读论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》——(续)实验部分
论文地址:
https://arxiv.org/pdf/1802.01561v2.pdf
论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》是基于论文《Safe and efficient off-policy reinforcement learning》改进后的分布式版本,基础论文《Safe and efficient off-policy reinforcement learning》的地址为:
https://arxiv.org/pdf/1606.02647.pdf
相关资料:
Deepmind Lab环境的python扩展库的安装:
https://www.cnblogs.com/devilmaycry812839668/p/16750126.html
读论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》
=========================================
官方的代码地址:(现已无法运行)
https://gitee.com/devilmaycry812839668/scalable_agent
需要注意的一点是这个offical的代码由于多年无人维护,现在已经无法运行,只做留档之用。
调试官方代码的相关资料:
出现`Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR`错误的解决办法
具体解法:
# 配置GPU参数 config = tf.compat.v1.ConfigProto(allow_soft_placement=True) config.gpu_options.per_process_gpu_memory_fraction = 0.3
undefined symbol: _ZN10tensorflow7strings6StrCatERKNS0_8AlphaNumE
具体解法:
TF_INC="$(python -c 'import tensorflow as tf; print(tf.sysconfig.get_include())')" TF_LIB="$(python -c 'import tensorflow as tf; print(tf.sysconfig.get_lib())')" g++ -std=c++11 -shared batcher.cc -o batcher.so -fPIC -I $TF_INC -O2 -D_GLIBCXX_USE_CXX11_ABI=1 -L$TF_LIB -ltensorflow_framework
=========================================
官方代码为python2.7版本,将部分代码升级为python3.6版本。
(https://gitee.com/devilmaycry812839668/scalable_agent)
dmlab30.py 修改为python3.6版本:


# Copyright 2018 Google LLC # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # https://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. """Utilities for DMLab-30.""" from __future__ import absolute_import from __future__ import division from __future__ import print_function import collections import numpy as np import tensorflow as tf LEVEL_MAPPING = collections.OrderedDict([ ('rooms_collect_good_objects_train', 'rooms_collect_good_objects_test'), ('rooms_exploit_deferred_effects_train', 'rooms_exploit_deferred_effects_test'), ('rooms_select_nonmatching_object', 'rooms_select_nonmatching_object'), ('rooms_watermaze', 'rooms_watermaze'), ('rooms_keys_doors_puzzle', 'rooms_keys_doors_puzzle'), ('language_select_described_object', 'language_select_described_object'), ('language_select_located_object', 'language_select_located_object'), ('language_execute_random_task', 'language_execute_random_task'), ('language_answer_quantitative_question', 'language_answer_quantitative_question'), ('lasertag_one_opponent_small', 'lasertag_one_opponent_small'), ('lasertag_three_opponents_small', 'lasertag_three_opponents_small'), ('lasertag_one_opponent_large', 'lasertag_one_opponent_large'), ('lasertag_three_opponents_large', 'lasertag_three_opponents_large'), ('natlab_fixed_large_map', 'natlab_fixed_large_map'), ('natlab_varying_map_regrowth', 'natlab_varying_map_regrowth'), ('natlab_varying_map_randomized', 'natlab_varying_map_randomized'), ('skymaze_irreversible_path_hard', 'skymaze_irreversible_path_hard'), ('skymaze_irreversible_path_varied', 'skymaze_irreversible_path_varied'), ('psychlab_arbitrary_visuomotor_mapping', 'psychlab_arbitrary_visuomotor_mapping'), ('psychlab_continuous_recognition', 'psychlab_continuous_recognition'), ('psychlab_sequential_comparison', 'psychlab_sequential_comparison'), ('psychlab_visual_search', 'psychlab_visual_search'), ('explore_object_locations_small', 'explore_object_locations_small'), ('explore_object_locations_large', 'explore_object_locations_large'), ('explore_obstructed_goals_small', 'explore_obstructed_goals_small'), ('explore_obstructed_goals_large', 'explore_obstructed_goals_large'), ('explore_goal_locations_small', 'explore_goal_locations_small'), ('explore_goal_locations_large', 'explore_goal_locations_large'), ('explore_object_rewards_few', 'explore_object_rewards_few'), ('explore_object_rewards_many', 'explore_object_rewards_many'), ]) HUMAN_SCORES = { 'rooms_collect_good_objects_test': 10, 'rooms_exploit_deferred_effects_test': 85.65, 'rooms_select_nonmatching_object': 65.9, 'rooms_watermaze': 54, 'rooms_keys_doors_puzzle': 53.8, 'language_select_described_object': 389.5, 'language_select_located_object': 280.7, 'language_execute_random_task': 254.05, 'language_answer_quantitative_question': 184.5, 'lasertag_one_opponent_small': 12.65, 'lasertag_three_opponents_small': 18.55, 'lasertag_one_opponent_large': 18.6, 'lasertag_three_opponents_large': 31.5, 'natlab_fixed_large_map': 36.9, 'natlab_varying_map_regrowth': 24.45, 'natlab_varying_map_randomized': 42.35, 'skymaze_irreversible_path_hard': 100, 'skymaze_irreversible_path_varied': 100, 'psychlab_arbitrary_visuomotor_mapping': 58.75, 'psychlab_continuous_recognition': 58.3, 'psychlab_sequential_comparison': 39.5, 'psychlab_visual_search': 78.5, 'explore_object_locations_small': 74.45, 'explore_object_locations_large': 65.65, 'explore_obstructed_goals_small': 206, 'explore_obstructed_goals_large': 119.5, 'explore_goal_locations_small': 267.5, 'explore_goal_locations_large': 194.5, 'explore_object_rewards_few': 77.7, 'explore_object_rewards_many': 106.7, } RANDOM_SCORES = { 'rooms_collect_good_objects_test': 0.073, 'rooms_exploit_deferred_effects_test': 8.501, 'rooms_select_nonmatching_object': 0.312, 'rooms_watermaze': 4.065, 'rooms_keys_doors_puzzle': 4.135, 'language_select_described_object': -0.07, 'language_select_located_object': 1.929, 'language_execute_random_task': -5.913, 'language_answer_quantitative_question': -0.33, 'lasertag_one_opponent_small': -0.224, 'lasertag_three_opponents_small': -0.214, 'lasertag_one_opponent_large': -0.083, 'lasertag_three_opponents_large': -0.102, 'natlab_fixed_large_map': 2.173, 'natlab_varying_map_regrowth': 2.989, 'natlab_varying_map_randomized': 7.346, 'skymaze_irreversible_path_hard': 0.1, 'skymaze_irreversible_path_varied': 14.4, 'psychlab_arbitrary_visuomotor_mapping': 0.163, 'psychlab_continuous_recognition': 0.224, 'psychlab_sequential_comparison': 0.129, 'psychlab_visual_search': 0.085, 'explore_object_locations_small': 3.575, 'explore_object_locations_large': 4.673, 'explore_obstructed_goals_small': 6.76, 'explore_obstructed_goals_large': 2.61, 'explore_goal_locations_small': 7.66, 'explore_goal_locations_large': 3.14, 'explore_object_rewards_few': 2.073, 'explore_object_rewards_many': 2.438, } ALL_LEVELS = frozenset([ 'rooms_collect_good_objects_train', 'rooms_collect_good_objects_test', 'rooms_exploit_deferred_effects_train', 'rooms_exploit_deferred_effects_test', 'rooms_select_nonmatching_object', 'rooms_watermaze', 'rooms_keys_doors_puzzle', 'language_select_described_object', 'language_select_located_object', 'language_execute_random_task', 'language_answer_quantitative_question', 'lasertag_one_opponent_small', 'lasertag_three_opponents_small', 'lasertag_one_opponent_large', 'lasertag_three_opponents_large', 'natlab_fixed_large_map', 'natlab_varying_map_regrowth', 'natlab_varying_map_randomized', 'skymaze_irreversible_path_hard', 'skymaze_irreversible_path_varied', 'psychlab_arbitrary_visuomotor_mapping', 'psychlab_continuous_recognition', 'psychlab_sequential_comparison', 'psychlab_visual_search', 'explore_object_locations_small', 'explore_object_locations_large', 'explore_obstructed_goals_small', 'explore_obstructed_goals_large', 'explore_goal_locations_small', 'explore_goal_locations_large', 'explore_object_rewards_few', 'explore_object_rewards_many', ]) def _transform_level_returns(level_returns): """Converts training level names to test level names.""" new_level_returns = {} for level_name, returns in level_returns.items(): new_level_returns[LEVEL_MAPPING.get(level_name, level_name)] = returns test_set = set(LEVEL_MAPPING.values()) diff = test_set - set(new_level_returns.keys()) if diff: raise ValueError('Missing levels: %s' % list(diff)) for level_name, returns in new_level_returns.items(): if level_name in test_set: if not returns: raise ValueError('Missing returns for level: \'%s\': ' % level_name) else: tf.logging.info('Skipping level %s for calculation.', level_name) return new_level_returns def compute_human_normalized_score(level_returns, per_level_cap): """Computes human normalized score. Levels that have different training and test versions, will use the returns for the training level to calculate the score. E.g. 'rooms_collect_good_objects_train' will be used for 'rooms_collect_good_objects_test'. All returns for levels not in DmLab-30 will be ignored. Args: level_returns: A dictionary from level to list of episode returns. per_level_cap: A percentage cap (e.g. 100.) on the per level human normalized score. If None, no cap is applied. Returns: A float with the human normalized score in percentage. Raises: ValueError: If a level is missing from `level_returns` or has no returns. """ new_level_returns = _transform_level_returns(level_returns) def human_normalized_score(level_name, returns): score = np.mean(returns) human = HUMAN_SCORES[level_name] random = RANDOM_SCORES[level_name] human_normalized_score = (score - random) / (human - random) * 100 if per_level_cap is not None: human_normalized_score = min(human_normalized_score, per_level_cap) return human_normalized_score return np.mean( [human_normalized_score(k, v) for k, v in new_level_returns.items()])
py_process.py 修改为python3.6版本:
# Copyright 2018 Google LLC # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # https://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. """PyProcess. This file includes utilities for running code in separate Python processes as part of a TensorFlow graph. It is similar to tf.py_func, but the code is run in separate processes to avoid the GIL. Example: class Zeros(object): def __init__(self, dim0): self._dim0 = dim0 def compute(self, dim1): return np.zeros([self._dim0, dim1], dtype=np.int32) @staticmethod def _tensor_specs(method_name, kwargs, constructor_kwargs): dim0 = constructor_kwargs['dim0'] dim1 = kwargs['dim1'] if method_name == 'compute': return tf.contrib.framework.TensorSpec([dim0, dim1], tf.int32) with tf.Graph().as_default(): p = py_process.PyProcess(Zeros, 1) result = p.proxy.compute(2) with tf.train.SingularMonitoredSession( hooks=[py_process.PyProcessHook()]) as session: print(session.run(result)) # Prints [[0, 0]]. """ from __future__ import absolute_import from __future__ import division from __future__ import print_function import multiprocessing import tensorflow as tf from tensorflow.python.util import function_utils nest = tf.contrib.framework.nest class _TFProxy(object): """A proxy that creates TensorFlow operations for each method call to a separate process.""" def __init__(self, type_, constructor_kwargs): self._type = type_ self._constructor_kwargs = constructor_kwargs def __getattr__(self, name): def call(*args): kwargs = dict( zip(function_utils.fn_args(getattr(self._type, name))[1:], args)) specs = self._type._tensor_specs(name, kwargs, self._constructor_kwargs) if specs is None: raise ValueError( 'No tensor specifications were provided for: %s' % name) flat_dtypes = nest.flatten(nest.map_structure(lambda s: s.dtype, specs)) flat_shapes = nest.flatten(nest.map_structure(lambda s: s.shape, specs)) def py_call(*args): try: self._out.send(args) result = self._out.recv() if isinstance(result, Exception): raise result if result is not None: return result except Exception as e: if isinstance(e, IOError): raise StopIteration() # Clean exit. else: raise result = tf.py_func(py_call, (name,) + tuple(args), flat_dtypes, name=name) if isinstance(result, tf.Operation): return result for t, shape in zip(result, flat_shapes): t.set_shape(shape) return nest.pack_sequence_as(specs, result) return call def _start(self): self._out, in_ = multiprocessing.Pipe() self._process = multiprocessing.Process( target=self._worker_fn, args=(self._type, self._constructor_kwargs, in_)) self._process.start() result = self._out.recv() if isinstance(result, Exception): raise result def _close(self, session): try: self._out.send(None) self._out.close() except IOError: pass self._process.join() def _worker_fn(self, type_, constructor_kwargs, in_): try: o = type_(**constructor_kwargs) in_.send(None) # Ready. while True: # Receive request. serialized = in_.recv() if serialized is None: if hasattr(o, 'close'): o.close() in_.close() return # method_name = str(serialized[0]) method_name = serialized[0].decode() inputs = serialized[1:] # Compute result. results = getattr(o, method_name)(*inputs) if results is not None: results = nest.flatten(results) # Respond. in_.send(results) except Exception as e: if 'o' in locals() and hasattr(o, 'close'): try: o.close() except: pass in_.send(e) class PyProcess(object): COLLECTION = 'py_process_processes' def __init__(self, type_, *constructor_args, **constructor_kwargs): self._type = type_ self._constructor_kwargs = dict( zip(function_utils.fn_args(type_.__init__)[1:], constructor_args)) self._constructor_kwargs.update(constructor_kwargs) tf.add_to_collection(PyProcess.COLLECTION, self) self._proxy = _TFProxy(type_, self._constructor_kwargs) @property def proxy(self): """A proxy that creates TensorFlow operations for each method call.""" return self._proxy def close(self, session): self._proxy._close(session) def start(self): self._proxy._start() class PyProcessHook(tf.train.SessionRunHook): """A MonitoredSession hook that starts and stops PyProcess instances.""" def begin(self): tf.logging.info('Starting all processes.') tp = multiprocessing.pool.ThreadPool() tp.map(lambda p: p.start(), tf.get_collection(PyProcess.COLLECTION)) tp.close() tp.join() tf.logging.info('All processes started.') def end(self, session): tf.logging.info('Closing all processes.') tp = multiprocessing.pool.ThreadPool() tp.map(lambda p: p.close(session), tf.get_collection(PyProcess.COLLECTION)) tp.close() tp.join() tf.logging.info('All processes closed.')
对 experiment.py 文件进行修改,具体修改不给出了,已经将所有修改后的代码上传到:
https://gitee.com/devilmaycry812839668/scalable_agent
=====================================================
经过以上修改和配置后,官方代码可以在单机模式下正常运行,唯一的问题就是太消耗资源了,具体命令:
python experiment.py --num_actors=1 --batch_size=1
运行:
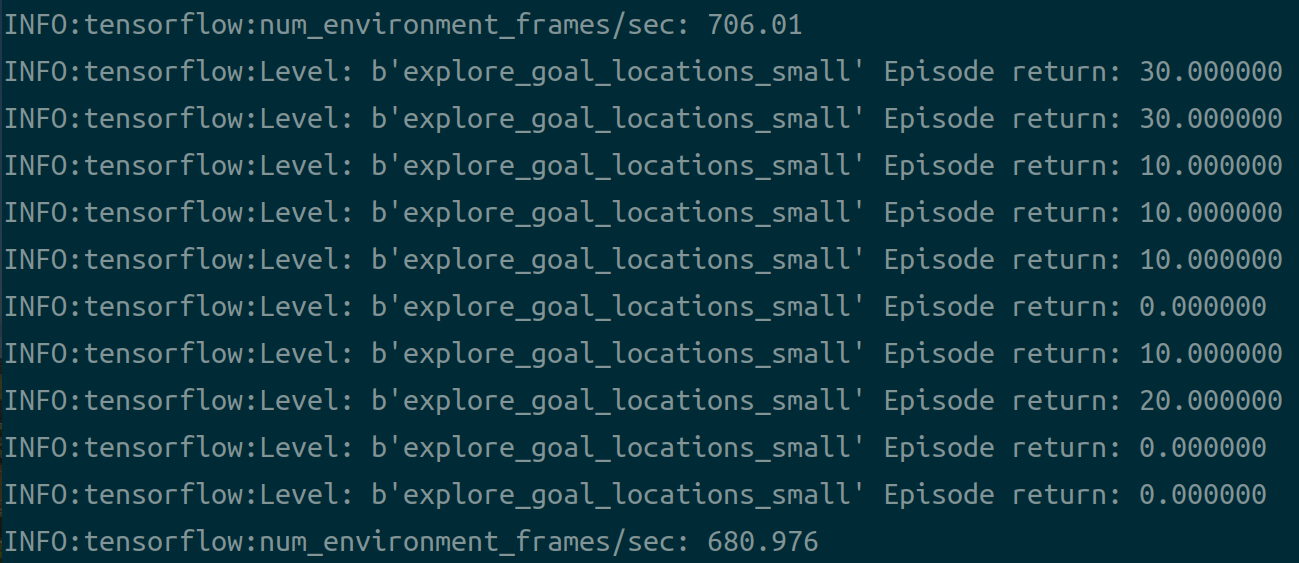
------------------------------------------------
2022年10月29日更新
单机使用12个actor运行,硬件为cpu 10700k,gpu为rtx2070super,运行命令:

平均帧率:4000

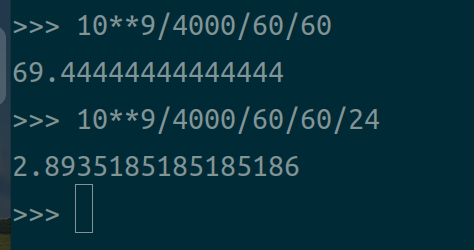
单个实验设定的帧数为10**9,那么一个环境的实验在个人主机上运行大概需要时间:70个小时,3天时间
--------------------------
这个时间消耗十分的巨大,本打算能成功跑完一个环境,不过现在看看也是不现实的。
============================================
posted on 2022-10-16 10:53 Angry_Panda 阅读(257) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号