最小二乘法 及 梯度下降法 运行结果对比(Python版)
上周在实验室里师姐说了这么一个问题,对于线性回归问题,最小二乘法和梯度下降方法所求得的权重值是一致的,对此我颇有不同观点。如果说这两个解决问题的方法的等价性的确可以根据数学公式来证明,但是很明显的这个说法是否真正的成立其实很有其它的一些考虑因素在里面,以下给出我个人的一些观点:
1. 首先,在讨论最小二乘法和梯度下降对某数据集进行线性拟合的结果是否相同的问题之前,我们应该需要确保该数据集合的确符合线性模型,如果不符合那么得出的结果将会是非常有意思的,
该种情况在之前的博客中已有介绍,下面给出网址:http://www.cnblogs.com/devilmaycry812839668/p/7704729.html
2. 再者, 在讨论二者结果是否相同的问题之前如果对梯度下降法做过实际编码的人员一定知道这么一个东西,那就是步长,即每次对权重进行修正时的权重配比。虽然对于凸优化问题对初始点不敏感,但是步长的设置却会影响最终收敛时权重的精度,甚至造成权值震荡的想象发生,以下给出具体实验代码及结果:
最小二乘法:
#!/usr/bin/env python #encoding:UTF-8 import numpy as np import matplotlib.pyplot as plt np.random.seed(0) N=10 X=np.linspace(-3, 3, N) Z=-5.0+X+np.random.random(N) P=np.ones((N, 1)) P=np.c_[P, X] t=np.linalg.pinv(P) w=np.dot(t, Z) print "拟合后的权重:" print w A=np.dot(P, w)-Z print "拟合后的LOSTFUNCTION值:" print np.dot(A, A)/2
结果:
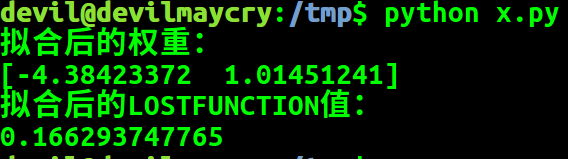
梯度下降法:
#!/usr/bin/env python #encoding:UTF-8 import numpy as np import matplotlib.pyplot as plt np.random.seed(0) N=10 X=np.linspace(-3, 3, N) Z=-5+X+np.random.random(N) P=np.ones((N, 1)) P=np.c_[P, X] alafa=0.001 def fun(): W=np.random.random(2) for _ in xrange(1000000000): A=(np.dot(P, W)-Z) W0=alafa*( np.sum(A) ) W1=alafa*( np.dot(A, X) ) if abs(W0)+abs(W1)<0.000001: break W[0]=W[0]-W0 W[1]=W[1]-W1 return W list_global=[] for _ in xrange(100): list_global.append( fun() ) list_global.sort(key=lambda x:x[0]) for k in list_global: print k
结果:
[-4.38413472 1.01451241] [-4.38413469 1.01451241] [-4.38413469 1.01451241] [-4.38413468 1.01451241] [-4.38413468 1.01451241] [-4.38413464 1.01451241] [-4.38413463 1.01451241] [-4.38413461 1.01451241] [-4.38413461 1.01451241] [-4.3841346 1.01451241] [-4.38413459 1.01451241] [-4.38413458 1.01451241] [-4.38413457 1.01451241] [-4.38413457 1.01451241] [-4.38413457 1.01451241] [-4.38413455 1.01451241] [-4.38413454 1.01451241] [-4.38413451 1.01451241] [-4.38413446 1.01451241] [-4.38413444 1.01451241] [-4.38413444 1.01451241] ...... ...... ......
由梯度下降法可知,由于初始点的不同最终的优化结果稍有差异,但是考虑精度的情况下可以认为所有结果均为一致,此时是支持学姐的说法的。
若改变步长大小,即
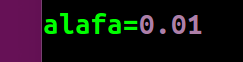
可得结果:
[-4.3842247 1.01451241] [-4.38422468 1.01451241] [-4.38422468 1.01451241] [-4.38422467 1.01451241] [-4.38422465 1.01451241] [-4.38422464 1.01451241] [-4.3842246 1.01451241] [-4.38422459 1.01451241] [-4.38422458 1.01451241] [-4.38422457 1.01451241] [-4.38422455 1.01451241] [-4.38422455 1.01451241] [-4.38422453 1.01451241] [-4.38422452 1.01451241] [-4.38422452 1.01451241] [-4.38422452 1.01451241] [-4.38422451 1.01451241] [-4.3842245 1.01451241] ......... ........ ........
此时,运行结果和上个实验的运行结果稍有不同,可以发现该种差异源于步长大小的设置上,也就是说步长的大小不同导致了最终结果的精确度不同。
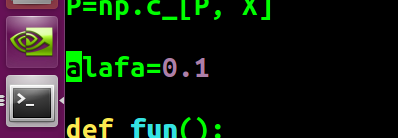
这次,我们再次改变步长大小,此时运行的结果并没有出来,可以说上面的程序在该步长下是无法运行出结果的,下面做下修改:
#!/usr/bin/env python #encoding:UTF-8 import numpy as np import matplotlib.pyplot as plt np.random.seed(0) N=10 X=np.linspace(-3, 3, N) Z=-5+X+np.random.random(N) P=np.ones((N, 1)) P=np.c_[P, X] alafa=0.1 def fun(): W=np.random.random(2) for _ in xrange(100): A=(np.dot(P, W)-Z) W0=alafa*( np.sum(A) ) W1=alafa*( np.dot(A, X) ) W[0]=W[0]-W0 W[1]=W[1]-W1 print W fun()
运行结果,如下:
[-4.38423372 2.30949239] [-4.38423372 -2.43876754] [ -4.38423372 10.22325895] [ -4.38423372 -23.54214502] [ -4.38423372 66.49893222] [ -4.38423372 -173.61060709] [ -4.38423372 466.68149774] [ -4.38423372 -1240.76411513] [ -4.38423372 3312.42418586] [ -4.38423372e+00 -8.82941128e+03] [ -4.38423372e+00 2.35488166e+04] [ -4.38423372e+00 -6.27931245e+04] [ -4.38423372e+00 1.67452052e+05] [ -4.38423372e+00 -4.46535085e+05] [ -4.38423372e+00 1.19076395e+06] [ -4.38423372e+00 -3.17536680e+06] [ -4.38423372e+00 8.46764853e+06] [ -4.38423371e+00 -2.25803924e+07] [ -4.38423372e+00 6.02143834e+07] [ -4.38423371e+00 -1.60571685e+08] [ -4.38423375e+00 4.28191164e+08] [ -4.38423373e+00 -1.14184310e+09] ....... ....... ....... [ -2.14824842e+17 2.17682829e+33] [ 1.31051609e+17 -5.80487543e+33] [ -7.91285594e+17 1.54796678e+34] [ 1.97572602e+18 -4.12791142e+34] [ -3.55829721e+18 1.10077638e+35] [ 1.11990981e+19 -2.93540367e+35] [ -3.30730877e+19 7.82774313e+35] [ 5.54712838e+19 -2.08739817e+36] [ -4.16765364e+20 5.56639512e+36] [ 2.91589608e+20 -1.48437203e+37] [ 2.91589608e+20 3.95832542e+37] [ 5.95842939e+21 -1.05555344e+38] [ -5.37525017e+21 2.81480918e+38] [ 2.48478953e+22 -7.50615783e+38] [ -6.58215412e+22 2.00164209e+39] [ 4.17748787e+23 -5.33771223e+39] [ -7.91177033e+23 1.42338993e+40] [ 1.14310428e+24 -3.79570648e+40] [ -2.72545834e+24 1.01218839e+41] [ 5.01166690e+24 -2.69916905e+41] [ -2.59368341e+25 7.19778413e+41] [ 3.59601679e+25 -1.91940910e+42]
可见,其权重值是发散的,并不断震荡。
再次更改步长,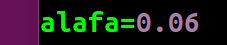
运行结果:
[-2.31385021 1.5972534 ] [-3.55608032 0.31522322] [-4.05297236 1.85365944] [-4.25172917 0.00753598] [-4.3312319 2.22288413] [-4.36303299 -0.43553365] [-4.37575343 2.75456769] [-4.3808416 -1.07355392] [-4.38287687 3.52019201] [-4.38369098 -1.99230311] [-4.38401662 4.62269104] [-4.38414688 -3.31530194] [-4.38419898 6.21028963] [-4.38421982 -5.22042025] [-4.38422816 8.49643161] [-4.38423149 -7.96379062] [ -4.38423283 11.78847605] [ -4.38423336 -11.91424395] [ -4.38423357 16.52902005] [ -4.38423366 -17.60289675] [ -4.38423369 23.35540341] [ -4.38423371 -25.79455679] [ -4.38423371 33.18539545] [ -4.38423372 -37.59054724] [ -4.38423372 47.34058399] [ -4.38423372 -54.57677348] ............ ............ ............ [ -4.38423372e+00 2.61036000e+06] [ -4.38423372e+00 -3.13242977e+06] [ -4.38423372e+00 3.75891795e+06] [ -4.38423372e+00 -4.51069931e+06] [ -4.38423372e+00 5.41284140e+06] [ -4.38423372e+00 -6.49540745e+06] [ -4.38423372e+00 7.79449117e+06] [ -4.38423372e+00 -9.35338718e+06] [ -4.38423372e+00 1.12240668e+07] [ -4.38423372e+00 -1.34688780e+07] [ -4.38423372e+00 1.61626558e+07] [ -4.38423372e+00 -1.93951847e+07] [ -4.38423372e+00 2.32742239e+07] [ -4.38423371e+00 -2.79290665e+07] [ -4.38423372e+00 3.35148820e+07] [ -4.38423371e+00 -4.02178562e+07]
可以,看到该种步长下,常数项权重收敛,X项权重仍然震荡。
由此,可以看出 对于 最小二乘 及 梯度下降 能否得到 相同权重结果 还是蛮有讨论的一个问题。
==============================================================
对于,梯度下降 权重震荡的附加一个解释:
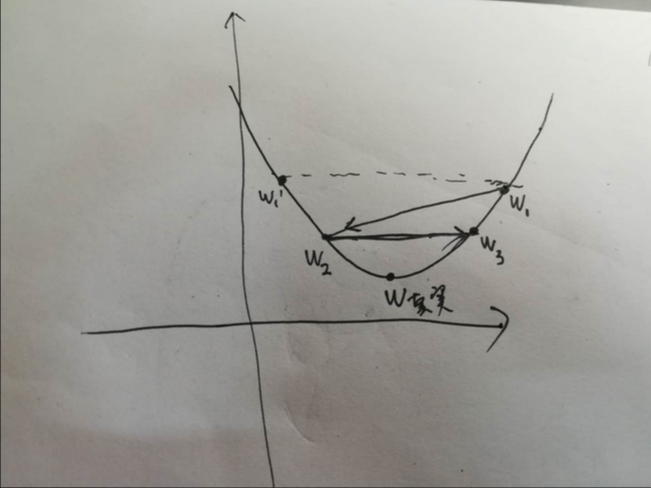
在梯度下降问题中,如上图所示,W为权重的真实值,W1 为梯度下降过程中对真实值的估计,在此之前所有权重的估计值(即,历史估计的值,或者说迭代过程中在对真实值进行逼近的过程中)所取得的所有值均在真实值的一侧, W2为首次估计值越过真实值到达另一侧的权重值, W’ 为W1关于真实值在其另一侧的对称值,如果W2比W’ 更靠近真实值,则下一次的权重估计值 W3 必然比 W1 更逼近真实值。此时,为收敛的。该种情况下说明步长的选择可以使权重收敛。
如果,W2 比 W’ 要远离真实值,则W3 必然比 W1 相比要远离真实值W。此时,权重的估计是发散的。
具体示意图如下: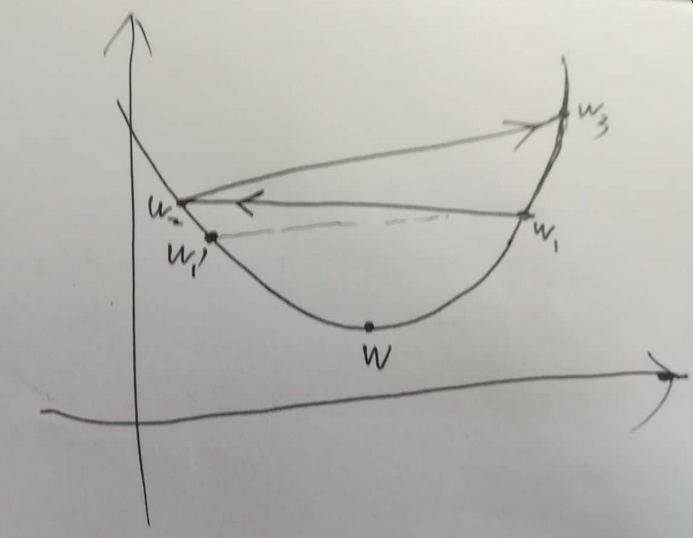
posted on 2017-10-21 16:18 Angry_Panda 阅读(3272) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号