TensorFlow和pytorch中的pin_memory和non_blocking设置是做什么的,又是否有用???
参考:
https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
========================================
因为最早接触CUDA是大学时代,至今已经十多年了,有些东西用习惯了、时间久了就不太care了,最近由于工作原因又搞了会CUDA和深度学习的框架,看到pin_memory和non_blocking这两个参数设置,每次看到都想写些分析的technical report,最近由于疫情窝在家也正好是旧事重提,便有了本post。
====================================================
pin_memory的设置是几乎所有深度学习框架dataloader中的参数,而non_blocking参数主要在pytorch中有发现使用。
其实对cuda编程有些了解的人对这两个参数从字面上就可以理解个大概。
首先说下pin_memory :
相关介绍可以看:https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
上面链接地址中有一个比较形象的图:
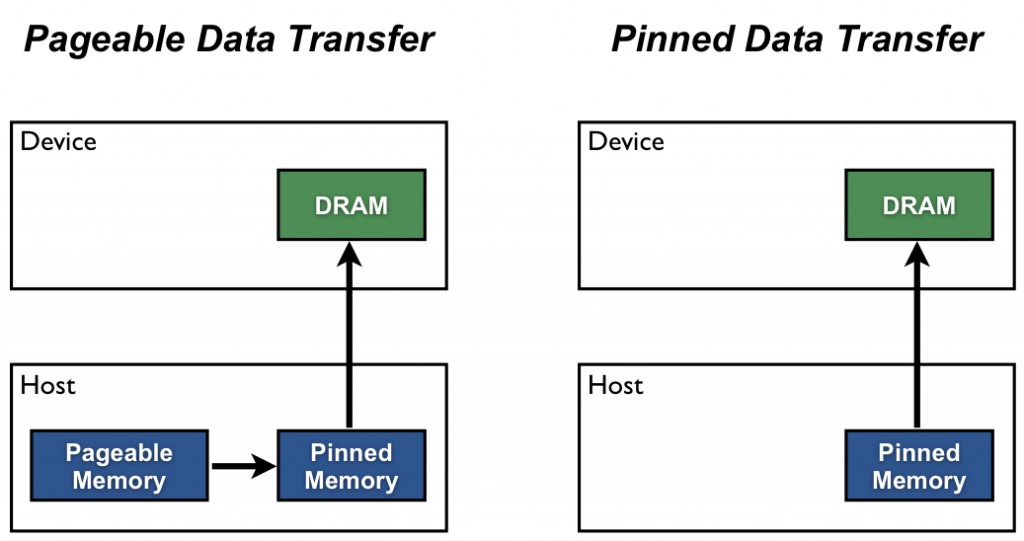
解释一下:
在主机内存中可以把available内存分配为pageable memory和pinned memory两种,pageable memory就是可以页置换的内存。如果了解虚拟内存的人就会知道当计算机available memory空间不够的情况下就会将used memory中的部分内存空间置换到硬盘上,这部分可以被置换的(被保存到硬盘空间以腾出一定的可用物理内存空间)就是pageable memory,与此相对的就是pinned memory内存空间。作为已分配使用的内存,pinned memory是不会被置换到硬盘空间上的,也就是说一旦一段内存空间被分配为pinned memory,那么这段物理内存就会被所申请的应用所独占,而不会被操作系统通过页置换而重新分配给其他应用(进程)。在主机host和GPU(device)之间进行数据传输为块传输方式,也就是说host端的CPU发出传输指令和需要传输的物理内存地址给device,然后device根据收到的指令将host端所指定的物理内存中的地址copy到device中的显存中,而该种传输方式不可以避免的就是host端待传输数据的那段物理内存是需要被本进程所独占的,因此这一段内存空间必须是pinned memory。
在CUDA编程中可以手动的把CPU端准备传输到GPU的那部分host内存空间指定为pinned memory,这样GPU端执行copy时就可以直接从这段host的内存中copy;但是如果没有手动指定待拷贝的host上的物理内存为pinned memory那么这段内存便是pageable memory,那么在这种情况下执行copy就需要CPU上操作向操作系统隐式的申请一段临时的pinned memory,然后CPU将待拷贝的pageable memory中的数据copy到临时申请的pinned memory中然后发送命令给GPU来从这段临时的pinned memory中copy数据。
从上面的copy过程中可以看到,如果不手动在host端指定pinned memory的话,host和device之间的数据拷贝每次都需要创建一个新的临时pinned memory,然后再把pageable memory中的数据拷贝到pinned memory,而在这个过程中pinned memory的申请和pageable memory与pinned memory之间的数据互copy都是较大的时间花费的,因此为了提高CUDA程序的运行效率可以手动将待传输的数据指定为pinned memory。
pinned memory的缺点:
在不考虑编写代码时单独指定的操作花费,那么pinned memory的唯一缺点就是浪费内存,因为一段被指定为pinned memory的物理内存空间是不允许其他应用复用的,只能该申请创建的进程所独占。
pinned memory的时代局限性:
上面分析了,pinned memory的优点是提高异构设备间数据拷贝的效率,缺点是导致host端内存的利用效率降低。但是这些优点和缺点的分析都是根据几十年前的资料所得出的,根据How to Optimize Data Transfers in CUDA C/C++中的数据显示,pinned memory可以极大提高host与device之间数据的拷贝速度,在NVIDIA 4200M型号的GPU上效率表现如下:
代码:


#include <stdio.h> #include <assert.h> // Convenience function for checking CUDA runtime API results // can be wrapped around any runtime API call. No-op in release builds. inline cudaError_t checkCuda(cudaError_t result) { #if defined(DEBUG) || defined(_DEBUG) if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result)); assert(result == cudaSuccess); } #endif return result; } void profileCopies(float *h_a, float *h_b, float *d, unsigned int n, char *desc) { printf("\n%s transfers\n", desc); unsigned int bytes = n * sizeof(float); // events for timing cudaEvent_t startEvent, stopEvent; checkCuda( cudaEventCreate(&startEvent) ); checkCuda( cudaEventCreate(&stopEvent) ); checkCuda( cudaEventRecord(startEvent, 0) ); checkCuda( cudaMemcpy(d, h_a, bytes, cudaMemcpyHostToDevice) ); checkCuda( cudaEventRecord(stopEvent, 0) ); checkCuda( cudaEventSynchronize(stopEvent) ); float time; checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) ); printf(" Host to Device bandwidth (GB/s): %f\n", bytes * 1e-6 / time); checkCuda( cudaEventRecord(startEvent, 0) ); checkCuda( cudaMemcpy(h_b, d, bytes, cudaMemcpyDeviceToHost) ); checkCuda( cudaEventRecord(stopEvent, 0) ); checkCuda( cudaEventSynchronize(stopEvent) ); checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) ); printf(" Device to Host bandwidth (GB/s): %f\n", bytes * 1e-6 / time); for (int i = 0; i < n; ++i) { if (h_a[i] != h_b[i]) { printf("*** %s transfers failed ***\n", desc); break; } } // clean up events checkCuda( cudaEventDestroy(startEvent) ); checkCuda( cudaEventDestroy(stopEvent) ); } int main() { unsigned int nElements = 4*1024*1024; const unsigned int bytes = nElements * sizeof(float); // host arrays float *h_aPageable, *h_bPageable; float *h_aPinned, *h_bPinned; // device array float *d_a; // allocate and initialize h_aPageable = (float*)malloc(bytes); // host pageable h_bPageable = (float*)malloc(bytes); // host pageable checkCuda( cudaMallocHost((void**)&h_aPinned, bytes) ); // host pinned checkCuda( cudaMallocHost((void**)&h_bPinned, bytes) ); // host pinned checkCuda( cudaMalloc((void**)&d_a, bytes) ); // device for (int i = 0; i < nElements; ++i) h_aPageable[i] = i; memcpy(h_aPinned, h_aPageable, bytes); memset(h_bPageable, 0, bytes); memset(h_bPinned, 0, bytes); // output device info and transfer size cudaDeviceProp prop; checkCuda( cudaGetDeviceProperties(&prop, 0) ); printf("\nDevice: %s\n", prop.name); printf("Transfer size (MB): %d\n", bytes / (1024 * 1024)); // perform copies and report bandwidth // profileCopies(h_aPageable, h_bPageable, d_a, nElements, "Pageable"); // profileCopies(h_aPinned, h_bPinned, d_a, nElements, "Pinned"); // char a[] = "Pageable"; char b[] = "Pinned"; // char *a = "Pageable"; // char *b = "Pinned"; profileCopies(h_aPageable, h_bPageable, d_a, nElements, a); profileCopies(h_aPinned, h_bPinned, d_a, nElements, b); printf("n"); // cleanup cudaFree(d_a); cudaFreeHost(h_aPinned); cudaFreeHost(h_bPinned); free(h_aPageable); free(h_bPageable); return 0; }
运行结果:
Device: NVS 4200M
Transfer size (MB):16
Pageable transfers
Host to Device bandwidth (GB/s): 2.308439
Device to Host bandwidth (GB/s): 2.316220
Pinned transfers
Host to Device bandwidth (GB/s): 5.774224
Device to Host bandwidth (GB/s): 5.958834
可以看到设置pinned memory后copy速度提升两倍以上。
正好我大学毕业的时候买的的电脑上的GPU就是4200M的,但是我现在平时用的主机是2070super的显卡,那么我们用2070super显卡来重新测试一下:
显卡:2070super
CPU: 10700k,5.00Ghz
内存:2666Mhz,4代内存
运行结果:
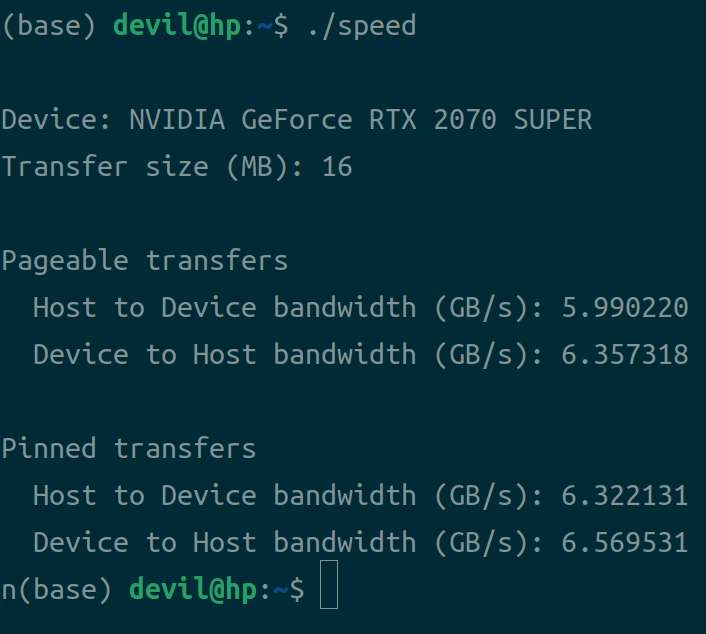
可以看到在今天的一个几年前的比较中端的计算机上运行这个测速程序,锁页内存与非锁页内存在设备间的copy速率已经没有太大差距了,16MB的数据在该硬件平台下的耗时为:
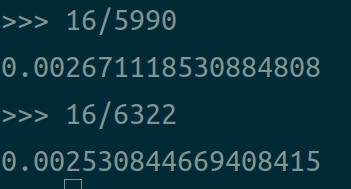
也就是说差距为0.0001秒。
在比较常见的Deep Learning任务中,batch size为32,一秒中10个batch的计算,那么一次计算需要0.1秒,即使是非常小的一次计算也都要0.01秒,这已经是非常极限的用时了,那么使用这个pinned memory与否就等于说一次batch计算用时为0.0101还是0.01,可以看到不使用pinned memory的性能可以是使用的0.01/0.0101=99%,也就是说你不使用pinned memory跑一个普通的代码用是100分钟,但是你使用pinned memory的话用时可以到99分钟。从这里的分析可以知道,如果你运行的代码不是那种特别简单的操作,假设你每次计算的拷贝数据都是16MB,0.0025的时间都是需要的,除非那种计算任务用时和数据拷贝任务用时差距不大的,比如计算任务用时也是0.0025秒,否则使用pinned memory并不会用太显著的性能提升,当然如果你的计算任务比数据copy的用时还小,那么这个任务就基本就是纯粹的数据拷贝任务了,那么即使这种最极端的情况不使用pinned memory依然可以有5990/6332=94.6%的性能。
上面的测试平台是DDR4 3000mhz内存,10700k cpu,ROG Z490-E主板,如果我们用13代CPU,14代CPU,DDR5 4800mhz的设备,那么我想pinned memory和pageable memory的性能将不再有明显的差距。
既然有了上面的数据,我们就可以分析分析这个pinned memory现在还有没有用这个问题了。在计算机硬件设备性能比较差的情况下,比如CPU和内存性能不高的情况下,尤其是对于那种单次计算用时不大的任务,pinned memory确实可以用一定的性能提升,不过对于现在的计算平台来说,尤其是高性能的家用计算机来说(服务器除外,服务器以稳定性为主,因此很多性能指标是远不如家用计算机的),设置不设置这个pinned memory并没有啥感觉。也是说下个人的使用情况,我也是这个领域的从业人员,即使加上身边的同行也有几十人了,不过这些人之中没有一个人用过这个pinned memory,甚至很多对技术不求甚解的人压根就没听说过这个东西的存在。
那么我们就可以说说为什么在主机性能较低的年代,这个pinned memory成为了一个“黑科技”呢。曾经的计算机CPU、内存频率低,设备内和设备间数据拷贝速度都较慢,而且当年的内存很贵,内存容量较小,空间高效利用十分重要,也就是在那种特殊的时代背景下就有了这个黑科技,要不然像今天我个人的家用计算机都128G内存的情况下又有谁回去care使用pinned memory以后被锁定的内存不能被其他应用抢夺复用造成的使用效率下降呢,而且即使是用我现在几年前的中端家用计算机的平台pinned memory的性能提升也没什么太多诱惑力了。
上面说了那么多,是不是说在今时今日pinned memory就没有必要手动设置了呢,其实也不竟然,因为你不可能总在高性能的计算平台上运行程序,比如我现在所在的实验室就是大家共用一个服务器集群,那种所谓的工业级的深度学习服务器集群,动不动就是Xeon Gold平台,不是V100就是泰坦,要么就是3090显卡,很多人或许会以为这样的计算平台性能很高,其实这个答案是错的。尤其是深度学习服务器它可以保证多人使用情况下和单人使用达到性能相差不大的表现,但是它对他人使用的性能表现并没有家用计算机平台那么强劲,就比如我上个月刚接收的一台几十万的服务器来说,他的CPU正常多人运行的情况下基本保持频率为3.5Ghz,ddr4的内存,而现在的13900k CPU的频率可以达到5.8Ghz,甚至是6.0Ghz以上,再加上CPU构建设计的升级,可以说在不运行多线程并行的任务下家用13900k的CPU性能单核心可以有服务器多人使用时单核性能的两倍,而现在的服务器内存最好的也基本都是DDR4 2666Mhz的,而现在的家用内存DDR5的可以有5800Mhz,可以看到即使是在今时今日下我们也是有需求运行在性能指标不高的计算平台上的。
为此我给出我所用的深度学习服务器Xeon Gold的平台(3090显卡)的上面那个测速程序的表现:
Device: NVIDIA GeForce RTX 3090
Transfer size (MB): 16
Pageable transfers
Host to Device bandwidth (GB/s): 4.994694
Device to Host bandwidth (GB/s): 4.974600
Pinned transfers
Host to Device bandwidth (GB/s): 12.210918
Device to Host bandwidth (GB/s): 12.751124
可以看到在计算平台性能指标不高的情况下,pinned memory依然可以保持有对于pageable memory几倍的差距,不过在现在的单次计算认为都不是很短的情况下,即使是服务器平台下不使用pinned memory也不会有什么显著的性能差距。这里需要注意,在GPU一定的情况下,影响拷贝速率的主要是CPU、内存和主板,影响pageable和pinned的性能差距的主要是内存和CPU,而影响pinned性能的主要是主板和GPU,也就是为什么服务器上pageable transfers的性能和个人计算机性能相差不大(服务器CPU和内存性能低),但是pinned的性能原高个人计算平台(主板和显卡好)。
===============================================
篇幅搞的有些长了,关于non_blocking的接受就再开一个post来说了,见:
TensorFlow和pytorch中的pin_memory和non_blocking设置是做什么的,又是否有用???(续)
PS: pytorch中的pin_memory和non_blocking的存在主要是因为pytorch从深度学习框架的千年老二老三已经升级为老大了(TensorFlow搞了个2.X版本,简直是自毁长城),因此pytorch更加希望能够稳固地位、扩大版图,虽然pytorch是对CUDA的一种包装,但是其性能的损耗是必然的,如何进一步提升pytorch和naive cuda之间性能差距就自然成了pytorch的一个要解决的目标。
--------------------------------------------------------------
posted on 2022-11-11 20:41 Angry_Panda 阅读(1167) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号