MindSpore 自动微分
代码原地址:
https://www.mindspore.cn/tutorial/zh-CN/r1.2/autograd.html
MindSpore计算一阶导数方法 mindspore.ops.GradOperation (get_all=False, get_by_list=False, sens_param=False),其中get_all为False时,只会对第一个输入求导,为True时,会对所有输入求导;
get_by_list为False时,不会对权重求导,为True时,会对权重求导;
sens_param对网络的输出值做缩放以改变最终梯度。
get_all : 决定着是否根据输出对输入进行求导。
get_by_list : 决定着是否对神经网络内的参数权重求导。
sens_param : 对网络的输出进行乘积运算后再求导。(通过对网络的输出值进行缩放后再进行求导)
网络的前向传播:
import numpy as np import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype class Net(nn.Cell): def __init__(self): super(Net, self).__init__() self.matmul = ops.MatMul() self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y): x = x * self.z out = self.matmul(x, y) return out model = Net() for m in model.parameters_and_names(): print(m) x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32) y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32) result = model(x, y) print(result) n_x = np.array([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=np.float32) n_y = np.array([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=np.float32) result = model(x, y) print(result)
=======================================================
反向传播:
import numpy as np import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype class Net(nn.Cell): def __init__(self): super(Net, self).__init__() self.matmul = ops.MatMul() self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y): x = x * self.z out = self.matmul(x, y) return out class GradNetWrtX(nn.Cell): def __init__(self, net): super(GradNetWrtX, self).__init__() self.net = net self.grad_op = ops.GradOperation() def construct(self, x, y): gradient_function = self.grad_op(self.net) return gradient_function(x, y) x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32) y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32) output = GradNetWrtX(Net())(x, y) print(output)
因为, ops.GradOperation(),
mindspore.ops.GradOperation (get_all=False, get_by_list=False, sens_param=False)
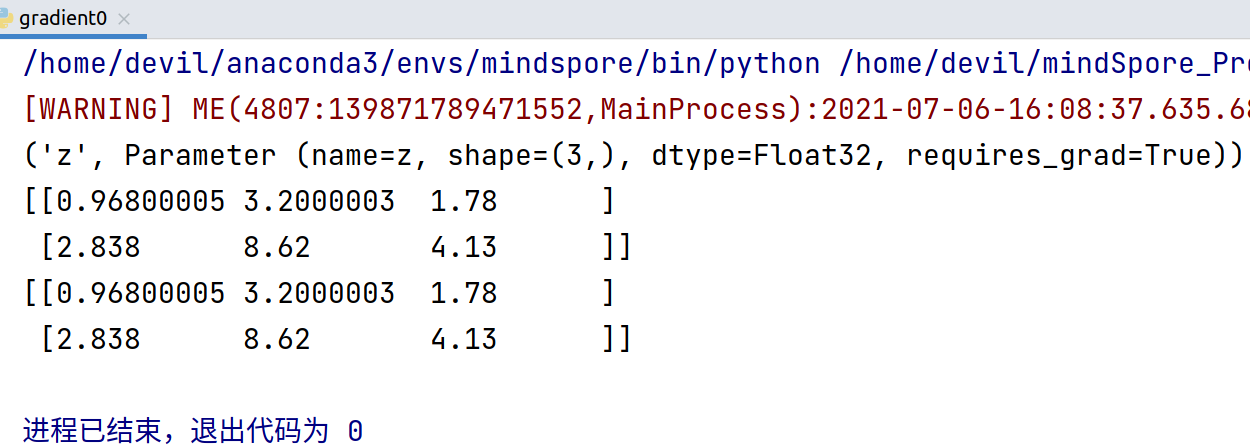
get_all=False, 表示只对第一个输入向量求导,也就是对x 求梯度, 结果得到x的梯度:

如果想对所有的输入求梯度, ops.GradOperation(get_all=True)
代码:
import numpy as np import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype class Net(nn.Cell): def __init__(self): super(Net, self).__init__() self.matmul = ops.MatMul() self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y): x = x * self.z out = self.matmul(x, y) return out class GradNetWrtX(nn.Cell): def __init__(self, net): super(GradNetWrtX, self).__init__() self.net = net self.grad_op = ops.GradOperation(get_all=True) def construct(self, x, y): gradient_function = self.grad_op(self.net) return gradient_function(x, y) x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32) y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32) output = GradNetWrtX(Net())(x, y) print(len(output)) print('='*30) print(output[0]) print('='*30) print(output[1])
对网络的所有输入求导,即,对 x ,y 求梯度。
对权重求一阶导
对权重求一阶导数其实与前面相比有两个地方要更改:
1. 求导函数要写明对权重求导,即传入参数 get_by_list=True
即,
self.grad_op = ops.GradOperation(get_by_list=True)
2. 具体求导时要传入具体待求导的参数(即,权重):
self.params = ParameterTuple(net.trainable_params())
gradient_function = self.grad_op(self.net, self.params)
细节:


需要知道的一点是如果我们设置了对权重求梯度,则默认不会再对输入求梯度:
代码:
import numpy as np import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype class Net(nn.Cell): def __init__(self): super(Net, self).__init__() self.matmul = ops.MatMul() self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y): x = x * self.z out = self.matmul(x, y) return out class GradNetWrtX(nn.Cell): def __init__(self, net): super(GradNetWrtX, self).__init__() self.net = net self.params = ParameterTuple(net.trainable_params()) self.grad_op = ops.GradOperation(get_by_list=True) def construct(self, x, y): gradient_function = self.grad_op(self.net, self.params) return gradient_function(x, y) model = Net() x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32) y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32) output = GradNetWrtX(model)(x, y) print(len(output)) print('='*30) print(output[0]) print('='*30)

如果对网络内部权重求梯度同时也想对输入求梯度,只能显示的设置 get_all=True,
即,
self.grad_op = ops.GradOperation(get_all=True, get_by_list=True)
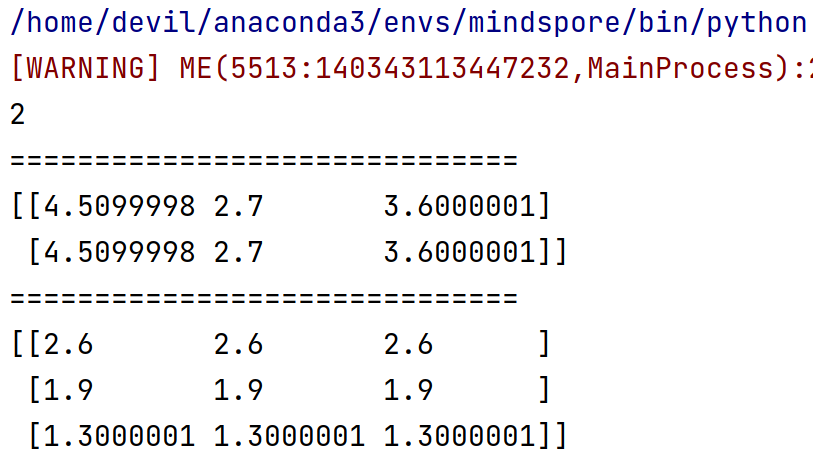
此时输出的梯度为 元组 , tuple(所有输入的梯度, 内部权重梯度)
也就是说这种情况返回的是一个两个元素的元组,元组中第一个元素是所有输入的梯度,第二个是所有内部权重的梯度。
代码:
import numpy as np import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype class Net(nn.Cell): def __init__(self): super(Net, self).__init__() self.matmul = ops.MatMul() self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y): x = x * self.z out = self.matmul(x, y) return out class GradNetWrtX(nn.Cell): def __init__(self, net): super(GradNetWrtX, self).__init__() self.net = net self.params = ParameterTuple(net.trainable_params()) self.grad_op = ops.GradOperation(get_all=True, get_by_list=True) def construct(self, x, y): gradient_function = self.grad_op(self.net, self.params) return gradient_function(x, y) model = Net() x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32) y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32) output = GradNetWrtX(model)(x, y) print(len(output)) print('='*30) print(output[0]) print('='*30) print(output[1])
运行结果:
[WARNING] ME(6838:140435163703104,MainProcess):2021-07-06-16:56:49.250.395 [mindspore/_check_version.py:109] Cuda version file version.txt is not found, please confirm that the correct cuda version has been installed, you can refer to the installation guidelines: https://www.mindspore.cn/install
2
==============================
(Tensor(shape=[2, 3], dtype=Float32, value=
[[ 4.50999975e+00, 2.70000005e+00, 3.60000014e+00],
[ 4.50999975e+00, 2.70000005e+00, 3.60000014e+00]]), Tensor(shape=[3, 3], dtype=Float32, value=
[[ 2.59999990e+00, 2.59999990e+00, 2.59999990e+00],
[ 1.89999998e+00, 1.89999998e+00, 1.89999998e+00],
[ 1.30000007e+00, 1.30000007e+00, 1.30000007e+00]]))
==============================
(Tensor(shape=[3], dtype=Float32, value= [ 1.17259989e+01, 5.13000011e+00, 4.68000031e+00]),)
进程已结束,退出代码为 0
posted on 2021-07-06 10:43 Angry_Panda 阅读(334) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号