【转载】 训练深度神经网络失败的罪魁祸首不是梯度消失,而是退化
原文地址:

===========================================
作者通过深度线性网络的例子对照证明了导致最终网络性能变差的原因并不是梯度消失,而是权重矩阵的退化,导致模型的有效自由度减少,并指出该结论可以推广到非线性网络中。
--------------------
在这篇文章中,我将指出一个常见的关于训练深度神经网络的困难的误解。人们通常认为这种困难主要是(如果不全是)由于梯度消失问题(和/或梯度爆炸问题)。「梯度消失」指的是随着网络深度增加,参数的梯度范数指数式减小的现象。梯度很小,意味着参数的变化很缓慢,从而使得学习过程停滞,直到梯度变得足够大,而这通常需要指数量级的时间。这种思想至少可以追溯到 Bengio 等人 1994 年的论文:「Learning long-term dependencies with gradient descent is difficult」,目前似乎仍然是人们对深度神经网络的训练困难的偏好解释。
让我们首先考虑一个简单的场景:训练一个深度线性网络学习线性映射。当然,从计算的角度来看,深度线性网络并不有趣,但是 Saxe 等人 2013 年的论文「Exact solutions to the nonlinear dynamics of learning in deep linear neural networks」表明深度线性网络中的学习动力学仍然可以提供非线性网络的学习动力学的信息。因此,我们从这些简单的场景开始讨论。下图是一个 30 层网络(误差线是由 10 次独立运行得到的标准差)的学习曲线和初始梯度范数(训练之前)。
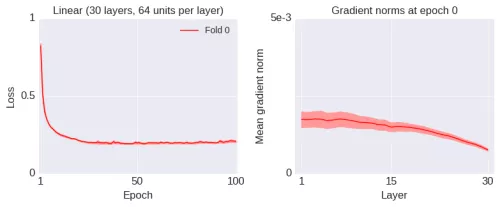
我将在之后简短地解释图中的标签「Fold 0」的含义。这里的梯度是关于层激活值的(与关于参数的梯度的行为类似)。网络的权重使用标准的初始化方法进行初始化。起初,训练损失函数下降得很快,但很快渐进地收敛于一个次优值。此时,梯度并没有消失(或爆炸),至少在初始阶段。梯度确实随着训练过程变小,但这是预料之中的,从任何方面看都不能清楚表明梯度已经变得「太小」:
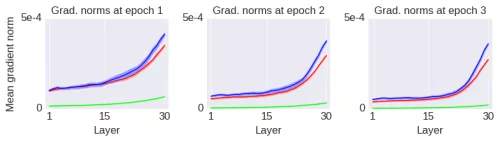
为了表明这里的收敛到局部最优解的现象和梯度范数的大小本身并没有关系,我将引入一种运算,它将增加梯度范数的值,却使得网络的性能变得更差。如下图所示(蓝线):

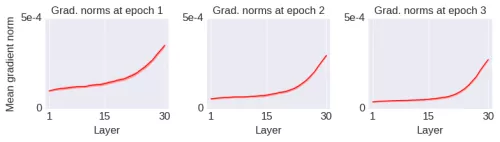
我只是简单地改变了初始化方法而已。初始网络的所有初始权重都是矩阵(使用标准方法初始化)。而在上图的蓝线中,我只是将每个初始权重矩阵的上半部分复制到下半部分(即初始权重矩阵被折叠了一次,因此称其为「Fold 1」网络)。这种运算降低了初始权重矩阵的秩,使得它们更加的退化(degenerate)。注意这种运算仅应用于初始权重矩阵,并没有加上其它对学习过程的约束,训练过程保持不变。经过几个 epoch 的训练之后,梯度范数的变化如下图所示:
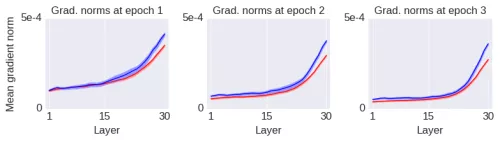
因此,我引入了一种运算,它增大了全局的梯度范数,但是性能却变差了很多。相反地,接下来我将引入另一种运算以减小梯度范数,却能大幅地提升网络的性能。如下图所示(绿线):
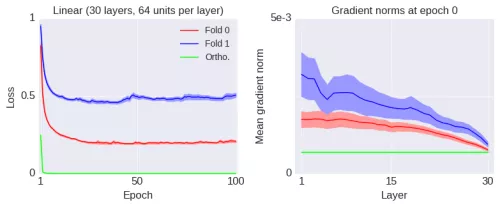
正如图中的标签「Ortho」所示,这种运算将权重矩阵初始化为正交的。正交矩阵是固定(Frobenius)范数的矩阵中退化程度最低的,其中退化度可以用多种方法计算。以下是经过几个 epoch 训练之后的梯度范数:
如果梯度范数的大小本身和深度网络的训练困难并没有关系,那是什么原因呢?答案是,模型的退化基本上决定了训练性能。为什么退化会损害训练性能?直观地说,学习曲线基本上会在参数空间的退化方向变慢,因此退化会减少模型的有效维度。在以前,你可能会认为是用参数拟合模型,但实际上,由于退化,可以有效地拟合模型的自由度却变少了。上述的「Fold 0」和「Fold 1」网络的问题在于,虽然梯度范数值还不错,但是网络的可用自由度对这些范数的贡献非常不均衡:虽然一些自由度(非退化的)贡献了梯度的主要部分,但大部分(退化的)自由度对此没有任何贡献(仅作概念性的理解,并不是很准确的解释。可以理解为在每个层中只有少量的隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同的输入都是相同的反应)。
正如 Saxe 等人的论文表明,随着相乘矩阵的数量(即网络深度)增加,矩阵的乘积变得更加退化(线性相关)。以下分别是该论文中的 1 层、10 层和 100 层网络的例子:

随着网络深度增加,积矩阵的奇异值变得越来越集中,而小部分出现频率很低的奇异值变得任意的大。这种结果不仅仅和线性网络相关。在非线性网络中也会出现类似的现象:随着深度增加,给定层的隐藏单元的维度变得越来越低,即越来越退化。实际上,在有硬饱和边界的非线性网络中(例如 ReLU 网络),随着深度增加,退化过程会变得越来越快。
Duvenaud 等人 2014 年的论文「Avoiding pathologies in very deep networks」里展示了关于该退化过程的可视化:

随着深度增加,输入空间(左上角)会在每个点都扭曲成越来越细的细丝,而只有一个与细丝正交的方向会影响网络的响应。在两个维度上表示出输入空间的变化可能会比较难,但是实验证明输入空间的点在局部会变为「hyper-pancakey」,即每一个点都有一个单一的方向正交于扭曲后的表面。若我们沿着这个敏感的方向改变输入,那么网络实际上对变化会非常敏感。
最后我忍不住想提一下我和 Xaq Pitkow 的论文。在论文 SKIP CONNECTIONS ELIMINATE SINGULARITIES 中,我们通过一系列实验表明本文讨论的退化问题严重影响了深度非线性网络的训练,而跳过连接(ResNet 中采用的重要方法)帮助深度神经网络实现高精度的训练同样是一种打破退化的方法。我们同样怀疑其它如批量归一化或层级归一化等方法有助于深度神经网络的训练,除了原论文所提出的如降低内部方差等潜在的独立性机制,也至少有一部分原因是退化被破坏而实现的。我们都知道分裂归一化(divisive normalization)对于解相关隐藏单元的响应非常高效,它也可以看成一种打破退化的机制。
除了我们的论文外,我还应该提一下 Pennington、 Schoenholz 和 Ganguli 最近提出的论文 Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice。在该论文中,正交初始化完全移除了线性网络中的退化问题。他们提出了一种计算非线性网络雅可比矩阵的整个奇异值分布的方法,并表明在 hard-tanh 非线性网络(而不是在 ReLU 网络)中能实现独立于深度的非退化奇异值分布。实验结果表明有独立于深度的非退化奇异值分布的网络要比奇异值分布变得更宽(更高的方差)的网络快几个数量级。这是消除退化和控制整个网络奇异值分布的重要性的有力证明,而不只是该论文比较有意思。
论文:SKIP CONNECTIONS ELIMINATE SINGULARITIES

论文地址:https://openreview.net/pdf?id=HkwBEMWCZ
跳过连接(Skip connections)使得深度网络训练成为了可能,并已经成为各种深度神经架构中不可缺少的部分,但目前它并没有一个非常成功和满意的解释。在本论文中,我们提出了一种新的解释以说明跳过连接对训练深度网络的好处。训练深度网络的难度很大程度是由模型的不可识别所造成的奇异性(singularities)而引起。这样的一些奇异性已经在以前的工作中得到证明:
(i)给定层级结点中的置换对称性(permutation symmetry)造成了重叠奇异性,
(ii)消除(elimination)与对应的消除奇异性,即结点的一致性失活问题,
(iii)结点的线性依赖性产生奇异问题。这些奇异性会在损失函数的表面产生退化的流形,从而降低学习的效率。
我们认为跳过连接会打破结点的置换对称性、减少结点消除的可能性以及降低节点间的线性依赖来消除这些奇异性。此外,对于典型的初始化,跳过连接会移除这些奇异性而加快学习的效率。这些假设已经得到简化模型的实验支持,也得到了大型数据集上训练深度网络的实验支持。
原文链接:
posted on 2020-12-07 00:04 Angry_Panda 阅读(455) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号