并行化强化学习 —— 初探 —— 并行reinforce算法的尝试 (上篇:强化学习在多仿真环境下单步交互并行化设计的可行性)
强化学习由于难收敛所以训练周期较长,同时由于强化学习在训练过程中起训练数据一般都为实时生成的,因此在训练的同时算法还需要生成待训练的数据,强化学习算法的基本架构可以视作下图:(取自:深度学习中使用TensorFlow或Pytorch框架时到底是应该使用CPU还是GPU来进行运算???)
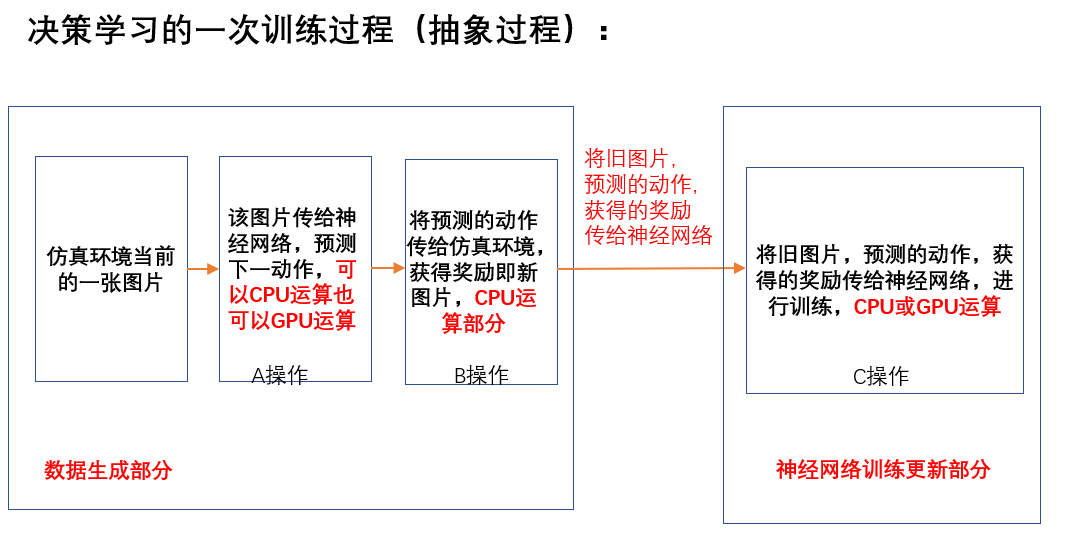
由强化学习的一般算法结构我们可以大致的把强化学习算法分为数据生成和策略训练两个部分,也就是说对于强化学习这种训练周期比较长的算法我们或许可以对两部分进行提速从而达到提高算法运行效率的目的,同时也或许能够提高算法的最终性能。
本博文主要讲的就是对数据生成部分的提速,之所以不讲如何对策略训练部分提速是因为该部分可以视作为监督学习,而在TensorFlow和pytorch框架里面对这一部分的并行化或分布式话的提速办法已经十分成熟了,这一部分可以参见TensorFlow多显卡并行化和流水线话等主题。
现在比较SOTA的强化学习算法基本都是基于并行化数据生成部分的强化学习算法,如:
- A3C
- A2C
- Ape-X
- IMPALA
强化学习 —— reinforce算法中更新一次策略网络时episodes个数的设置对算法性能的影响 —— reinforce算法中迭代训练一次神经网络时batch_size大小的不同设置对算法性能的影响
),由此我们将多个环境的单步决策的动作统一进行运算给出预测会减少该部分的运算时间,因为多个环境的决策预测和单个环境的决策预测在耗时上基本是相当的,这样就把多个环境的决策预测所耗费的时间压缩成了单个环境的决策预测所耗费的时间,目的是以此提高运算速度。不过该方法如果加大环境数,同时没episode的长度较短就会出现一部分环境是使用多步更新前的策略生成的,如果众多环境中有较大部分环境是由较多步策略更新之前的策略生成的就会造成所生成的数据与当前训练的策略差距较大,从而影响算法的收敛(该部分的具体讨论参见:强化学习中经验池的替代设计——A3C算法 下的留言 )。即使该种设计会出现这种问题,但是这种情况也是较为极端的情况,如果我们控制好并行环境的个数也是可以使算法有效收敛的,也正是除以该种设计的思路给出了mode=0的设计。第一种设计,即mode=0, 在环境个数:envs_number=1时就是标准的reinforce算法。我们这里分别讨论envs_number=1和enves_number=256这两种情况,其中envs_number=1这样是作为baseline来设计的。
python PolicyNetwork_version.py --mode=0 --processes_number=1 --envs_number=1
# 5次mode=0设计的算法, envs_number=1 Average reward for episode 229050 : 203.380000. Average reward for episode 229100 : 200.800000. Average reward for episode 229150 : 207.220000. Average reward for episode 229200 : 204.640000. Average reward for episode 229250 : 206.760000. Average reward for episode 229300 : 203.540000. Average reward for episode 229350 : 201.580000. Task solved in 229350 episodes! 229350 4928.224210739136 Average reward for episode 190500 : 204.780000. Average reward for episode 190550 : 205.240000. Average reward for episode 190600 : 204.300000. Average reward for episode 190650 : 204.640000. Average reward for episode 190700 : 201.720000. Average reward for episode 190750 : 200.040000. Average reward for episode 190800 : 202.380000. Task solved in 190800 episodes! 190800 4841.455847740173 Average reward for episode 205300 : 204.900000. Average reward for episode 205350 : 201.700000. Average reward for episode 205400 : 204.620000. Average reward for episode 205450 : 202.940000. Average reward for episode 205500 : 205.060000. Average reward for episode 205550 : 202.940000. Average reward for episode 205600 : 204.260000. Average reward for episode 205650 : 202.960000. Average reward for episode 205700 : 202.020000. Task solved in 205700 episodes! 205700 5161.240854263306 Average reward for episode 204200 : 200.040000. Average reward for episode 204250 : 201.600000. Average reward for episode 204300 : 204.160000. Average reward for episode 204350 : 207.080000. Average reward for episode 204400 : 200.440000. Average reward for episode 204450 : 206.660000. Average reward for episode 204500 : 205.760000. Average reward for episode 204550 : 202.560000. Average reward for episode 204600 : 202.000000. Task solved in 204600 episodes! 204600 4988.276462554932 Average reward for episode 214100 : 202.620000. Average reward for episode 214150 : 203.340000. Average reward for episode 214200 : 204.660000. Average reward for episode 214250 : 203.720000. Average reward for episode 214300 : 203.140000. Average reward for episode 214350 : 200.360000. Average reward for episode 214400 : 202.000000. Average reward for episode 214450 : 205.000000. Task solved in 214450 episodes! 214450 5436.505903959274
其中,每次实验结果的最后一行为运行时间,单位为秒,倒数第二行为共训练的episodes的个数。
python PolicyNetwork_version.py --mode=0 --processes_number=1 --envs_number=256
# 5次试验结果,mode=0, envs_number=4
Average reward for episode 189450 : 205.920000. Average reward for episode 189500 : 201.060000. Average reward for episode 189550 : 207.360000. Average reward for episode 189600 : 200.740000. Average reward for episode 189650 : 200.340000. Average reward for episode 189700 : 204.220000. Average reward for episode 189750 : 204.760000. Task solved in 189750 episodes! 189750 6126.243483543396 Average reward for episode 205250 : 203.040000. Average reward for episode 205300 : 204.040000. Average reward for episode 205350 : 203.000000. Average reward for episode 205400 : 200.700000. Average reward for episode 205450 : 203.760000. Average reward for episode 205500 : 203.300000. Task solved in 205500 episodes! 205500 6676.588801622391 Average reward for episode 226800 : 202.740000. Average reward for episode 226850 : 202.640000. Average reward for episode 226900 : 205.180000. Average reward for episode 226950 : 204.060000. Average reward for episode 227000 : 204.440000. Average reward for episode 227050 : 203.300000. Task solved in 227050 episodes! 227050 6373.813208580017 Average reward for episode 208900 : 206.980000. Average reward for episode 208950 : 204.860000. Average reward for episode 209000 : 203.480000. Average reward for episode 209050 : 206.160000. Average reward for episode 209100 : 203.500000. Average reward for episode 209150 : 201.860000. Average reward for episode 209200 : 201.180000. Task solved in 209200 episodes! 209200 6139.423493385315 Average reward for episode 231800 : 204.460000. Average reward for episode 231850 : 206.520000. Average reward for episode 231900 : 203.380000. Average reward for episode 231950 : 203.660000. Average reward for episode 232000 : 202.560000. Average reward for episode 232050 : 203.660000. Average reward for episode 232100 : 203.380000. Average reward for episode 232150 : 204.360000. Average reward for episode 232200 : 201.540000. Average reward for episode 232250 : 200.060000. Task solved in 232250 episodes! 232250 6523.121243715286
可以看到并行的环境数增加时运算时间有所增加,并没有如设计之初的设想会提高算法的运算速度,反而减慢了些运算,由于试验次数较少并不具备统计特性,所以即使有这个结果也不能说明增加环境个数后影响了算法效率反而减慢了算法收敛,由于较少的试验并没有显示出较大的差距,我们更可以相信mode=0,即第一种设计的并行化方法并不能较高置信度的提高算法的效率。因此,可以姑且将第一种设计看做和原始算法性能相当的设计。而对于多环境下设计在较少试验中效果不佳我们可以将其当做是算法在切换不同环境时有性能的损耗,因为这个操作就需要额外的计算时间,同时由于前面所说的多环境会造成训练数据和当前策略的分布不匹配更进一步影响了算法性能,同时由于该种设计本身就是伪并行真串行的代码,所以其最为理性的结果就是和baseline(原始reinforce算法)效果一样,而实际中有略微下降也是可以解释的,况且较少的试验本身也不具备较高置信度的统计特性。
第二种设计:mode=1
第三种设计:mode=2
第二种设计和第三种设计本质上是一致的,都是使用多个进程来进行数据生成,每个进程使用一个环境,并且同题目所说都是单步交互并行的,也就是数据生成部分只进行单步的数据生成。第二种设计和第三种设计的相同点是生成数据的进程在生成单步数据后均将数据放入队列后等待下步的预测动作,不同点在于第二种设计中主进程(动作预测和策略训练部分的进程)每次都是从队列中取出一个生成的数据,然后判断是进行动作预测或者是策略训练,而在第三种设计中主进程每次在取出数据时都要判断一下队列中共有多少数据然后一次性的全部取出,再逐个判断是训练策略还是预测动作。
python PolicyNetwork_version.py --mode=1 --processes_number=4 --envs_number=256
# 5次试验结果,mode=1, processes_number=4 ,envs_number=256
Average reward for episode 193000 : 206.200000. Average reward for episode 193050 : 203.040000. Average reward for episode 193100 : 205.180000. Average reward for episode 193150 : 206.820000. Average reward for episode 193200 : 202.420000. Average reward for episode 193250 : 201.560000. Task solved in 193250 episodes! 193250 6807.235226154327 Average reward for episode 198150 : 207.540000. Average reward for episode 198200 : 203.660000. Average reward for episode 198250 : 204.620000. Average reward for episode 198300 : 205.440000. Average reward for episode 198350 : 202.460000. Average reward for episode 198400 : 206.620000. Average reward for episode 198450 : 200.960000. Task solved in 198450 episodes! 198450 7417.285929441452 Average reward for episode 219250 : 202.360000. Average reward for episode 219300 : 205.720000. Average reward for episode 219350 : 202.400000. Average reward for episode 219400 : 205.380000. Average reward for episode 219450 : 201.720000. Average reward for episode 219500 : 201.520000. Average reward for episode 219550 : 207.920000. Task solved in 219550 episodes! 219550 7404.594935178757 Average reward for episode 216750 : 202.900000. Average reward for episode 216800 : 201.900000. Average reward for episode 216850 : 202.880000. Average reward for episode 216900 : 204.960000. Average reward for episode 216950 : 201.580000. Average reward for episode 217000 : 204.880000. Average reward for episode 217050 : 204.740000. Average reward for episode 217100 : 207.300000. Task solved in 217100 episodes! 217100 7781.906627416611 Average reward for episode 218550 : 202.020000. Average reward for episode 218600 : 203.000000. Average reward for episode 218650 : 204.200000. Average reward for episode 218700 : 205.600000. Average reward for episode 218750 : 204.800000. Average reward for episode 218800 : 202.560000. Average reward for episode 218850 : 200.320000. Average reward for episode 218900 : 206.000000. Task solved in 218900 episodes! 218900 5906.976158380508
倒数第一行为运行的时间(单位:秒),倒数第二行为总共训练的episodes个数。
python PolicyNetwork_version.py --mode=2 --processes_number=4 --envs_number=256
# 5次试验结果,mode=2, processes_number=4 envs_number=256
Average reward for episode 186600 : 205.700000. Average reward for episode 186650 : 203.480000. Average reward for episode 186700 : 203.500000. Average reward for episode 186750 : 203.700000. Average reward for episode 186800 : 204.100000. Average reward for episode 186850 : 204.660000. Average reward for episode 186900 : 200.520000. Average reward for episode 186950 : 203.200000. Task solved in 186950 episodes! 186950 16561.332327604294 Average reward for episode 197300 : 205.600000. Average reward for episode 197350 : 200.640000. Average reward for episode 197400 : 203.500000. Average reward for episode 197450 : 205.580000. Average reward for episode 197500 : 202.240000. Average reward for episode 197550 : 203.700000. Average reward for episode 197600 : 201.620000. Task solved in 197600 episodes! 197600 17538.959105968475 Average reward for episode 216450 : 203.780000. Average reward for episode 216500 : 206.400000. Average reward for episode 216550 : 208.480000. Average reward for episode 216600 : 203.140000. Average reward for episode 216650 : 200.120000. Average reward for episode 216700 : 207.540000. Average reward for episode 216750 : 205.500000. Task solved in 216750 episodes! 216750 19090.248321294785 Average reward for episode 212850 : 205.080000. Average reward for episode 212900 : 204.200000. Average reward for episode 212950 : 202.800000. Average reward for episode 213000 : 201.560000. Average reward for episode 213050 : 202.500000. Average reward for episode 213100 : 203.100000. Average reward for episode 213150 : 202.480000. Average reward for episode 213200 : 204.660000. Task solved in 213200 episodes! 213200 18722.594790697098 Average reward for episode 208300 : 205.120000. Average reward for episode 208350 : 201.360000. Average reward for episode 208400 : 201.820000. Average reward for episode 208450 : 204.060000. Average reward for episode 208500 : 202.740000. Average reward for episode 208550 : 201.960000. Average reward for episode 208600 : 202.640000. Task solved in 208600 episodes! 208600 11473.65299320221
=========================================
本文实验环境(硬件):
i7-9700k,CPU锁频4.9Ghz, GPU:2060super
posted on 2021-01-02 09:24 Angry_Panda 阅读(1164) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号