

框架简答题汇总
框架简答题汇总
1. ThreadLocal的原理
2. 创建线程有几种方式
https://www.cnblogs.com/devour-zuan-blog/p/16520591.html
3. 什么是守护线程?Redis守护线程如何开启?
https://www.cnblogs.com/devour-zuan-blog/p/16527778.html
4. Hashmap 的底层原理
5. 谈一下你对 mybatis 缓存机制的理解?
Mybatis里面设计了二级缓存来提升数据的检索效率,避免每次数据的访问都需要去查询数据库。
- 一级缓存,是SqlSession级别的缓存,也叫本地缓存,因为每个用户在执行查询的时候都需要使用SqlSession来执行,为了避免每次都去查数据库,Mybatis把查询出来的数据保存到SqlSession的本地缓存中,后续的SQL如果命中缓存,就可以直接从本地缓存读取了。
- 如果想要实现跨SqlSession级别的缓存?那么一级缓存就无法实现了,因此在Mybatis里面引入了二级缓存,就是当多个用户在查询数据的时候,只有有任何一个SqlSession拿到了数据就会放入到二级缓存里面,其他的SqlSession就可以从二级缓存加载数据。
6. Spring 的事务传播行为
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何运行。
Spring在TransactionDefinition接口中规定了7种类型的事务传播行为。事务传播行为是Spring框架独有的事务增强特性。这是Spring为我们提供的强大的工具箱,使用事务传播行为可以为我们的开发工作提供许多便利。
7种事务传播行为如下:
-
PROPAGATION_REQUIRED
如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,这是最常见的选择,也是Spring默认的事务传播行为。
-
PROPAGATION_SUPPORTS
支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
-
PROPAGATION_MANDATORY
支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
-
PROPAGATION_REQUIRES_NEW
创建新事务,无论当前存不存在事务,都创建新事务。
-
PROPAGATION_NOT_SUPPORTED
以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
-
PROPAGATION_NEVER
以非事务方式执行,如果当前存在事务,则抛出异常
-
PROPAGATION_NESTED
如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
7. Spring 中的事务隔离级别
- ISOLATION_DEFAULT: 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与JDBC的隔离级别相对应- ISOLATION_READ_UNCOMMITTED: 这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
这种隔离级别会产生脏读,不可重复读和幻像读。- ISOLATION_READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
- ISOLATION_REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。- ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
除了防止脏读,不可重复读外,还避免了幻像读。
什么是脏数据,脏读,不可重复读,幻觉读?
- 脏读: 指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据, 那么另外一个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
- 不可重复读: 指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。 那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
- 幻觉读: 指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
8. 在 SpringMVC 中拦截器的使用步骤是什么样的?
springmvc四大组件 :前端控制器 处理映射器 处理适配器 视图解析器
- DispatcherServlet:前端控制器
- HandlerMapping:处理器映射器 (目的就是根据路径找到对应的处理器)
- Handler:处理器 (就是对应的controller类中的方法)
- HandlAdapter:处理器适配器(adpter适配器 handl是处理器的意思)去执行controller类中的方法
- View Resolver:视图解析器 (resolver是解析器)
- View:视图

什么是拦截器
- 拦截器是SpringMVC中的一样(是属于springmvc框架提供的),需要实现HanderInterceptor接口
- 拦截器和过滤器类似,功能方向侧重点不同。过滤器是用来过滤请求参数,设置编码、字符集等工作。拦截器是拦截用户请求,对请求做判断处理的。
- 拦截器是全局的,可以对多个Controller做拦截。一个项目中可以有0个或多个拦截器,他们在一起拦截用户的请求。拦截器常用在:用户登陆处理、权限检查、记录日志。
拦截器和过滤器的区别:
- 过滤器是 servlet 规范中的一部分,任何 java web 工程都可以使用。拦截器是 SpringMVC 框架自己的,只有使用了SpringMVC框架的工程才能用。
- 过滤器在web.xml中的 url-pattern 标签中配置了/*之后,可以对所有要访问的资源拦截。拦截器它是只会拦截访问的控制器方法,如果访问的是 jsp,html,css,image 或者js是不会进行拦截的。它也是 AOP 思想的具体应用。
- 我们要想自定义拦截器, 要求必须实现:HandlerInterceptor 接口。
自定义拦截器的步骤(拦截器的实现步骤)
-
配置 springmvc配置文件
springMVC配置文件中注册拦截器 目的就是让框架知道拦截器的存在
<!--关于拦截器的配置--> <mvc:interceptors> <mvc:interceptor> <!--/** 包括路径及其子路径--> <!--/admin/* 拦截的是/admin/add等等这种 , /admin/add/user不会被拦截- -> <!--/admin/** 拦截的是/admin/下的所有--> <mvc:mapping path="/**"/> <!--bean配置的就是拦截器--> <bean class="com.devour.interceptor.MyInterceptor"/> </mvc:interceptor> </mvc:interceptors>
-
编写拦截器
编写一个普通类实现 HandlerInterceptor 接口
要注意的是,在高版本的Spring框架中,HanderInterceptor接口的三个方法都是default的声明,需要使用哪个进行重写就行了。但在Spring低版本中,这三个方法并不是default声明。
public class MyInterceptor implements HandlerInterceptor { //在请求处理的方法之前执行 //如果返回true执行下一个拦截器 //如果返回false就不执行下一个拦截器 public boolean preHandle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o) throws Exception { System.out.println("------------处理前------------"); return true; } //在请求处理方法执行之后执行 public void postHandle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, ModelAndView modelAndView) throws Exception { System.out.println("------------处理后------------"); } //在dispatcherServlet处理后执行,做清理工作. public void afterCompletion(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, Exception e) throws Exception { System.out.println("------------清理------------"); } }
普通拦截器执行的时间
- 在请求处理之前 也就是controller类中的方法 执行之前先被拦截一次 (执行prehandle)
- 在控制器方法执行之后也会执行拦截器(相当于走这个postHanlde()方法)
- 在请求处理完成后也会执行拦截器

多个拦截器的执行顺序
连接器链就是两个以及两个以上的连接器组成 才叫连接器链
谈到拦截器,还要向大家提一个词——拦截器链(Interceptor Chain)。拦截器链就是将拦截器按一定的顺序联结成一条链。在访问被拦截的方法或字段时,拦截器链中的拦截器就会按其之前定义的顺序被调用。

那么一个项目中有多个拦截器那么那个拦截器先执行那个拦截器后执行
取决于 你的springMVC配置文件中注册拦截器 目的就是让框架知道拦截器的存在
Springmvc配置文件中的拦截器书写的位置 那个位置考前那个拦截先执行
9. Zookeeper 的应用场景
- 数据发布订阅
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master选举
- 分布式锁
- 分布式队列
10. 描述一下zookeeper的集群选举机制
Master选举: 即在集群的所有机器中选出一台作为master, 利用zookeeper的强一致性, 即zookeeper将会保证客户端无法重复创建一个已经存在的数据节点, 来保证高并发下节点的创建能保证全局一致性.Master动态选举的大致过程如下, 客户端集群在zookeeper上指定节点下创建临时节点, 在这个过程中, 只有一个客户端能创建成功, 那么这个客户端所在的机器就成为了Master.
同时, 其他没有在zookeeper上创建成功的客户端会注册一个子节点变更的watcher, 用于监控当前master是否存活, 一旦发现master挂了, 那么其余的客户端重新进行master选举.
11. zookeeper集群当中的角色有哪些,概述角色作用
Zookeeper对外提供一个类似于文件系统的层次化的数据存储服务,为了保证整个Zookeeper集群的容错性和高性能,每一个Zookeeper集群都是由多台服务器节点(Server)组成,这些节点通过复制保证各个服务器节点之间的数据一致。只要这些服务器节点过半数可用,那么整个Zookeeper集群就可用。下面我们来学习Zookeeper的集群架构,如图所示。
从图中可以看出,Zookeeper集群是一个主从集群,它一般是由一个Leader(领导者)和多个Follower(跟随者)组成。此外,针对访问量比较大的Zookeeper集群,还可新增Observer(观察者)。Zookeeper集群中的三种角色各司其职,共同完成分布式协调服务。下面我们针对Zookeeper集群中的三种角色进行简单介绍。
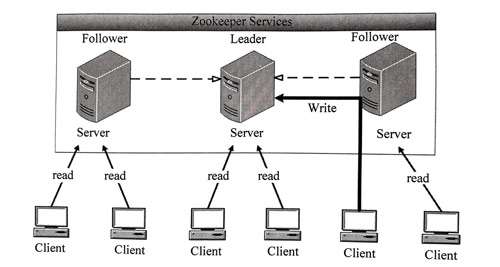
1.Leader
它是Zookeeper集群工作的核心,也是事务性请求(写操作)的唯一调度和处理者,它保证集群事务处理的顺序性,同时负责进行投票的发起和决议,以及更新系统状态。
2.Follower
它负责处理客户端的非事务(读操作)请求,如果接收到客户端发来的事务性请求,则会转发给Leader,让Leader进行处理,同时还负责在Leader选举过程中参与投票。
3.Observer
它负责观察Zookeeper集群的最新状态的变化,并且将这些状态进行同步。对于非事务性请求可以进行独立处理;对于事务性请求,则会转发给Leader服务器进行处理。它不会参与任何形式的投票,只提供非事务性的服务,通常用于在不影响集群事务处理能力的前提下,提升集群的非事务处理能力(提高集群读的能力,也降低了集群选主的复杂程度)。
12. redis的持久化方式
分析&回答
Redis 持久化的两种方式
RDB:RDB 持久化机制,是对 redis 中的数据执行周期性的持久化。
AOF:AOF 机制对每条写入命令作为日志,以 append-only 的模式写入一个日志文件中,在 redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集。
RDB 优缺点
- RDB 会生成多个数据文件,每个数据文件都代表了某一个时刻中 redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说 Amazon 的 S3 云服务上去,在国内可以是阿里云的 ODPS 分布式存储上,以预定好的备份策略来定期备份 redis 中的数据。
- RDB 对 redis 对外提供的读写服务,影响非常小,可以让 redis 保持高性能,因为 redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
- 相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 redis 进程,更加快速。
- 如果想要在 redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦 redis 进程宕机,那么会丢失最近 5 分钟的数据。
- RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF 优缺点
- AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次fsync操作,最多丢失 1 秒钟的数据。
- AOF 日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
- AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在 rewrite log 的时候,会对其中的指令进行压缩,创建出一份需要恢复数据的最小日志出来。在创建新日志文件的时候,老的日志文件还是照常写入。当新的 merge 后的日志文件 ready 的时候,再交换新老日志文件即可。
- AOF 日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用 flushall 命令清空了所有数据,只要这个时候后台 rewrite 还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条 flushall 命令给删了,然后再将该 AOF 文件放回去,就可以通过恢复机制,自动恢复所有数据。
- 对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大。
- AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒 fsync 一次日志文件,当然,每秒一次 fsync,性能也还是很高的。(如果实时写入,那么 QPS 会大降,redis 性能会大大降低)
- 以前 AOF 发生过 bug,就是通过 AOF 记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF 这种较为复杂的基于命令日志 / merge / 回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF 就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
RDB 和 AOF 到底该如何选择
- 不要仅仅使用 RDB,因为那样会导致你丢失很多数据;
- 也不要仅仅使用 AOF,因为那样有两个问题:第一,你通过 AOF 做冷备,没有 RDB 做冷备来的恢复速度更快;第二,RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备份和恢复机制的 bug;
- redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
13. SpringBoot运行原理剖析?(自动装配原理)
14. redis优缺点
Redis的优点
1.纯内存操作。
2.单线程操作,避免了频繁的上下文切换。
3.采用了非阻塞I/O多路复用机制。
I/O多路复用机制:I/O多路复用就是只有单个线程,通过跟踪每个I/O流的状态,来管理多个I/O流。
Redis的缺点
1. 缓存和数据库双写一致性问题
一致性的问题很常见,因为加入了缓存之后,请求是先从Redis 中查询,如果Redis 中存在数据就不会走数据库了,如果不能保证缓存跟数据库的一致性就会导致请求获取到的数据不是最新的数据。
解决方案:
1、编写删除缓存的接口,在更新数据库的同时,调用删除缓存的接口删除缓存中的数据。这么做会有耦合高以及调用接口失败的情况。
2、消息队列:ActiveMQ,消息通知。
2. 缓存的并发竞争问题
并发竞争,指的是同时有多个子系统去set 同一个key值。
解决方案:
最简单的方式就是准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可。
3. 缓存雪崩问题
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
1.给缓存的失效时间,加上一个随机值,避免集体失效。
2.使用互斥锁,但是该方案吞吐量明显下降了。
3.搭建Redis 集群。
4. 缓存击穿问题
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
1、利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试。
2、采用异步更新策略,无论key 是否取到值,都直接返回,value 值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。
15. 为什么要用 Redis
redis优势:
1,运行在内存,速度快;
2,数据虽在内存,但是提供了持久化的支持,即可以将内存中的数据异步写入到硬盘中,同时不影响继续提供服务;
3,支持数据结构丰富string(字符串),list(链表),set(集合),zset(sorted set - 有序集合))和Hash
16. Redis的启动方式?如何实现
-
前台启动
进入到/usr/local/redis的bin目录下,键入命令启动: ./redis-server
结束redis服务:ctrl+c -
守护线程后台启动
-
从redis解压目录中找到redis.conf文件并拷贝到安装redis/bin目录下
cp /usr/local/softs/redis-6.2.4/redis.conf /usr/local/redis/bin -
开启redis守护线程:修改redis.conf中257行的daemonize改为yes
-
后端启动: ./redis-server redis.conf
-
查看redis进程:ps -aux|grep redis
-
查看进程端口号:netstat -anop|grep 进程id
-
17. Nginx是如何处理一个请求的?
Nginx如何处理一个请求
Nginx首先选定由哪一个虚拟主机来处理请求。让我们从一个简单的配置(其中全部3个虚拟主机都在一个端口*:80上监听)开始:
server { listen 80; server_name example.org www.example.org; ... } server { listen 80; server_name example.net www.example.net; ... } server { listen 80; server_name example.com www.example.com; ... }
在这个配置中,nginx仅仅检查请求的“Host”头以决定该请求应由哪个虚拟主机来处理。如果Host头没有匹配任意一个虚拟主机,或者请求中根本没有包含Host头,那nginx会将请求分发到定义在此端口上的默认虚拟主机。
在以上配置中,第一个被列出的虚拟主机即nginx的默认虚拟主机——这是nginx的默认行为。而且,可以显式地设置某个主机为默认虚拟主机,即在"listen"指令中设置"default_server"参数:
server { listen 80 default_server; server_name example.net www.example.net; ... }
下面让我们来看一个复杂点的配置,在这个配置里,有几个虚拟主机在不同的地址上监听:
server { listen 192.168.1.1:80; server_name example.org www.example.org; ... } server { listen 192.168.1.1:80; server_name example.net www.example.net; ... } server { listen 192.168.1.2:80; server_name example.com www.example.com; ... }
这个配置中,nginx首先测试请求的IP地址和端口是否匹配某个server配置块中的listen指令配置。接着nginx继续测试请求的Host头是否匹配这个server块中的某个server_name的值。如果主机名没有找到,nginx将把这个请求交给默认虚拟主机处理。例如,一个从192.168.1.1:80端口收到的访问www.example.com的请求将被监听192.168.1.1:80端口的默认虚拟主机处理,本例中就是第一个服务器,因为这个端口上没有定义名为www.example.com的虚拟主机。
18. Nginx反向代理、负载均衡概念?如何实现?
1.什么是负载均衡
1.什么是反向代理 反向代理(Reverse Proxy)方式是指以代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给Internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。 2.为什么使用反向代理 a.可以起到保护网站安全的作用,因为任何来自Internet的请求都必须先经过代理服务器。 b.通过缓存静态资源,加速Web请求。 c.实现负载均衡 d.实现动静分离 3.负载均衡 负载均衡(Load Balance)其意思就是分摊到多个操作单元上进行执行,例如Web服务器、FTP服务器、企业关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。负载均衡构建在原有网络结构之上,它提供了一种透明且廉价有效的方法扩展服务器和网络设备的带宽、加强网络数据处理能力、增加吞吐量、提高网络的可用性和灵活性。

2.负载均衡设计思想
1.一台普通服务器的处理能力是有限的,假如能达到每秒几万个到几十万个请求,但却无法在一秒钟内处理上百万个甚至更多的请求。但若能将多台这样的服务器组成一个系统,并通过软件技术将所有请求平均分配给所有服务器,那么这个系统就完全拥有每秒钟处理几百万个甚至更多请求的能力。这就是负载均衡最初的基本设计思想。 2.负载均衡是由多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等价的地位,都可以单独对外提供服务而无须其他服务器的辅助。 3.通过某种负载分担技术,将外部发送来的请求按照某种策略分配到服务器集合的某一台服务器上,而接收到请求的服务器独立地回应客户的请求。 4.负载均衡解决了大量并发访问服务问题,其目的就是用最少的投资获得接近于大型主机的性能。

3.负载均衡策略
nginx的upstream目前支持的5种方式的分配 1、轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。 upstream backserver { server 192.168.0.14; server 192.168.0.15; } 2、指定权重weight 指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。 weight值越大,被访问的概率越大 当所有的服务器weight相等的时候,就是一个特殊的轮询 upstream backserver { server 192.168.0.14 weight=8; server 192.168.0.15 weight=10; } 3、IP绑定 ip_hash 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session数据共享的问题。 但是可能会导致后台某些服务器压力过大,这样就影响了后台服务器的负载均衡的实现 upstream backserver { ip_hash; server 192.168.0.14:88; server 192.168.0.15:80; } 4、least_conn最少连接方式 把请求会转发给请求比较少的服务器,但是这个会导致请求少的服务器压力过大,如果某些请求占用的时间比较长,那负载均衡的效果就比较差。 upstream backserver { least_conn; server 192.168.0.14:88; server 192.168.0.15:80; } 5、url_hash(第三方) 按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。 需要借助第三方系统。 upstream backserver { hash $request_uri; server 192.168.0.14:88; server 192.168.0.15:80; } 6、fair(第三方) 按后端服务器的响应时间来分配请求,响应时间短的优先分配。 需要配置fair模块(nginx默认不支持fair指令) upstream backserver { fair; server 192.168.0.14:88; server 192.168.0.15:80; }
4.负载均衡实现
1.安装配置第一个tomcat ① 上传tomcat到linux,分别拷贝到两个不同文件夹 [root@localhost softs]# mkdir /usr/local/tomcats [root@localhost softs]# mkdir /usr/local/tomcats/tomcat1 [root@localhost softs]# mkdir /usr/local/tomcats/tomcat2 [root@localhost softs]# cp apache-tomcat-9.0.55.tar.gz /usr/local/tomcats/tomcat1 [root@localhost softs]# cp apache-tomcat-9.0.55.tar.gz /usr/local/tomcats/tomcat2 ② 进入/usr/local/tomcats/tomcat1,解压tomcat压缩包 ③ 修改tomcat端口号 以及 port 号 ④ 防火墙中开放端口号,重启防火墙 ⑤ 启动tomcat,访问 2.安装配置第二个tomcat 和第一个tomcat步骤一样,只是设置不同的端口号 3.配置nginx负载均衡 a.修改nginx的配置文件(安装目录的conf目录下):nginx.conf b.轮询 upstream www { server 192.168.67.128:8081; server 192.168.67.128:8082; } c.权重 upstream tomcats { server 192.168.67.128:8081 weight=3; server 192.168.67.128:8082 weight=1; } d.反向代理 location / { root html; index index.html index.htm; proxy_pass http://tomcats; } 注意:upstream和server节点平级 4.启动nginx并访问:http://192.168.67.128/ 两个tomcat会交替显示(修改tomcat1首页index.jsp内容做比较)
nginx.conf
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #gzip on; upstream tomcats { server 192.168.67.128:8081 weight=3; server 192.168.67.128:8082 weight=1; } server { listen 80; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; proxy_pass http://tomcats; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # #location ~ \.php$ { # root html; # fastcgi_pass 127.0.0.1:9000; # fastcgi_index index.php; # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # include fastcgi_params; #} # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # #location ~ /\.ht { # deny all; #} } # another virtual host using mix of IP-, name-, and port-based configuration # #server { # listen 8000; # listen somename:8080; # server_name somename alias another.alias; # location / { # root html; # index index.html index.htm; # } #} # HTTPS server # #server { # listen 443 ssl; # server_name localhost; # ssl_certificate cert.pem; # ssl_certificate_key cert.key; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 5m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # location / { # root html; # index index.html index.htm; # } #} }
19. 什么是单例模式?有几种?写出对用的代码
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
特点:
1、单例类只能有一个实例。(私有成员变量)
2、单例类必须自己创建自己的唯一实例。(私有无参构造)
3、单例类必须给所有其他对象提供这一实例。(公有的方法)使用场景:
1.spring bean实例化
2.数据库连接对象(static代码块)
3.mybatis延迟加载策略
-
懒汉式:(线程不安全)
public class User { //私有成员变量 private static User user; //私有构造 private User(){} //公有访问方法 public static User getUser(){ if (user==null){ user=new User(); } return user; } } 这种方式是最基本的实现方式,这种实现最大的问题就是不支持多线程。因为没有加锁 synchronized,所以严格意义上它并不算单例模式。
这种方式 lazy loading 很明显,不要求线程安全,在多线程不能正常工作。 -
懒汉式:(线程安全)
public class User { //私有成员变量 private static User user; //私有构造 private User(){} //公有访问方法 public static synchronized User getUser(){ if (user==null){ user=new User(); } return user; } } 描述:
这种方式具备很好的 lazy loading,能够在多线程中很好的工作,但是,效率很低,99% 情况下不需要同步。
优点:第一次调用才初始化,避免内存浪费。
缺点:必须加锁 synchronized 才能保证单例,但加锁会影响效率。
-
饿汉式
public class User { //私有成员变量 private static User user=new User(); //私有构造 private User(){} //公有访问方法 public static User getUser(){ return user; } } 描述:
这种方式比较常用,但容易产生垃圾对象。
优点:没有加锁,执行效率会提高。
缺点:类加载时就初始化,浪费内存。
20. 什么是工厂模式?写出一个简单工厂模式代码
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
核心要素:
1.目标接口
2.目标接口的实现类
3.目标对象创建工厂
使用场景:spring入门示例(IOC原理)
//手机接口 public interface Phone { void call();//打电话功能 }
public class HuaWeiPhone implements Phone{ @Override public void call() { System.out.println("使用华为手机打电话"); } }
public class XiaoMiPhone implements Phone{ @Override public void call() { System.out.println("使用小米手机打电话"); } }
/*手机工厂*/ public class PhoneFactory { public Phone getPhone(String name){ if (name.equals("huawei")){ return new HuaWeiPhone(); }else if(name.equals("xiaomi")){ return new XiaoMiPhone(); } return null; } }
21. 什么是代理模式?写出一个静态代理模式代码
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。
核心要素:
1.目标对象和代理对象接口
2.目标对象
3.代理对象
//汽车接口 public interface Car { void run(); }
//目标汽车对象 public class AudiCar implements Car{ @Override public void run() { System.out.println("奥迪汽车运行"); } }
//代理汽车对象 public class CarProxy implements Car{ private AudiCar audiCar; public CarProxy(AudiCar audiCar){ this.audiCar=audiCar; } @Override public void run() { //目标对象方法执行 audiCar.run(); //扩展方法执行 play(); } //代理对象扩展方法 void play(){ System.out.println("加装了音响播放系统"); } }
22. 什么是观察者模式?
当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。观察者模式属于行为型模式。
核心要素:
抽象主题(Subject)角色:
也叫抽象目标类,它提供了一个用于保存观察者对象的聚集类和增加、删除观察者对象的方法,以及通知所有观察者的抽象方法。抽象观察者(Observer)角色:
它是一个抽象类或接口,它包含了一个更新自己的抽象方法,当接到具体主题的更改通知时被调用。具体观察者(Concrete Observer)角色:
实现抽象观察者中定义的抽象方法,以便在得到目标的更改通知时更新自身的状态。
//抽象观察者 public abstract class ObserverParent { public Subject subject;//模板主题 public abstract void update();//状态修改变化方法 }
//模板抽象类 public class Subject { //目标状态值 private int num; //观察者集合 private List<ObserverParent> list=new ArrayList<>(); //绑定观察者方法 public void attach(ObserverParent op){ list.add(op); } //观察者通信方法 public void notifyAllObserver(){ for (ObserverParent op : list) { op.update(); } } public int getNum() { return num; } //改变状态值 public void setNum(int num) { this.num = num; //调用观察者通信方法 notifyAllObserver(); } }
//具体观察者类 public class Observer1 extends ObserverParent{ public Observer1(Subject subject) { this.subject=subject; this.subject.attach(this);//绑定观察者 } @Override public void update() { System.out.println("Observer1检测状态值num是:"+subject.getNum()); } } //具体观察者类 public class Observer2 extends ObserverParent{ public Observer2(Subject subject) { this.subject=subject; this.subject.attach(this);//绑定观察者 } @Override public void update() { System.out.println("Observer2检测状态值num是:"+subject.getNum()); } } //具体观察者类 public class Observer3 extends ObserverParent{ public Observer3(Subject subject) { this.subject=subject; this.subject.attach(this);//绑定观察者 } @Override public void update() { System.out.println("Observer3检测状态值num是:"+subject.getNum()); } }
public static void main( String[] args ) { Subject subject=new Subject(); new Observer1(subject); new Observer2(subject); new Observer3(subject); for (int i =10; i < 15; i++) { System.out.println("---------------------subject改变状态值------------------------"); subject.setNum(i); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } }
23. 线程池的分类?
24. 谈一下 SpringMVC 的执行流程以及各个组件的作用
- 一个请求匹配前端控制器 DispatcherServlet 的请求映射路径(在 web.xml中指定), WEB 容器将该请求转交给 DispatcherServlet 处理
- DispatcherServlet 接收到请求后, 将根据 请求信息 交给 处理器映射器 (HandlerMapping)
- HandlerMapping 根据用户的url请求 查找匹配该url的 Handler,并返回一个执行链
- DispatcherServlet 再请求 处理器适配器(HandlerAdapter) 调用相应的 Handler 进行处理并返回 ModelAndView 给 DispatcherServlet
- DispatcherServlet 将 ModelAndView 请求 ViewReslover(视图解析器)解析,返回具体 View
- DispatcherServlet 对 View 进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet 将页面响应给用户
组件说明:
-
DispatcherServlet:前端控制器
用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,
由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。
-
HandlerMapping:处理器映射器
HandlerMapping负责根据用户请求url找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,
例如:配置文件方式,实现接口方式,注解方式等。
-
Handler:处理器
Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
由于Handler涉及到具体的用户业务请求,所以一般情况需要程序员根据业务需求开发Handler。
-
HandlAdapter:处理器适配器
通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
-
ViewResolver:视图解析器
View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址
再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。
-
View:视图
springmvc框架提供了很多的View视图类型的支持,包括:jstlView、freemarkerView、pdfView等。我们最常用的视图就是jsp。
一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由程序员根据业务需求开发具体的页面。
25. Spring的两大核心是什么?谈一谈你对IOC的理解? 谈一谈你对DI和AOP的理解?
spring
spring是一个轻量级的控制反转(IOC)和面向切面编程的容器(框架)
IOC
不是什么技术,而是一种设计思想。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
对象由spring创建管理和装配
依赖注入
DI:
- 将实例变量传入到一个对象中去
- 是实现控制反转的一种设计模式
AOP
AOP(Aspect-Oriented Programmjng),一般称为⾯向切⾯编程/⾯向⽅⾯编程。 用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时捉高了系统的可维护性。
可用于
权限认证、日志、事务处理等。本质在于:
在不改变原有业务逻辑的情况下增强横切逻辑,横切逻辑代码往往是权限校验代码、⽇志代
码、性能监控代码、事务控制代码等
26. Spring框架中都用到了哪些设计模式?举例说明
-
Spring框架中使用的设计模式:
| 设计模式 | Spring框架 |
|---|---|
| 工厂模式 | BeanFactory ApplicationContext |
| 单例模式 | Spring中的Bean |
| 代理模式 | Spring AOP |
| 模板方法模式 | Spring中以Template结尾的类 |
| 观察者模式 | Spring事件驱动模型 |
| 适配器模式 | Spring AOP中的AdvisorAdapter Spring MVC中的HandlerAdapter |
| 装饰器模式 | Spring中含有Wrapper和含有Decorator的类 |
27. Dubbo的实现原理?(RPC和 SOA)
dubbo是一个分布式服务框架,主要基于rpc原理实现
dubbo作为rpc框架,实现的效果就是调用远程的方法就像在本地调用一样。如何做到呢?就是本地有对远程方法的描述,包括方法名、参数、返回值,在dubbo中是远程和本地使用同样的接口;然后呢,要有对网络通信的封装,要对调用方来说通信细节是完全不可见的,网络通信要做的就是将调用方法的属性通过一定的协议(简单来说就是消息格式)传递到服务端;服务端按照协议解析出调用的信息;执行相应的方法;在将方法的返回值通过协议传递给客户端;客户端再解析;在调用方式上又可以分为同步调用和异步调用;简单来说基本就这个过程
28. synchronized和 Lock有什么区别
1.首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
2.synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
3.synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
4.用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
5.synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
6.Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
29. Mybatis执行流程
参考:https://blog.csdn.net/weixin_35973945/article/details/124300787


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)