


Memory Alignment
Memory alignment翻译过来就是内存对齐。举一个简单的例子,int所占内存空间为4bytes,char为1byte,那么下面这个结构体
struct tMemAlign{
int i;
char c[3];
int k; }
所占的内存空间似乎应该是4+3+4=11bytes。而事实上,在XP sp2,Visual Studio .Net 2005的环境下,使用sizeof操作符获得其所占内存空间为12bytes。编译器的这种行为就叫做内存对齐。
什么是内存对齐
内存对齐是为了CPU存取数据更为有效率。软件对内存的读写是以byte为单位的,看上去CPU在运行软件时对内存的读写也是以byte为单位的。而事实上并非如此,只是我们感觉不到罢了。下图列出了32位的CPU内存读取的方式,可以将其推广到16位和64位:
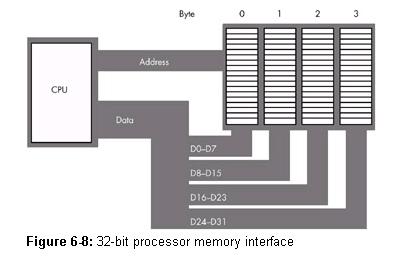
其中Data是数据总线,Address是地址总线,而右上角是内存,一个长方形格子表示1byte。从图中可以看出,32位CPU存取数据是以4bytes(32bits)为单位(16位以2bytes,64位以8bytes),而不是1byte。也就是说,若是要读入1byte的char数据,CPU也要读入4bytes,然后选出需要的数据。问题就来了,若是一个int型的数据的起始位置为地址1,那么它将延续到地址4。那么CPU要想读入该数据,就必须进行两次内存读取。首先取出地址0-3,然后取出地址4-7,最后提取并组合出正确的int数据,舍弃无关的数据。这无疑降低了CPU运行的效率。于是,让小于等于4bytes的数据(32位CPU中)位于一组4bytes中,从而能够让CPU对其进行一次读取的方法就是memory alignment。实际上,编译器采取的办法就是padding。比如上面的例子,因为int型数据k若是紧跟着char型数据后存储,那么k就将位于两组4bytes中,于是编译器在padding了最后一个char数据后面紧跟的字节,让k从下一组4bytes的起始位置处开始存储。这就是memory alignment的实现。具体的来说,在Windows下当数据所存储的内存位置是数据字节数的整数倍时,就说该数据是内存对齐的。可以想象,这实际上就是保证了数据只位于一组4bytes中。例如,WORD值应该总是从被2除尽的地址开始,而DWORD值应该总是从被4除尽的地址开始。
如何进行内存对齐
在Windows平台下,cl.exe的对齐选项有/Zp[1|2|4|8|16], /Zp1表示以1字节边界对齐,相应的,/Zpn表示以n字节边界对齐。n字节边界对齐的意思是说,一个成员的地址必须安排在成员的尺寸的整数倍地址上或者是n的整数倍地址上,取它们中的最小值。也就是:min ( sizeof(member), n)实际上,1字节边界对齐也就表示了结构成员之间没有padding。注意,/Zpn选项是应用于整个工程的,影响所有的参与编译的结构。而在VC中,动态更改内存对齐方式的办法是使用
#pragma pack(n)
其中,n指示编译器按照n字节边界对齐。若n不存在,则表示取消自定义字节对齐方式。
