
Mysql Innodb MVCC分析
前言
在介绍MVCC之前,先看一下下述几个知识点
- 读写操作兼容性
- Copy on write下数据的读写
- Undo log使用场景以及用途
常规读写操作兼容性
广义上的读写兼容性可以参见:
| 操作类型 | 读 | 写 |
|---|---|---|
| 读 | 兼容 | 不兼容 |
| 写 | 不兼容 | 不兼容 |
可以看到只有两个(多个)操作类型均是读(不涉及数据修改)的时候才能兼容,读写/写写操作均是不兼容(互斥)的,大部分编程语言中的锁算法都遵循上述规则(共享锁/S锁/读锁对应的是数据的读取操作,排它锁/X锁/写锁对应的数据修改操作)
Copy On Write算法
在介绍MVCC机制之前,大概介绍一下Copy On Write(中文翻译为写时复制)技术,COW技术是一种广泛使用在计算机科学中的一门技术(Linux中的fork,java的CopyOnWriteArrayList等),考虑一下下述个人文件数据确认的场景
- 假设/home/user/data大小10M,一共10个用户(每个用户平均1M个人数据),需要确认文件中各自数据是否正确,假设数据正确,就无需修改(仅读操作),数据异常需要更正(写操作),在假设10个人中数据异常的概率在10%,亦即9个人的数据是对的,1个人的数据需要修复
- 传统的处理流程中,每个人独占的方式打开文件,10个人轮流确认,假设每个人确认数据耗时1小时,那么总体确认完10M数据文件耗时10个小时
- 上述流程中不难发现,90%的概率下用户是不需要进行修改操作的,只有10%的操作需要串行化去处理
- COW的流程中,10个人默认对于文件均有访问权限(非独占的方式),假设用户1需要修改,那么此时系统会基于原始的数据文件Copy一份副本,用户1确认修改完成后,保存副本,系统将此副本覆盖回原始文件,剩余用户的读操作不受影响
- 可以看到在上述流程中,理论上原本需要10个小时的工作,极限情况下可以缩短到1个小时(10->1)的默认,系统只需要处理1个写操作的覆盖即可
下述图片展示了一个常见的读写共享文件的步骤
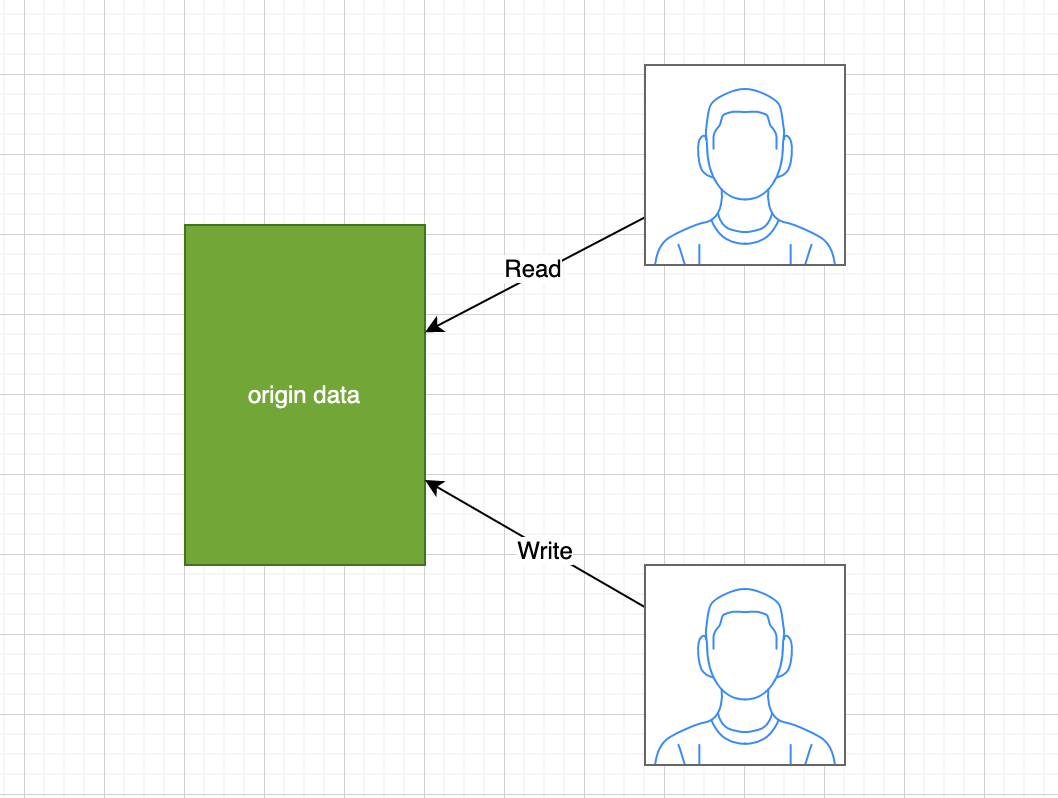
采用COW读写文件的简易流程
COW技术的局限性在于倘若系统中写的比率占比高的话,某种程度上来说用户处理冲突会额外的花费一部分处理时间,以上述场景举例,假定处理冲突的时间耗时1.5H,假设30%冲突的概率(亦即三个用户需要修改)来算,整体的处理流程大概耗时1h+4.5h = 5.5h,倘若10个人都需要修改,那么原始10个小时的串行处理流程,在使用COW的场景下很有可能演变为1h+10*1.5h = 16h的场景
综上,COW技术适用于系统中读多写少这一类的场景,并发写入占比过高的话,某种程度上独占的方式更简单高效
COW场景下读写操作的兼容性
| 操作类型 | 读 | 写 |
|---|---|---|
| 读 | 兼容 | 兼容 |
| 写 | 兼容 | 不兼容 |
可以看到在COW下,读写操作是可以兼容的,写写操作仍然是无法兼容的
Undo Log
传统的事务支持显示的提交/回滚操作,提交操作容易理解,回滚操作与Mysql的undo log段息息相关,undo log在mysql中通常情况下是逻辑日志,根据每行进行记录,下述展示常见的undo log流程
- 针对select ,不产生undo log,select操作不会对数据产生变更
- 针对insert,产生的undo log 使用delete语句做变更
- 针对update,产生的undo log 用逆向的update语句做变更
- 针对delete,产生的undo log用insert语句做变更
可以看到,针对上述三种修改类型的操作,undo log均会记录行数据的上一个版本,位于undo log中的数据通常称之为快照(历史版本)数据,
实际上undo log除了用作rollback外,另外一个重要的使用场景就是MVCC
MVCC
MVCC(Multi-Version Concurrency Control)的全称是是多版本并发控制,在Innodb的实现中主要是为了提高数据库的并发处理性能,用更好的方式去处理读写冲突,采用非阻塞的方式做到并发读
MVCC情况下的读写兼容类型可以参见:
| 操作类型 | 读 | 写 |
|---|---|---|
| 读 | 兼容 | 兼容 |
| 写 | 兼容 | 不兼容 |
可以看到在MVCC下,读写操作是可以兼容的,写写操作仍然是无法兼容的,这点与前述的COW情况一样,在介绍完Copy on write技术以及undo log后,下面来看innodb的MVCC具体流程。
默认情况下innodb的MVCC机制仅工作在读提交与可重复读这两种隔离级别下,读未提交/串行读的相关语义均不同程度的无法适用于MVCC
- 读未提交每次读取均是读取数据的最新版本,不存在读取历史版本这么一说
- 串行读要求读写操作互斥,亦即多个事务对于同一行的操作读写是不兼容的,需要阻塞等待
MVCC情况下的读操作分两种
- 一致性非锁定读,Mysql默认的读类型,常见的select * from table 即是此类型,通常又称之为快照读
- 一致性锁定读,需要对select操作添加额外的锁来实现,通常亦称之为当前读,锁定读可以继续细分为如下场景
- 共享锁定模式(读锁) : select * from table where id = xx lock in share mode;
- 独占锁定模式(写锁) : select * from table where id = xx for update;
RC隔离级别下的MVCC示例
| step | Tx | Session1 | Tx | Session2 |
|---|---|---|---|---|
| 1 | tx1 | begin; | tx2 | begin; |
| 2 | tx1 | update account set balance = balance-1,update_time = now() where balance>0 and id = 1; | tx2 | |
| 3 | tx1 | tx2 | select id,balance,username from account where id = 1; | |
| 4 | tx1 | commit; | tx2 | |
| 5 | tx2 | select id,balance,username from account where id = 1; | ||
| 6 | tx2 | commit; |
对于RC,session2 两次读的数据输出如下:
-
step3 session2 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 10 | alice | +----+---------+----------+ -
step5 session2 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 9 | alice | +----+---------+----------+
MVCC流程大致如下:
- session1 step2 tx1 update语句做变更,产生undo log数据,记录数据的上一个版本数据,亦即balance=10
- session2 step3 tx2 select读取快照数据,此时快照的版本数据即是step2中update操作生成的快照数据
- session1 step4 tx1 commit数据,最新版本的数据被覆写,这个操作类似于前述的COW的
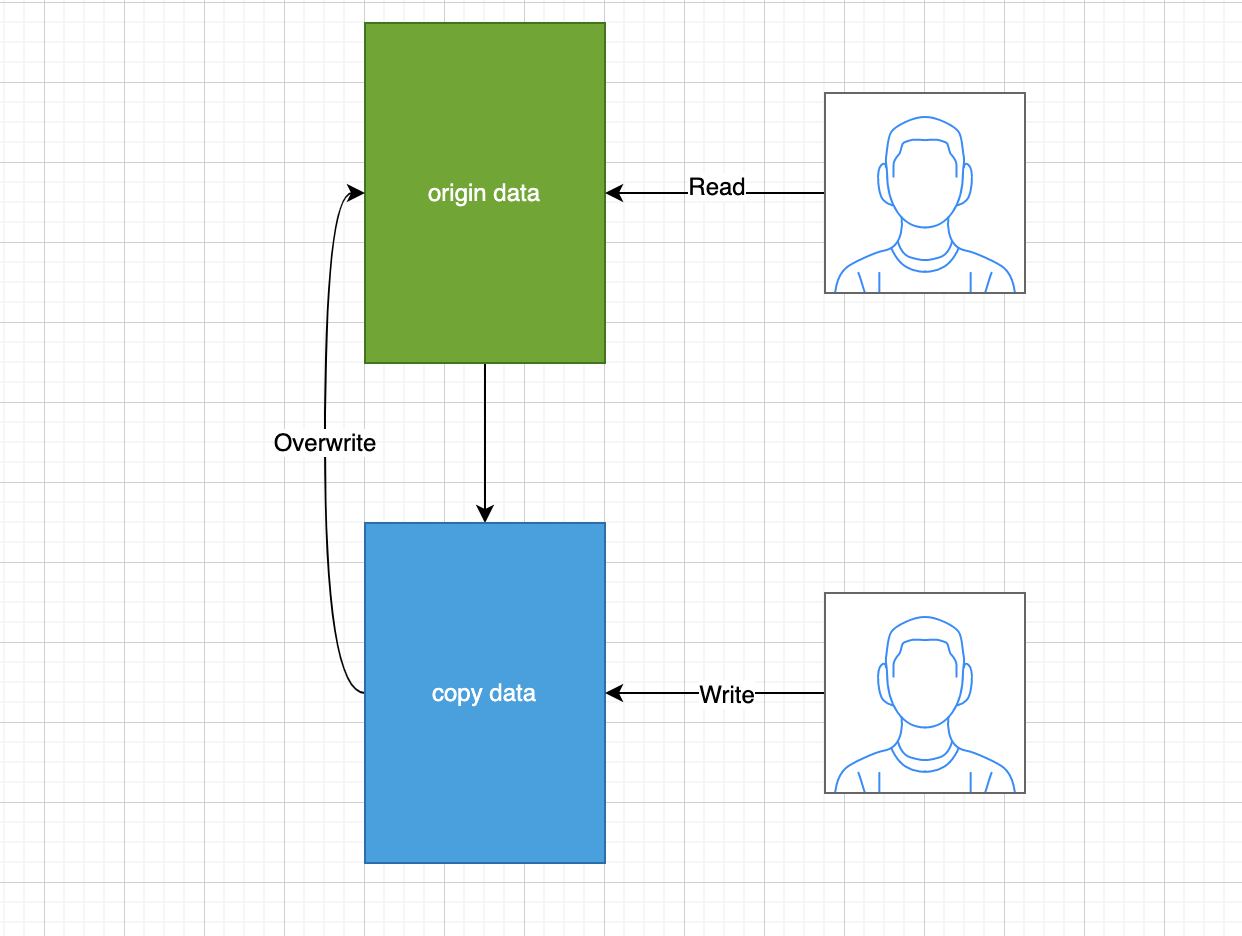
读提交场景下,快照读每次读取的都是最新提交的数据,下面用前述的COW视角来分析此操作
- 针对session1 step2执行了update语句,但是并没有commit,数据修改在copy data的基础上做了修改.
- 针对session2 step3执行了select操作,读取的是原始的origin data文件,此时balance=10
- 针对session1 step4执行了commit操作,类比于cow的overwrite,覆盖原文件
- 针对session2 step5执行了select操作,由于origin data已被session1 step4覆盖,此时读取的数据内容balance=9
RR隔离级别下的MVCC
示例1:
| step | Tx | Session1 | Tx | Session2 |
|---|---|---|---|---|
| 1 | tx1 | begin; | tx2 | begin; |
| 2 | tx1 | update account set balance = balance-1,update_time = now() where balance>0 and id = 1; | tx2 | |
| 3 | tx1 | tx2 | select id,balance,username from account where id = 1; | |
| 4 | tx1 | commit; | tx2 | |
| 5 | tx2 | select id,balance,username from account where id =1; | ||
| 6 | tx2 | commit; |
对于RC,session2 两次读的数据输出如下:
-
step3 session2 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 10 | alice | +----+---------+----------+ -
step5 session2 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 10 | alice | +----+---------+----------+
RR隔离级别要求同一个事务中,对于同一条SQL语句,两次读取的内容需要一致而不论tx1是否提交,这点也是RR与RC读取数据方面一个最大的区别
下面来看一个稍微复杂一点的例子
示例2:
| step | Tx | Session1 | Tx | Session2 | Tx | Session3 |
|---|---|---|---|---|---|---|
| 1 | tx1 | begin; | tx2 | begin; | tx3 | begin; |
| 2 | tx1 | update account set balance = balance-1,update_time = now() where balance>0 and id = 1; | tx3 | select id,balance,username from account where id = 1; | ||
| 3 | tx1 | tx3 | update account set balance = balance-1,update_time = now() where balance>0 and id = 1; -- maybee waiting unitl session1 tx1 commit | |||
| 4 | tx1 | commit; | -- tx3 will be successful when waiting not timeout | |||
| 5 | tx2 | select id,balance,username from account where id = 1; | tx3 | select id,balance,username from account where id = 1; | ||
| 6 | tx3 | commit; | ||||
| 7 | tx2 | select * from account where id =1; | ||||
| 8 | tx2 | commit; |
session 1,2,3按顺序开启
-
step2 session3 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 10 | alice | +----+---------+----------+ -
step5 session2 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 9 | alice | +----+---------+----------+ -
step5 session3 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 8 | alice | +----+---------+----------+ -
step7 session2 输出:
+----+---------+----------+ | id | balance | username | +----+---------+----------+ | 1 | 9 | alice | +----+---------+----------+
对比上述结果可以发现:
- session2 tx2在tx1提交后/session3 tx3提交前开始读取数据
- session3 tx3则是在tx1提交更新前开始读取数据
结果是session2 tx2读取到了session1 tx1的数据,并未读取到tx3更新后的数据(因为tx3未提交),网络上大部分说法是可重复读在事务开始的时候读取的内容就不会变(依据是递增的事物版本号),私以为这个不是特别准确(至少在我当前实验的5.7.36场景不是特别准确,老的版本未经验证),细想下,session2场景,事务都还没开始读取数据,单纯依据事物版本号规则限定了读取的数据范围,某种程度上过于武断
Read View
Read View就是事务进行快照读操作的时候生成的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID,主要是用来做可见性判断的, 即当我们某个事务执行快照读的时候,对该记录创建一个Read View读视图,把它比作条件用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据
Read View遵循的可见性算法可以大致如下:
| 视图 | 操作 | 可见性 |
|---|---|---|
| 当前Read View | 当前事务提交的修改 | 是 |
| 当前Read View | 其他事物未提交的修改 | 否 |
| 当前Read View | 其他事物提交的修改早于当前Read View创建 | 是 |
| 当前Read View | 其他事物提交的修改玩于当前Read View创建 | 否 |
从事物视图的角度去看MVCC的特性,RC、RR不同的隔离级别下Read View创建的时机
- RC隔离级别下,每次快照读,均会基于已提交的数据创建一份新的Read View
- RR隔离级别下,每次快照读,基于事物启动前已经提交的数据创建一份Read View,后续不会在创建新的Read View
- 写操作冲突(RR下的MVCC示例2中的step3 session3 tx3存在写冲突)在默认锁等待不超时的情况下,会强制读取最新已提交的数据(参见前述COW部分写写冲突中的冲突处理示例),从最终数据一致性的角度去看,写写操作是无法兼容的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号