
Hash简介以及Java HashCode的用途
Hash简介以及Java HashCode的用途
Hash俗称散列,在不同的语言中有不同的别名,学过数据结构的同学对此应该不陌生,最简单的hash算法取模如下
public int hashAlg(int origin){
return origin % 10;
}
将输入的参数对一个特定的数取模,得到一个特征值,得到的那个值即为通常意义上的散列值(hashCode),
相较于传统的通过key查找数据,散列表/hash表查找数据的方式通常需要将key进行一定的运算,得到hash值,然后用hash值进行定位查找数据,
通常意义上的散列算法的时间复杂度为O(1),这也是为什么散列如此常见与流行的一个原因
众所周知,Java的Object类是所有的类型的基类,Object中的方法列表如下:
public Object() {}
public final native Class<?> getClass();
public native int hashCode();
public boolean equals(Object obj) {
return (this == obj);
}
protected native Object clone() throws CloneNotSupportedException;
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
public final native void notify();
public final native void notifyAll();
public final void wait() throws InterruptedException {
wait(0L);
}
public final native void wait(long timeoutMillis) throws InterruptedException;
public final void wait(long timeoutMillis, int nanos) throws InterruptedException {
if (timeoutMillis < 0) {
throw new IllegalArgumentException("timeoutMillis value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos > 0) {
timeoutMillis++;
}
wait(timeoutMillis);
}
protected void finalize() throws Throwable { }
可以看到,里面的大部分方法均为native方法,非native的方法除去equals方法,均为直接或者间接的调用了native的方法,默认的toString方法的实现也用到了hashCode方法,
本章的主角咋们来说说equals与hashCode这两个方法
一个老生常谈的问题
大家在初学Java这门编程语言的时候,经常被问到的一个问题就是equals与==在比较对象时候有什么异同,String对象的equals与==之间的区别,
进一步的知识点可能会被问到Byte这类冷门点的话题,诸如以下代码
String abc = "abc";
String abcObj = new String("abc");
System.out.println(abc == "abc");
System.out.println(abc == abcObj);
众所周知,Java并不支持操作符重载,关于==比较的永远是两个对象的地址,想要实现C++中的操作符重载的效果,需要自己编码(编写方法)实现对应的功能,equals方法为Object的方法,
默认的equals方法比较的是两个对象的内存地址,equals方法可以被子类重写,对应的hashCode也可以被重写,事实上这俩要重写的话通常是需要成对进行重写
那么,hashCode与内存地址有什么关系,事实上在现今JDK版本(JDK8往上)这俩并没有实质性的关系,可以认为是两个完全不同的东西,
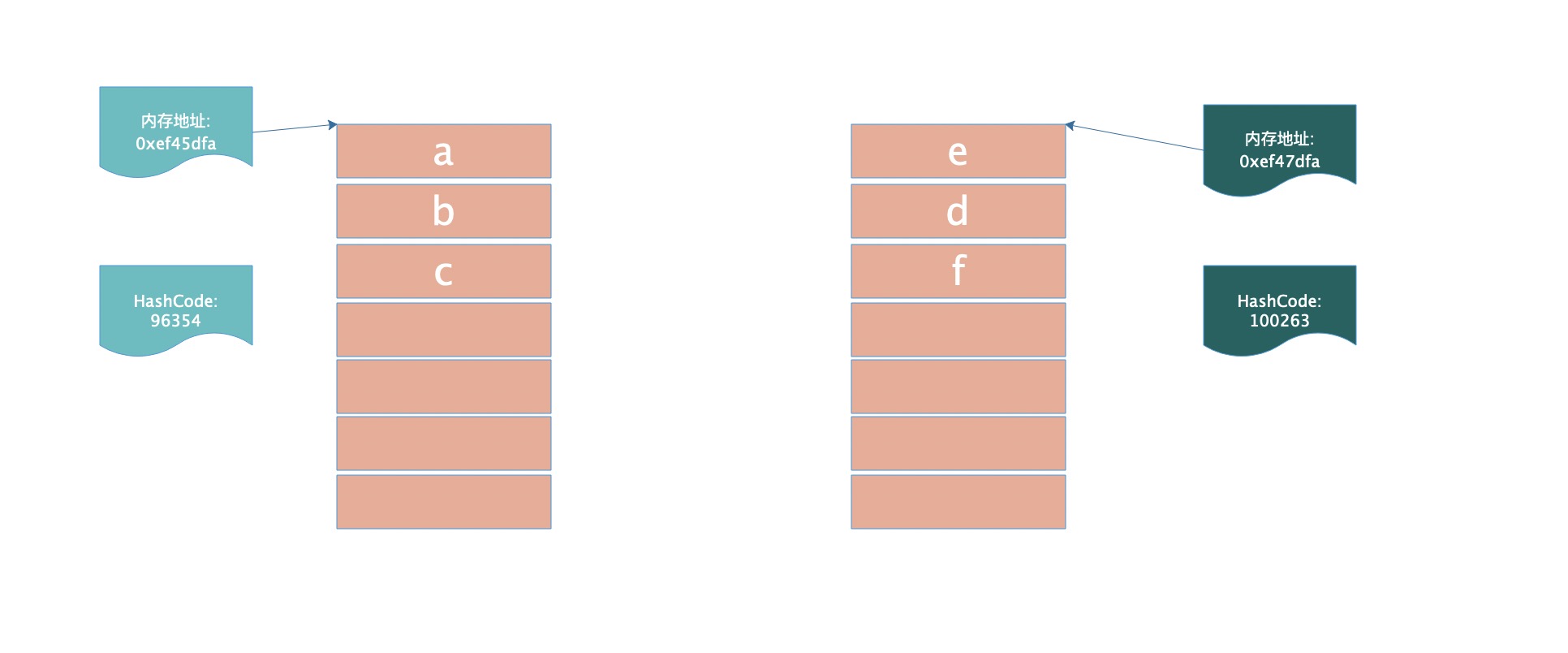
-
内存地址在程序的进程地址空间中是唯一的,内存由系统按需分配,故内存地址的值通常是不可预知的
-
默认的
hashCode实现由JVM底层的Native方法实现,感兴趣的同学可以参见OpenJdk中关于hashCode实现的部分,对应的代码仓库如下
https://github.com/openjdk/jdk
对应的实现代码如下(可能需要切换分支,下述代码在jdk11的系列分支是存在的,文件名为synchronizer.cpp):
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0;
if (hashCode == 0) {
// This form uses global Park-Miller RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random();
} else if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom;
} else if (hashCode == 2) {
value = 1; // for sensitivity testing
} else if (hashCode == 3) {
value = ++GVars.hcSequence;
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj);
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = Self->_hashStateX;
t ^= (t << 11);
Self->_hashStateX = Self->_hashStateY;
Self->_hashStateY = Self->_hashStateZ;
Self->_hashStateZ = Self->_hashStateW;
unsigned v = Self->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
Self->_hashStateW = v;
value = v;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD;
assert(value != markOopDesc::no_hash, "invariant");
TEVENT(hashCode: GENERATE);
return value;
}
可以看到,native的实现总共有6种,从上往下的类型编号分别为0-5,依次排序,
- 0:调用os::random() 生成hashCode,亦即使用一个随机值做hashCode
- 1:内存地址做移位操作,然后与stwRandom(随机数)做异或操作
- 2:固定值1
- 3:自增序列
- 4:使用对象的内存地址
- 5:当前线程中的四个数字(实际上是一个随机数+三个确定值)运用xorshift随机数算法得到的一个随机数
默认的实现为5,亦即上述列表中的最后一个,从注释中也可以看到此算法作者的本意在将来的版本中会成为默认的hashCode实现,实际上由于这部分代码提交历史比较久了,此实现现在已经成为了默认的实现,对于上述规则中1和4,hashCode的计算确实与内存地址有一定的关系,早期版本的JDK实现是否采用此实现暂未考究,也不在系列讨论的范畴中
thread.cpp中关于线程threadState x y z w的四个值的初始化如下:
// thread-specific hashCode stream generator state - Marsaglia shift-xor form
_hashStateX = os::random();
_hashStateY = 842502087;
_hashStateZ = 0x8767; // (int)(3579807591LL & 0xffff) ;
_hashStateW = 273326509;
可以看到上述值除开x外,y z w三个值均为固定值(通常又称之为MagicNumber),下述代码为测试代码,可以测试默认的hashCode实现
public static void main(String[] args) throws Exception {
Object mainHashObj = new Object();
String info = String.format("toString:%s,hex:%s,hashCode:%s", mainHashObj, Integer.toHexString(mainHashObj.hashCode()), mainHashObj.hashCode());
System.out.println(info);
}
注意,编译运行上述代码需要加上jvm参数 -XX:+UnlockExperimentalVMOptions -XX:hashCode=2 参数,不然会使用jdk默认的hashCode算法实现,下面是这俩参数的解释:
- UnlockExperimentalVMOptions 解锁专家模式
- hashCode=2 配置那种hash算法为默认的,此处的2即为上述列表中的0-5,具体含义参见上述解释,不在赘述
可以手动修改hashCode的值,重复运行上述代码,观察默认的hashCode值的变化情况从而验证

 浙公网安备 33010602011771号
浙公网安备 33010602011771号