【转载】 集成学习
原文地址:
https://www.cnblogs.com/nucdy/p/9003192.html
================================================
集成学习最重要的两种类型:装袋(Bagging)与提升(Boosting),从其两大算法入手:Random Forest、GBDT。
集成学习包括元算法和模型融合两方面
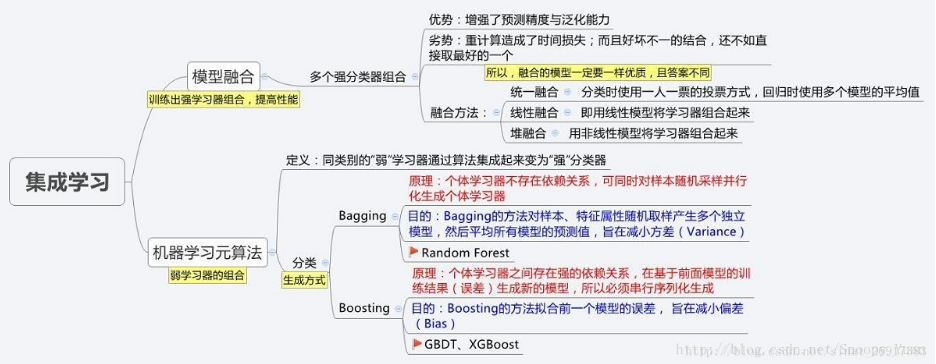
从图中可以看出,元算法提供了从个体弱学习器到集成强学习器的实现,模型融合则在强学习器的基础上,设计结合策略进一步提升性能,元算法按照个体弱学习器之间的依赖关联关系,又分为Boosting类算法和Bagging类算法。
元算法
Bagging
Bagging(装袋法)基于自助采样法(bootstrap sampling)来生成训练数据,通过多轮有放回的对初始训练集进行随机采样,多个训练集被并行化生成,对应可训练出多个基学习器,再将这些基学习器结合,构建出强学习器。
因为是随机有放回的采样(自助法),初始训练集中的样本既有可能多次出现在某个采样集中,又有可能不出现,通过统计计算,初始集约有63.2%的样本出现在训练集当中,剩下的36.8%样本可用于模型泛化能力的验证,这种方法称为“包外估计”(out-of-bag-estimation),同时包外样本还可以用于决策树的剪枝、神经网络早停控制等等。
装袋法的本质是引入了样本扰动,通过增加样本随机性,达到降低方差的效果,这种方法在决策树、神经网络等易受样本扰动影响的模型上效果尤为明显。
其他:https://www.cnblogs.com/pinard/p/6156009.html
RF(随机森林)
RF-Random Forest(随机森林)是Bagging的扩展,主要面向决策树模型,在Bagging法构造决策树基学习器的基础上,对每步划分时的当前特征集进行随机选择以生成随机特征子集,然后再在子集中选择最优特征进行划分,进而训练出当前的基学习器。
在进行当前节点特征(假设 d 个)随机选择时,子集特征数目 k 推荐取值 k≈log2(d) 。较小的特征子集加速了训练,减小了计算开销。
随机森林通过特征子集的随机选择的方式,引入了特征扰动,在装袋法的基础上,这种方法可进一步降低了方差,增强了模型的泛化精度。
其他:https://blog.csdn.net/qq547276542/article/details/78304454
AdaBoost
不同与Bagging,Boosting算法,是一种串行序列化方法,它的前后两个基学习器间强关联,后面学习器的训练往往建立在前面学习器的训练结果基础上。
AdaBoost算法是Boosting算法族的典型代表,它基于“残差逼近”的思路,采用“重赋权法”,即是根据每个基学习器的结果调整样本权重,生成新的更加关注于错误样本的数据分布,然后在新数据分布上继续以损失函数最小为目标训练新的基学习器。同时根据这些基学习器的训练误差,对基学习器赋权,最后采用加权求和得出集成模型。
AdaBoost旨在减小学习的偏差,能够基于泛化精度很差的学习器个体构建出强集成。
GBDT
GB(Gradient Boosting)可以被看作是AdaBoost的变体,最大不同之处在于GB在迭代优化过程中采用了梯度计算而非加权计算。GB通过在每一步残差减少的梯度方向上训练新的基学习器,最后通过集成得到强学习器。
GBDT算法(Gradient Boosting Decision Tree)是一种基于GB框架下的决策树集成学习算法。基学习器采用的是以最小化平方误差为目标的回归树,迭代的过程建立在对“之前残差的负梯度表示”的回归拟合上,最后累加得到整个提升树。
同其他Boosting算法一样,GBDT也关注于降低拟合的偏差。
其他:https://blog.csdn.net/google19890102/article/details/51746402
分类实验
这里我们采用2个sklearn.datasets自带的UCI数据集进行实验。两种算法(RF和GBDT)的实现基于sklearn.ensemble。这里查看完整实验代码-GitHub。
具体可看:https://blog.csdn.net/akenseren/article/details/79428059#t0
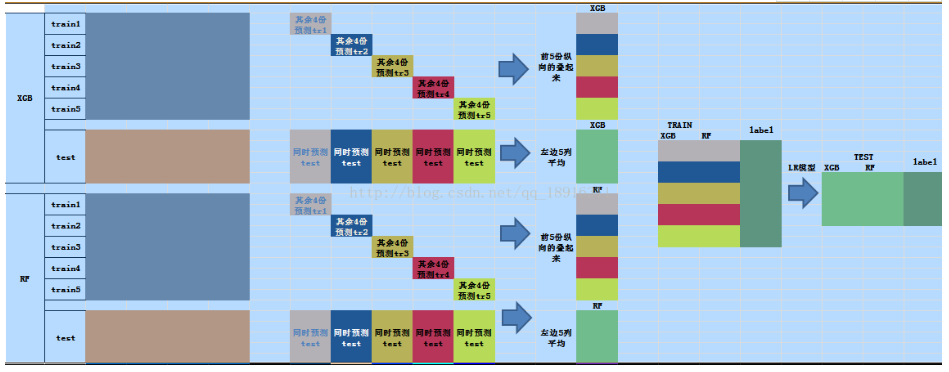
Stacking
stacking的核心:在训练集上进行预测,从而构建更高层的学习器。
stacking训练过程:
1) 拆解训练集。将训练数据随机且大致均匀的拆为m份
2)在拆解后的训练集上训练模型,同时在测试集上预测。利用m-1份训练数据进行训练,预测剩余一份;在此过程进行的同时,利用相同的m-1份数据训练,在真正的测试集上预测;如此重复m次,将训练集上m次结果叠加为1列,将测试集上m次结果取均值融合为1列。
3)使用k个分类器重复2过程。将分别得到k列训练集的预测结果,k列测试集预测结果。
4)训练3过程得到的数据。将k列训练集预测结果和训练集真实label进行训练,将k列测试集预测结果作为测试集。
参考:
https://blog.csdn.net/qq_18916311/article/details/78557722
https://blog.csdn.net/qq_36330643/article/details/78576503

假设,现在来了赛方牵出了一头大大象,大家眼睛都蒙着,我们采用stacking技术,来摸象。
1、选择基模型,换句话说,你现在手下有一帮盲人,你得选择几个得力的盲人,如xgb盲人,lgb盲人,RF盲人等等。虽然三个臭皮匠确实能实现一个诸葛亮的效果,但是现实情况往往是,我们在基模型上就会选择比较厉害的模型,直接用三个诸葛亮模型融合,来确保融合效果。
2、划分数据。这一步就是把大象给剁了,这多少有点残忍哈。为方便说明,我们假设把大象分成了2份。我们分别记录为train1~train2。如果不能理解,你就想象成是2堆大象。每堆里面都有部分大象的肢体。
3、现在我们有2堆大象肉,我们让1个盲人去摸其中的1堆,然后去预测剩下那堆,并保留结果,其中我们还要根据摸过获得的经验,去预测下需要预测的测试集。
4、因为我们有3个盲人,所以我们得让每个盲人都摸一次。因此此时,我们有来自3个盲人的3份体会,以及3个盲人对测试集的预测情况,这取决于你安排了多少个盲人。
5、当每个盲人都摸过后,3个盲人要进行开会了。盲人们会分享,自己摸过后获得的感受和经验,以及对需要预测的测试集的预测情况。
这里大家可能会有疑问了,盲人们怎么来分享呢?
xgb盲人说:我摸了其中一堆,用这个体会去感受剩下那堆的时候,感觉这第二堆是啥啥啥,测试集是啥啥啥。
RF盲人说:balabalabalba…….
发现没有,只有通过第三步这个过程,盲人们才能彼此分享对于这部分数据的感受。
最后,我们通常用LR模型,来总结大家的经验。这个LR模型,看来有点像会议主持人哈,虽然摸象不咋地,但是特别会总结。
其他:https://blog.csdn.net/q383700092/article/details/53557410
这里就引出了模型融合了
模型融合
http://www.cnblogs.com/nucdy/p/9003159.html
补充:
周志华老师中的
集成学习
集成学习,顾名思义就是将多个学习器集成在一起来完成某个任务。其一般结构为:
- 先产生一组个体学习器;
- 然后再用某种策略将这些个体学习器结合起来。
但是并不是说把任何的个体学习器结合起来都可以有效果的提升,其对于学习器的准确率和多样性是有一定要求的,如下例所示:

我们可以看到,对于第二种学习器集成方式,由于其三个学习器对于测试集的预测结果都是一样的,虽然每个学习器的准确率比较高,但是集合在一起并没有达到我们预想的性能提升的目的;对于第三种学习器的集成,虽然其多样性得到了保证,但是每个学习器的准确率很低,导致在集成之后性能不升反降;而对于第一种学习器的集成,因为其即保证了个体学习器的准确性,又保证了不同学习器之间的差异性,从而在集成之后性能相对于个体学习器有了很大的提升。
因此,对于集成学习,想要达到预想中相对于个体学习器性能的提升,我们即需要保证每个个体学习器自身比较高的准确率,还要保证学习器的多样性。但是实际上个体学习器的准确性和多样性是冲突的,即学习器的准确性如果很高的话,要增加多样性就需要牺牲准确性。对于集成学习,如何产生好而不同的个体学习器一直都是集成学习的研究核心。而且通常来说对于弱学习器,其集成后的性能提升是要优于强学习器的。
对于集成学习,个体学习器的差异会带来集成策略的不同。当我们的个体学习器都是同质的(学习器都是同种类型的),此时的个体学习器我们称为基学习器,其主要由两大类集成策略是:Boosting和Bagging;当个体学习器是异质的,集成策略的典型代表是Stacking算法。
参考:
https://blog.csdn.net/batuwuhanpei/article/details/52045977
http://bigdata.51cto.com/art/201609/518319.htm
https://www.cnblogs.com/willnote/p/6801496.html
===========================================================
posted on 2021-06-03 10:01 Angry_Panda 阅读(197) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号