读论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》
论文地址:
https://arxiv.org/pdf/1802.01561v2.pdf
论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》是基于论文《Safe and efficient off-policy reinforcement learning》改进后的分布式版本,基础论文《Safe and efficient off-policy reinforcement learning》的地址为:
https://arxiv.org/pdf/1606.02647.pdf
相关资料:
Deepmind Lab环境的python扩展库的安装:
https://www.cnblogs.com/devilmaycry812839668/p/16750126.html
=========================================
2022年10月13日 更新
官方的代码:https://gitee.com/devilmaycry812839668/scalable_agent
经过修改后将python2.7代码升级为python3.6版本后,通过配置已经可以在单机模式下运行,具体参见:读论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》——(续)实验部分
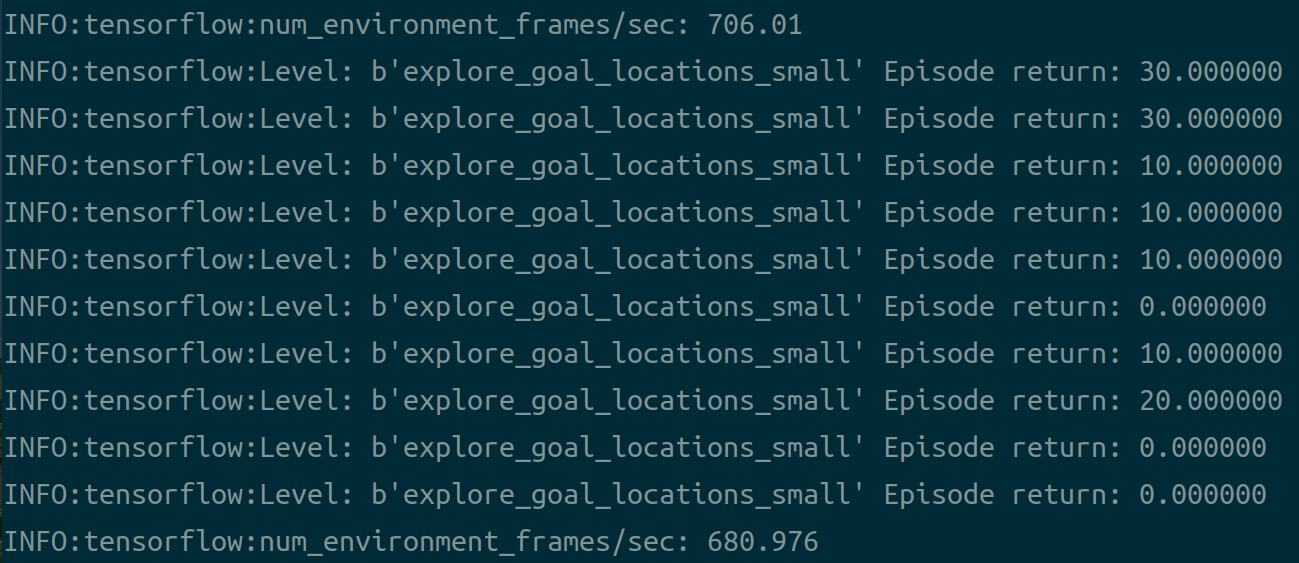
单机情况下运行:
python experiment.py --num_actors=1 --batch_size=1
成功运行:
=========================================
官方的代码地址:(现已无法运行)
https://gitee.com/devilmaycry812839668/scalable_agent
需要注意的一点是这个offical的代码由于多年无人维护,现在已经无法运行,只做留档之用。
=========================================
2022年10月10日再读
本文主要做的工作就是off-policy correction。本文给出了大量的公式证明,不过说实话,也就看了个大概,细节没有看懂,说一下一些自己的理解。
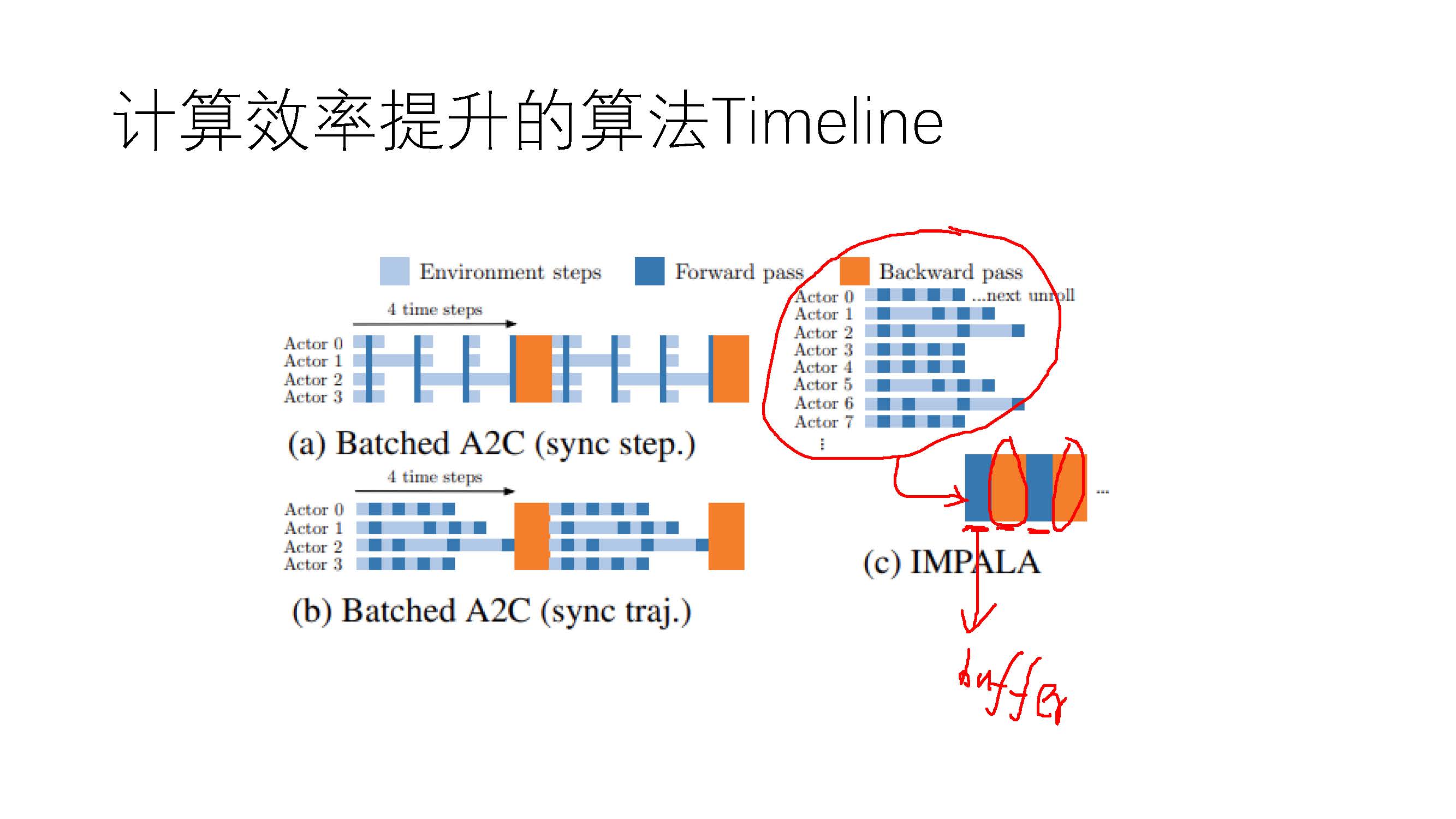
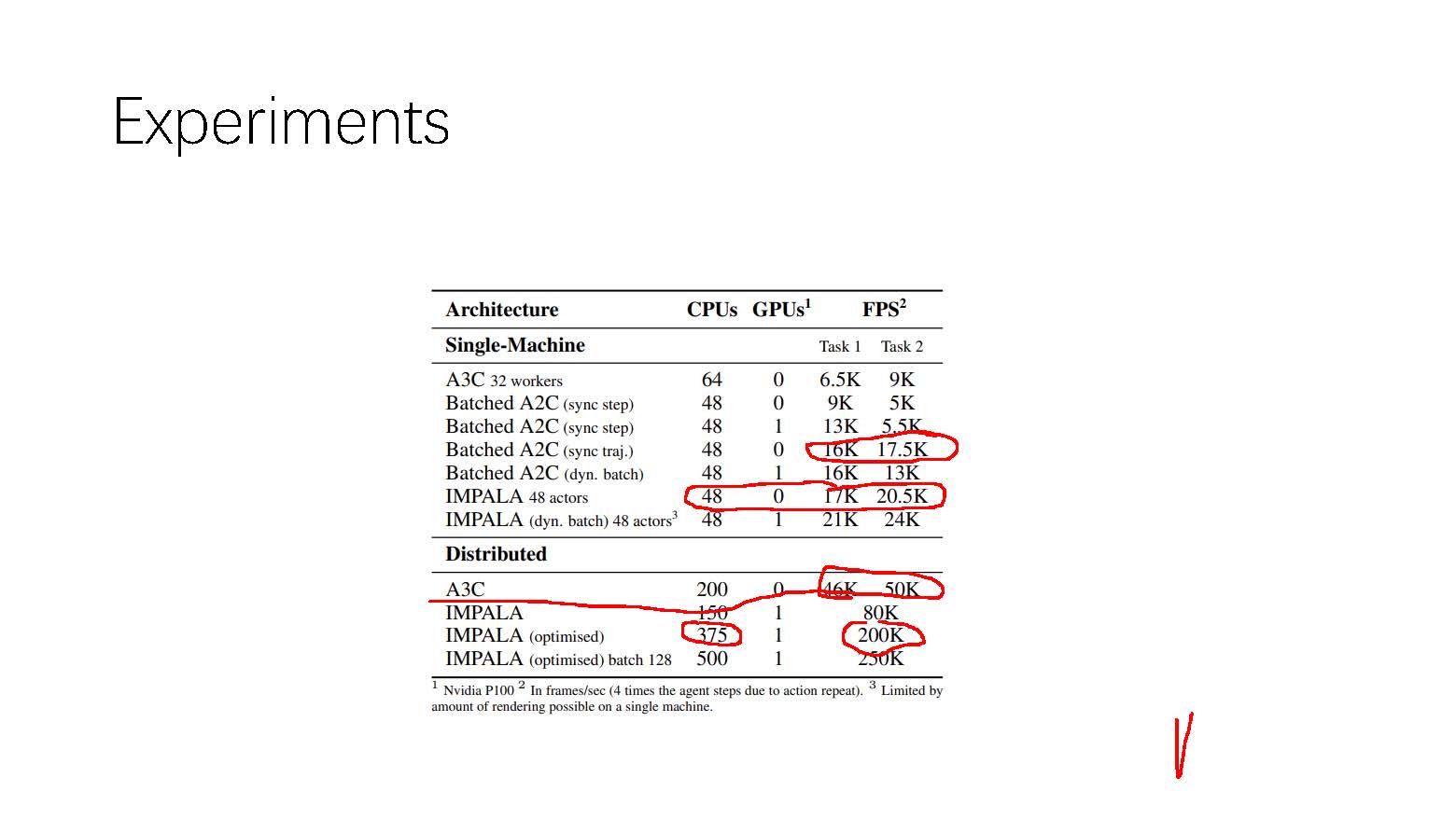
其实本文的主要的内容就是on-policy的AC算法分布式改进,我们知道由于分布式计算会引起非常多的同步问题,由于AC算法本身是on-policy的,所以分布式的AC会对网络的同步操作有较强的要求,但是为了实现AC算法的高吞吐量,A3C算法被提出。A3C算法采用不强制同步的方法对AC算法进行分布式计算,这样就势必会造成behaviour policy和target policy的不同,甚至分布的差距很大,而这种差距对算法的性能会造成harmful,为此A2C算法被提出,与A3C一样其本质就是对AC算法进行分布式计算,但是不同于A3C算法,A2C算法强制 different 的actor需要定期同步target policy,这样就使A2C算法成了AC算法在算法性能上不受坏的影响的分布式方法。但是A2C算法虽然保证了AC算法的on-policy本质特性,但是这无疑会影响算法的吞吐量,在计算的时钟周期上会有很大的提升空间。为此《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》论文提出一种新的AC算法的分布式方法,在同步上采用A3C的方式,不对不同actor采用强制同步,但是对于由此造成的behaviour policy和target poliy的分布不同采用了一种off-policy correction,格外说的一点是在论文IMPALA中主要的对比算法(baseline)使用的是A3C,但是从算法的特性上来看IMPALA算法的真正应该的对比算法是A2C,这样才能更好的保证公平性,对于IMPALA和A2C算法性能的对比在论文中还是有很大空白空间的。
--------------------------------------------
AC算法的基本原理(公式):

这个公式的背景是对环境的充分抽样,也就是理想上可以认为是假设对所有的环境状态都进行了充分的遍历,当然这个假设是在现实计算中难以实现的,现实计算中都是对一个特定policy下对环境采取一点episodes的采样,然后更新获得一个新的policy,我们是无法在一个policy下就对环境进行足够充分的采样的,这是现实计算所不能够允许的。
在实际的AC算法计算中,采用的真正的计算公式为:
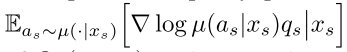
通过上面的计算公式也可以看出,AC算法是on-policy的,但是如果训练的策略在收到采样数据之前已经update几次了,那么再用这个采样的数据来训练policy就变成了off-policy。虽然我们可以像A3C算法那样忽略由于采样时延和不强制同步造成的off-policy,而是已然按照on-policy的方式进行计算,但是这样势必造成的算法性能损失和训练的不稳定性,为此可以采样重要性采样的方式来对采样的数据进行修正,由此得到使用重要性采样修正后的off-policy来近似on-policy,公式:
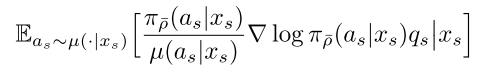
其中,u为behaviour policy,pi为target policy。
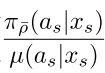 为重要性采样的系数。
为重要性采样的系数。
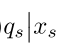 为target policy策略下的Q值。
为target policy策略下的Q值。
通过上面的公式我们可以知道,这个target policy策略下的Q是唯一不能通过采样直接获得的,而且我们也不能直接从behaviour policy的数据上来训练得到这个Q值,因为这个Q值指的是target policy下的。
本文的主要工作就是在《Safe and efficient off-policy reinforcement learning》基础上给出了off-policy下target policy的V值的计算。《Safe and efficient off-policy reinforcement learning》给出了一种off-policy下target policy的Q值的计算方式。
可以说本文的主要工作就是给出了一种off-policy下target policy的Q值的计算方式,公式:
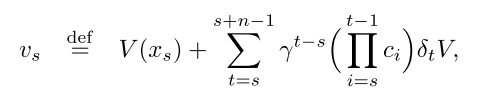
其中,vs为修正后近似的target policy下的state value值,V则是target policy下的state value值。
本文假设vs近似等于V,vs所属的修正后的target policy为:
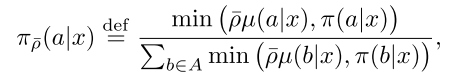
可以看到,修正后的target policy和真正的target policy是不同的,修正后的target policy为:
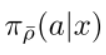
而target policy则为:
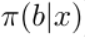
而behaviour policy为:
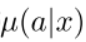
可以看到,这三个policy是不同的。
本文的假设和推导就是,target policy 和修正后的target policy 是相近的,在经过足够的训练后收敛时,target policy和修正后的target policy是相当的。
------------------------------------------------------------------
对V的训练公式为:(V为target policy,V是有参数的,修正后的target policy的state value是vs,vs也是基于V的参数的)
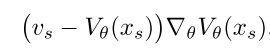
vs是在target policy的V的基础上进行修正的,修正的方法就是在V的数值基础上加上 behaviour policy采样下的数据在target policy下的TD error乘以系数,具体:

为什么这个vs的策略为:
实在是没有看懂,这个地方也就忽略吧。
----------------------------------------------------------------------------------
在训练时:
先对target policy下的V进行训练,因为作者证明了target policy收敛到最优策略时vs等于V,因此这里对V的训练采用了下面的方式:
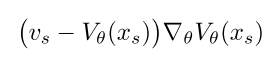
对target policy的策略参数进行训练:
因为作者证明了target policy收敛到最优策略时vs等于V,因此target policy下的q为:
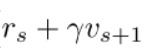
所以使用重要性采样后的策略训练为:
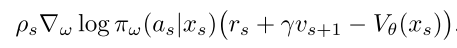
而这个训练公式也可以写为上面刚才给出的模式:
--------------------------------------------------------------
可以说本文的主要贡献就是给出了一种off-policy下通过behaviour policy采样的数据表示、训练的修正后的target policy,然后又通过是修正后的target policy下的state value近似于target policy下的state value,来获得对target policy下的q值表示。
=========================================




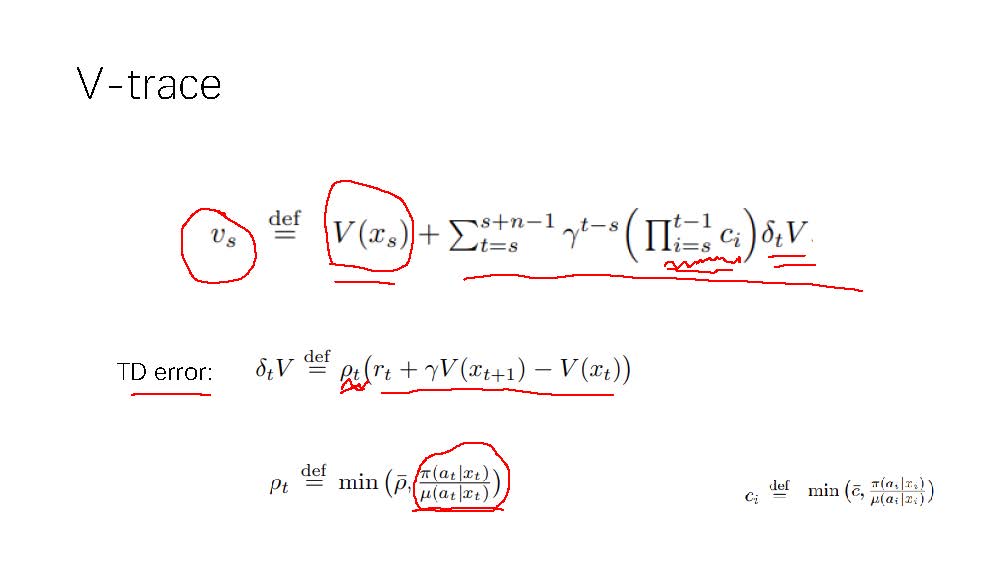



posted on 2022-10-01 13:02 Angry_Panda 阅读(332) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号