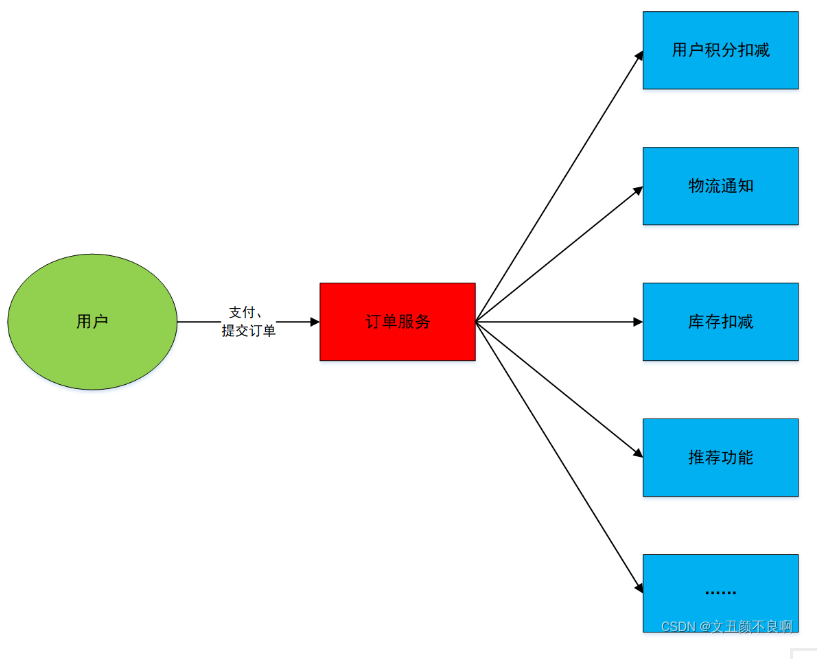
在接入消息队列之前,订单服务与各个模块交互如上图所示。接入消息队列之后,订单服务会将任务交给消息队列,由消息队列去负责与各个模块的交互。如下图所示:
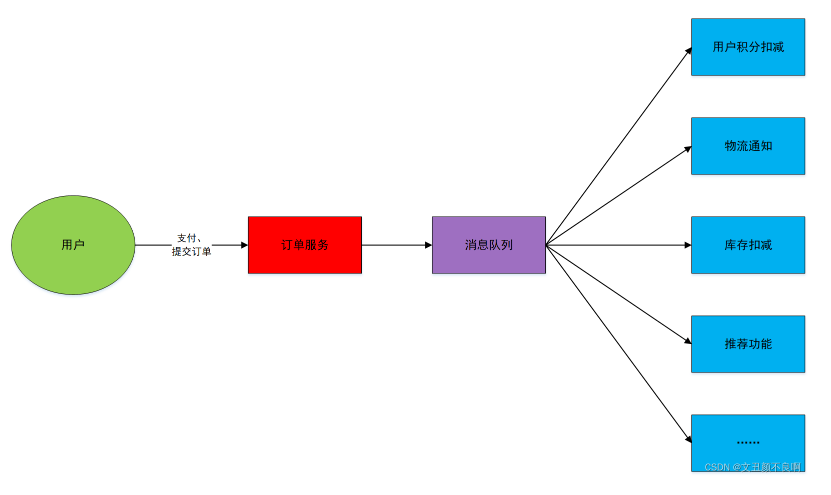
1.3.3 流量削峰
最常见的应用场景用于秒杀系统,平时的访问流量可能很低,但是要做秒杀活动时,秒杀的瞬间会疯狂请求我们的服务器,Redis,MySQL各自的承受能力都不一样,直接将全部流量照单全收的话底层系统可能会扛不住。此时,引入消息队列之后,我们可以把大量请求扔到消息队列里面,然后去慢慢处理,这样的话就达到处理大量请求的目标了。
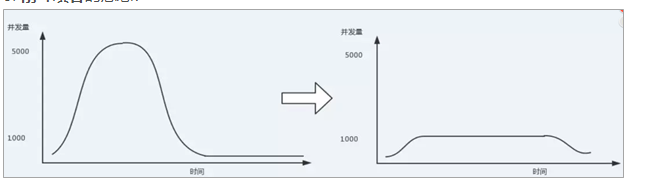
一开始的并发量,即请求很多,从而导出前面出现峰值。使用了MQ之后,控制了请求的流量,每次都取1000请求,将最开始的峰值 平均到后面的时间上,从而 “填谷"。
1.3.4 总结
上面的三点是我们使用消息中间件最主要的目的.
2、AMMQ
2.1 AMQP 中的相关概念
AMQP 一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
RabbitMQ是AMQP协议的Erlang的实现。
| 概念 | 说明 |
|---|---|
| 连接Connection | 一个网络连接,比如TCP/IP套接字连接。 |
| 信道Channel | 多路复用连接中的一条独立的双向数据流通道。为会话提供物理传输介质。 |
| 客户端Client | AMQP连接或者会话的发起者。AMQP是非对称的,客户端生产和消费消息,服务器存储和路由这些消息。 |
| 服务节点Broker | 消息中间件的服务节点;一般情况下可以将一个RabbitMQ Broker看作一台RabbitMQ 服务器。 |
| 端点 | AMQP对话的任意一方。一个AMQP连接包括两个端点(一个是客户端,一个是服务器)。 |
| 消费者Consumer | 一个从消息队列里请求消息的客户端程序。 |
| 生产者Producer | 一个向交换机发布消息的客户端应用程序。 |
2.2 RabbitMQ 中的相关概念
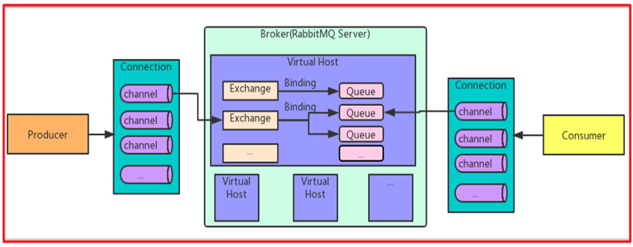
- Broker 接受和分发信息的应用
- Connection 连接
- Channel 信道
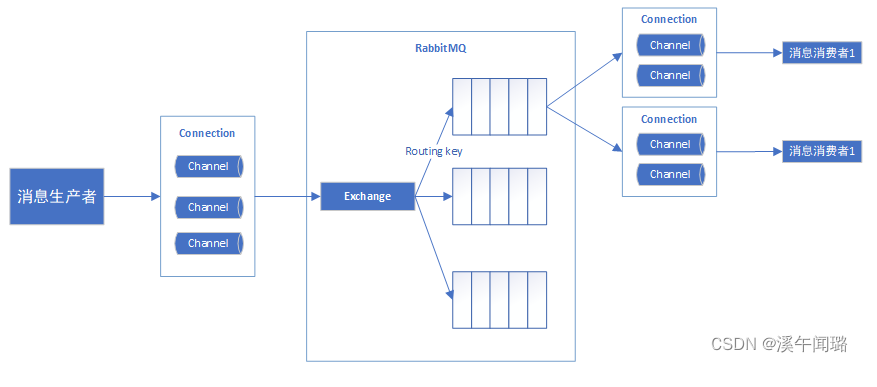
- Exchange 交换机。生产者并不是将消息直接投递到队列中的,而是将消息发送到Exchange,交换机不存储消息,而是将消息路由到一个或者多个队列中。如果路由不到,或许会返回给生产者,或许直接丢弃。Exchange有常见以下3种类型:
- Fanout:广播,将消息交给所有绑定到交换机的队列
- Direct:定向,把消息交给符合指定routing key 的队列
- Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
- Queue 队列。是RabbitMQ 的内部对象,用于存储消息。
- Binding: 绑定。 RabbitMQ 中通过绑定将交换器与队列关联起来
整体通讯过程如下图所示:
2.3 RabbitMQ工作模式
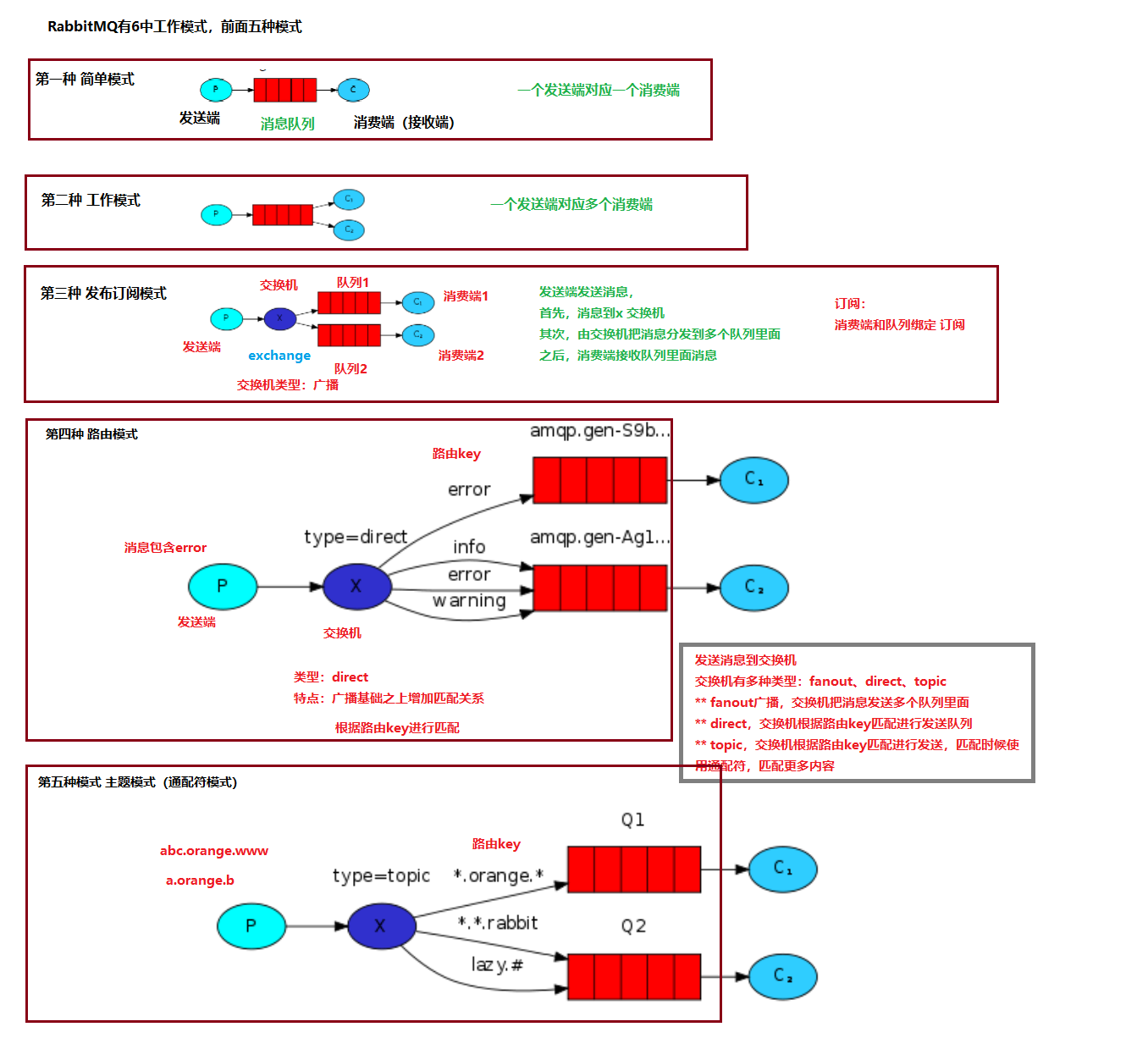
2.3.1 第一种 简单模式
一个发送端对应一个消费端(使用默认的交换机)
2.3.2 第二种 工厂模式
一个发送端对应多个消费端(使用默认的交换机)
2.3.3 第三种 发布订阅模式
- 每个消费者监听自己的队列。
- 生产者将消息发给
broker,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接收
到消息
2.3.4 第四种 路由模式
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
2.3.5 第五种 主题模式(通配符模式)
Topic类型与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
通配符规则:
#:匹配零个或多个词
*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.insert.abc 或者 item.insert
item.*:只能匹配`item.insert
2.4 RabbitMQ端口号
| Protocal | Bound to | Port | 描述 |
|---|---|---|---|
| amqp | :: | 5672 | 通信端口号 |
| clustering | :: | 25672 | 集群使用端口号 |
| http | :: | 15672 | 后台管理系统端口号 |
3、RabbitMQ高级特性
3.1 消息的可靠投递
在使用 RabbitMQ 的时候,作为消息发送方希望杜绝任何消息丢失或者投递失败场景。RabbitMQ 为我们提供了两种方式用来控制消息的投递可靠性模式。
- confirm 确认模式
- return 退回模式
路径:producer—>rabbitmq broker—>exchange—>queue—>consumer
消息从 producer(生产者) 到 exchange (交换机)则会返回一个 confirmCallback
消息从 exchange (交换机)到 queue (队列)投递失败则会返回一个 returnCallback
3.1.1 可靠性代码小结
xml文件:
<!--加载配置文件-->
<context:property-placeholder location="classpath:rabbitmq.properties"/>
<!-- 定义rabbitmq connectionFactory
确认模式开启:publisher-confirms="true"
退回模式开启:publisher-returns="true"
-->
<rabbit:connection-factory id="connectionFactory" host="${rabbitmq.host}"
port="${rabbitmq.port}"
username="${rabbitmq.username}"
password="${rabbitmq.password}"
virtual-host="${rabbitmq.virtual-host}"
publisher-confirms="true"
publisher-returns="true"
/>
<!--定义管理交换机、队列-->
<rabbit:admin connection-factory="connectionFactory"/>
<!--定义rabbitTemplate对象操作可以在代码中方便发送消息-->
<rabbit:template id="rabbitTemplate" connection-factory="connectionFactory"/>
<!--消息可靠性投递(生产端)-->
<rabbit:queue id="test_queue_confirm" name="test_queue_confirm"></rabbit:queue>
<rabbit:direct-exchange name="test_exchange_confirm">
<rabbit:bindings>
<rabbit:binding queue="test_queue_confirm" key="confirm"></rabbit:binding>
</rabbit:bindings>
</rabbit:direct-exchange>
测试类:
消费端可靠性投递-确认模式
使用 rabbitTemplate.setConfirmCallback 设置回调函数。当消息发送到 exchange 后回调 confirm 方法。在方法中判断 ack,如果为true,则发送成功,如果为false,则发送失败,需要处理。使用rabbitTemplate.convertAndSend转换并发送.
消费端可靠性投递-回退模式
使用 rabbitTemplate.setReturnCallback 设置退回函数,当消息从exchange 路由到 queue 失败后,如果设置了 rabbitTemplate.setMandatory(true) 参数,则会将消息退回给 producer并执行回调函数returnedMessage,使用rabbitTemplate.convertAndSend发送消息到交换机,并在无法路由到队列时触发回退模式。
3.1.2 Consumer Ack
ack指Acknowledge,确认。 表示消费端收到消息后的确认方式。
有二种确认方式:
- 自动确认:acknowledge=“none” 默认
- 手动确认:acknowledge=“manual”
其中自动确认是指,当消息一旦被Consumer接收到,则自动确认收到,并将相应 message 从 RabbitMQ 的消息缓存中移除。但是在实际业务处理中,很可能消息接收到,业务处理出现异常,那么该消息就会丢失。
如果设置了手动确认方式,则需要在业务处理成功后,调用channel.basicAck(),手动签收,如果出现异常,则调用channel.basicNack()方法,让其自动重新发送消息。
xml配置文件:
<!--组件扫描:监听器 -->
<context:component-scan base-package="com.atguigu.listener" />
<!--定义监听器容器
acknowledge="manual":手动签收
-->
<rabbit:listener-container connection-factory="connectionFactory" acknowledge="manual">
<rabbit:listener ref="ackListener" queue-names="test_queue_confirm"></rabbit:listener>
</rabbit:listener-container>
在rabbit:listener-container标签中设置acknowledge属性,设置ack方式 none:自动确认,manual:手动确认
如果在消费端没有出现异常,则调用channel.basicAck(deliveryTag,true);方法确认签收消息
如果出现异常,则在catch中调用 basicNack,拒绝消息,让MQ重新发送消息。
3.1.3 消费端限流
-
在
<rabbit:listener-container>中配置prefetch属性设置消费端一次拉取多少条消息。 -
消费端的必须确认才会继续处理其他消息。multiple改成true是手动签收方法,这样就可以确认消费限流。
3.2TTL
TTL 全称 Time To Live(存活时间/过期时间)。
当消息到达存活时间后,还没有被消费,会被自动清除。
RabbitMQ可以对消息设置过期时间,也可以对整个队列(Queue)设置过期时间。
xml文件:
<!--TTL 队列-->
<rabbit:queue name="test_queue_ttl" id="test_queue_ttl">
<!--设置queue的参数-->
<rabbit:queue-arguments>
<!--
设置x-message-ttl队列的过期时间
默认情况下value-type的类型是String类型,但时间的类型是number类型,所以需要设置成integer类型
-->
<entry key="x-message-ttl" value="10000" value-type="java.lang.Integer"></entry>
</rabbit:queue-arguments>
</rabbit:queue>
我们在生产端发送消息的时候可以在 properties 中指定 expiration属性来对消息过期时间进行设置,单位为毫秒(ms)。
3.3死信队列
3.3.1 概念
死信队列,英文缩写:DLX 。死信,顾名思义就是无法被消费的消息,DeadLetter Exchange(死信交换机),当消息成为Dead message后,可以被重新发送到另一个交换机,这个交换机就是DLX。
3.3.2 成为死信的三种情况
- 队列消息数量到达限制。比如队列最大只能存储10条消息,而发了11条消息,根据先进先出,最先发的消息会进入死信队列。
- 消费者拒接消费信息,basicNack/basicReject,并且不把消息重新放入原目标队列,requeue=false;
- 原队列存在消息过期设置,消息到达超时时间未被消费。
3.3.2 死信的处理方式
- 丢弃,如果不是很重要,可以选择丢弃
- 记录死信入库,然后做后续的业务分析或处理
- 通过死信队列,由负责监听死信的应用程序进行处理
3.3.3 小结
- 死信交换机和死信队列和普通的没有区别
- 当消息成为死信后,如果该队列绑定了死信交换机,则消息会被死信交换机重新路由到死信队列
3.4延迟队列
延迟队列存储的对象肯定是对应的延时消息,所谓”延时消息”是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费。
需求:
-
下单后,30分钟未支付,取消订单,回滚库存。
-
新用户注册成功30分钟后,发送短信问候。
实现方式:
TTL+死信队列 组合实现延迟队列
4、消息百分百投递
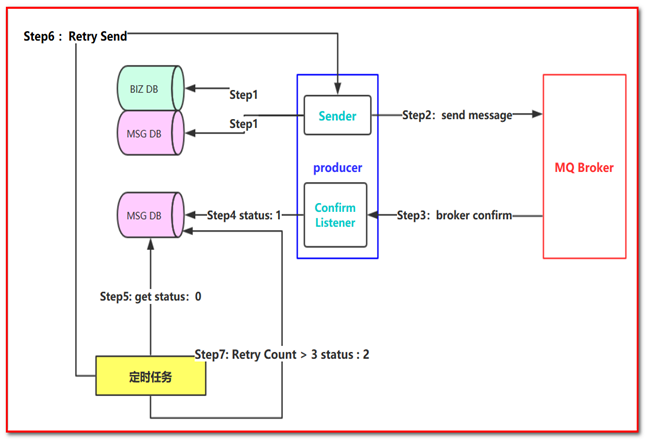
Step 1: 首先把消息信息(业务数据)存储到数据库中,紧接着,我们再把这个消息记录也存储到一张消息记录表里(或者另外一个同源数据库的消息记录表)
Step 2:发送消息到MQ Broker节点(采用confirm方式发送,会有异步的返回结果)
Step 3、4:生产者端接受MQ Broker节点返回的Confirm确认消息结果,然后进行更新消息记录表里的消息状态。比如默认Status = 0 当收到消息确认成功后,更新为1即可!
Step 5:但是在消息确认这个过程中可能由于网络闪断、MQ Broker端异常等原因导致 回送消息失败或者异常。这个时候就需要发送方(生产者)对消息进行可靠性投递了,保障消息不丢失,100%的投递成功!(有一种极限情况是闪断,Broker返回的成功确认消息,但是生产端由于网络闪断没收到,这个时候重新投递可能会造成消息重复,需要消费端去做幂等处理)所以我们需要有一个定时任务,(比如每5分钟拉取一下处于中间状态的消息,当然这个消息可以设置一个超时时间,比如超过1分钟 Status = 0 ,也就说明了1分钟这个时间窗口内,我们的消息没有被确认,那么会被定时任务拉取出来)
Step 6:接下来我们把中间状态的消息进行重新投递 retry send,继续发送消息到MQ ,当然也可能有多种原因导致发送失败
Step 7:我们可以采用设置最大努力尝试次数,比如投递了3次,还是失败,那么我们可以将最终状态设置为Status = 2 ,最后 交由人工解决处理此类问题(或者把消息转储到失败表中)。
5、消息幂等性保障
幂等性指一次和多次请求某一个资源,对于资源本身应该具有同样的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
消息幂等性保障 乐观锁机制
- 版本信息
- 时间戳
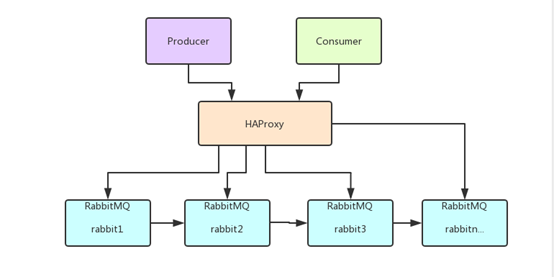
6、RabbitMQ集群搭建
本文来自博客园,作者:自律即自由-,转载请注明原文链接:https://www.cnblogs.com/deyo/p/17444937.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号