MindSpore 如何实现一个线性回归 —— Demo示例
如何使用 MindSpore 实现一个简单的 线性回归呢???
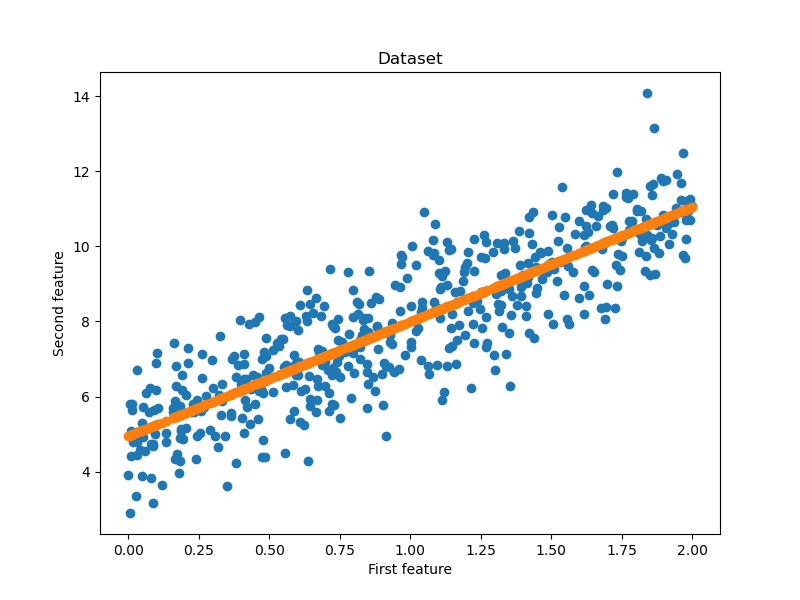
根据前面的mindspore的基本操作的学习写出了下面的 一个简单的线性回归算法。
import mindspore import numpy as np #引入numpy科学计算库 import matplotlib.pyplot as plt #引入绘图库 np.random.seed(123) #随机数生成种子 #from sklearn.model_selection import train_test_split#从sklearn里面引出训练与测试集划分 import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype # 训练数据集 def creat_dataset(): n_x=2*np.random.rand(500,1)#随机生成一个0-2之间的,大小为(500,1)的向量 n_y=5+3*n_x+np.random.randn(500,1)#随机生成一个线性方程的,大小为(500,1)的向量 x = Tensor(n_x, dtype=mindspore.float32) y = Tensor(n_y, dtype=mindspore.float32) return x, y class Net(nn.Cell): def __init__(self, input_dims, output_dims): super(Net, self).__init__() self.matmul = ops.MatMul() self.weight_1 = Parameter(Tensor(np.random.randn(input_dims, 128), dtype=mstype.float32), name='weight_1') self.bias_1 = Parameter(Tensor(np.zeros(128), dtype=mstype.float32), name='bias_1') self.weight_2 = Parameter(Tensor(np.random.randn(128, 64), dtype=mstype.float32), name='weight_2') self.bias_2 = Parameter(Tensor(np.zeros(64), dtype=mstype.float32), name='bias_2') self.weight_3 = Parameter(Tensor(np.random.randn(64, output_dims), dtype=mstype.float32), name='weight_3') self.bias_3 = Parameter(Tensor(np.zeros(output_dims), dtype=mstype.float32), name='bias_3') def construct(self, x): x = self.matmul(x, self.weight_1)+self.bias_1 x = self.matmul(x, self.weight_2)+self.bias_2 x = self.matmul(x, self.weight_3)+self.bias_3 return x class LossNet(nn.Cell): def __init__(self, net): super(LossNet, self).__init__() self.net = net self.pow = ops.Pow() self.mean = ops.ReduceMean() def construct(self, x, y): _x = self.net(x) loss = self.mean(self.pow(_x - y, 2)) return loss class GradNetWrtX(nn.Cell): def __init__(self, net): super(GradNetWrtX, self).__init__() self.net = net self.params = ParameterTuple(net.trainable_params()) self.grad_op = ops.GradOperation(get_by_list=True) def construct(self, x, y): gradient_function = self.grad_op(self.net, self.params) return gradient_function(x, y) def train(epochs, loss_net, x, y, print_flag=False): # 构建加和操作 ass_add = ops.AssignAdd() para_list = loss_net.trainable_params() for epoch in range(epochs): grad_net = GradNetWrtX(loss_net) grad_list = grad_net(x, y) for para, grad in zip(para_list, grad_list): ass_add(para, -0.000001*grad) if print_flag and (epoch%100 == 0): print("epoch: %s, loss: %s"%(epoch, loss_net(x, y))) def main(): epochs = 10000 x, y = creat_dataset() net = Net(x.shape[-1], y.shape[-1]) loss_net = LossNet(net) train(epochs, loss_net, x, y, False) y_hat = net(x) fig=plt.figure(figsize=(8,6))#确定画布大小 plt.title("Dataset")#标题名 plt.xlabel("First feature")#x轴的标题 plt.ylabel("Second feature")#y轴的标题 plt.scatter(x.asnumpy(), y.asnumpy())#设置为散点图 plt.scatter(x.asnumpy(), y_hat.asnumpy())#设置为散点图 plt.show()#绘制出来 if __name__ == '__main__': """ 设置运行的背景context """ from mindspore import context # 为mindspore设置运行背景context context.set_context(mode=context.PYNATIVE_MODE, device_target='GPU') import time a = time.time() main() b = time.time() print(b-a)
最终结果:
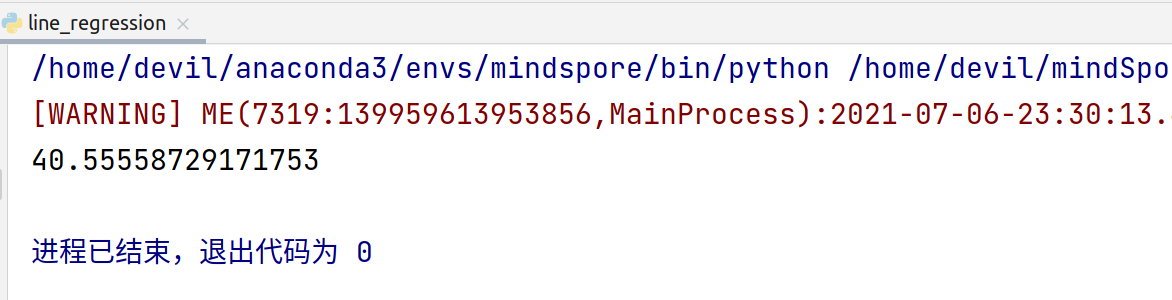
多次运行后,平均运行时间:
41秒
运行环境:
Ubuntu18.04系统
i7-9700HQ
笔记本显卡 1660ti
======================================================================================
发现一个神奇的事情,如果我们把context的模式设置为 GRAPH_MODE
也就是:
context.set_context(mode=context.GRAPH_MODE, device_target='GPU')
那么运行过程中会不停的提示警告:
[WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:07.536.303 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1116905_construct_wrapper, J user: 1116905_construct_wrapper:construct{[0]: 7496, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:07.664.157 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1117054_construct_wrapper, J user: 1117054_construct_wrapper:construct{[0]: 7497, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:07.787.667 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1117203_construct_wrapper, J user: 1117203_construct_wrapper:construct{[0]: 7498, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:07.906.649 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1117352_construct_wrapper, J user: 1117352_construct_wrapper:construct{[0]: 7499, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.021.086 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1117501_construct_wrapper, J user: 1117501_construct_wrapper:construct{[0]: 7500, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.136.975 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1117650_construct_wrapper, J user: 1117650_construct_wrapper:construct{[0]: 7501, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.271.804 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1117799_construct_wrapper, J user: 1117799_construct_wrapper:construct{[0]: 7502, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.380.832 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1117948_construct_wrapper, J user: 1117948_construct_wrapper:construct{[0]: 7503, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.489.950 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1118097_construct_wrapper, J user: 1118097_construct_wrapper:construct{[0]: 7504, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.599.613 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1118246_construct_wrapper, J user: 1118246_construct_wrapper:construct{[0]: 7505, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.707.115 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1118395_construct_wrapper, J user: 1118395_construct_wrapper:construct{[0]: 7506, [1]: x, [2]: y, [3]: ValueNode<UMonad> U} [WARNING] OPTIMIZER(4150,python):2021-07-06-23:07:08.812.025 [mindspore/ccsrc/frontend/optimizer/ad/dfunctor.cc:860] FindPrimalJPair] J operation has no relevant primal call in the same graph. Func graph: 1118544_construct_wrapper, J user: 1118544_construct_wrapper:construct{[0]: 7507, [1]: x, [2]: y, [3]: ValueNode<UMonad> U}
具体代码:


import mindspore import numpy as np #引入numpy科学计算库 import matplotlib.pyplot as plt #引入绘图库 np.random.seed(123) #随机数生成种子 #from sklearn.model_selection import train_test_split#从sklearn里面引出训练与测试集划分 import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype # 训练数据集 def creat_dataset(): n_x=2*np.random.rand(500,1)#随机生成一个0-2之间的,大小为(500,1)的向量 n_y=5+3*n_x+np.random.randn(500,1)#随机生成一个线性方程的,大小为(500,1)的向量 x = Tensor(n_x, dtype=mindspore.float32) y = Tensor(n_y, dtype=mindspore.float32) return x, y class Net(nn.Cell): def __init__(self, input_dims, output_dims): super(Net, self).__init__() self.matmul = ops.MatMul() self.weight_1 = Parameter(Tensor(np.random.randn(input_dims, 128), dtype=mstype.float32), name='weight_1') self.bias_1 = Parameter(Tensor(np.zeros(128), dtype=mstype.float32), name='bias_1') self.weight_2 = Parameter(Tensor(np.random.randn(128, 64), dtype=mstype.float32), name='weight_2') self.bias_2 = Parameter(Tensor(np.zeros(64), dtype=mstype.float32), name='bias_2') self.weight_3 = Parameter(Tensor(np.random.randn(64, output_dims), dtype=mstype.float32), name='weight_3') self.bias_3 = Parameter(Tensor(np.zeros(output_dims), dtype=mstype.float32), name='bias_3') def construct(self, x): x = self.matmul(x, self.weight_1)+self.bias_1 x = self.matmul(x, self.weight_2)+self.bias_2 x = self.matmul(x, self.weight_3)+self.bias_3 return x class LossNet(nn.Cell): def __init__(self, net): super(LossNet, self).__init__() self.net = net self.pow = ops.Pow() self.mean = ops.ReduceMean() def construct(self, x, y): _x = self.net(x) loss = self.mean(self.pow(_x - y, 2)) return loss class GradNetWrtX(nn.Cell): def __init__(self, net): super(GradNetWrtX, self).__init__() self.net = net self.params = ParameterTuple(net.trainable_params()) self.grad_op = ops.GradOperation(get_by_list=True) def construct(self, x, y): gradient_function = self.grad_op(self.net, self.params) return gradient_function(x, y) def train(epochs, loss_net, x, y, print_flag=False): # 构建加和操作 ass_add = ops.AssignAdd() para_list = loss_net.trainable_params() for epoch in range(epochs): grad_net = GradNetWrtX(loss_net) grad_list = grad_net(x, y) for para, grad in zip(para_list, grad_list): ass_add(para, -0.000001*grad) if print_flag and (epoch%100 == 0): print("epoch: %s, loss: %s"%(epoch, loss_net(x, y))) def main(): epochs = 10000 x, y = creat_dataset() net = Net(x.shape[-1], y.shape[-1]) loss_net = LossNet(net) train(epochs, loss_net, x, y, False) y_hat = net(x) fig=plt.figure(figsize=(8,6))#确定画布大小 plt.title("Dataset")#标题名 plt.xlabel("First feature")#x轴的标题 plt.ylabel("Second feature")#y轴的标题 plt.scatter(x.asnumpy(), y.asnumpy())#设置为散点图 plt.scatter(x.asnumpy(), y_hat.asnumpy())#设置为散点图 plt.show()#绘制出来 if __name__ == '__main__': """ 设置运行的背景context """ from mindspore import context # 为mindspore设置运行背景context #context.set_context(mode=context.PYNATIVE_MODE, device_target='GPU') context.set_context(mode=context.GRAPH_MODE, device_target='GPU') import time a = time.time() main() b = time.time() print(b-a)
最终结果:

============================================================
可以看到不同 context 模式的设置,运行时间相差20倍左右。
# 为mindspore设置运行背景context
context.set_context(mode=context.GRAPH_MODE, device_target='GPU')
context.set_context(mode=context.PYNATIVE_MODE, device_target='GPU')
具体原因是什么,这里也是搞不太清楚???
本文作为尝试使用mindspore功能,具体原因也就不深究了。
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2021-07-06 10:48 Angry_Panda 阅读(767) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号