【转载】 强化学习(十一) Prioritized Replay DQN
原文地址:
https://www.cnblogs.com/pinard/p/9797695.html
----------------------------------------------------------------------------------------
在强化学习(十)Double DQN (DDQN)中,我们讲到了DDQN使用两个Q网络,用当前Q网络计算最大Q值对应的动作,用目标Q网络计算这个最大动作对应的目标Q值,进而消除贪婪法带来的偏差。今天我们在DDQN的基础上,对经验回放部分的逻辑做优化。对应的算法是Prioritized Replay DQN。
本章内容主要参考了ICML 2016的deep RL tutorial和Prioritized Replay DQN的论文<Prioritized Experience Replay>(ICLR 2016)。
1. Prioritized Replay DQN之前算法的问题
在Prioritized Replay DQN之前,我们已经讨论了很多种DQN,比如Nature DQN, DDQN等,他们都是通过经验回放来采样,进而做目标Q值的计算的。在采样的时候,我们是一视同仁,在经验回放池里面的所有的样本都有相同的被采样到的概率。
但是注意到在经验回放池里面的不同的样本由于TD误差的不同,对我们反向传播的作用是不一样的。TD误差越大,那么对我们反向传播的作用越大。而TD误差小的样本,由于TD误差小,对反向梯度的计算影响不大。在Q网络中,TD误差就是目标Q网络计算的目标Q值和当前Q网络计算的Q值之间的差距。
这样如果TD误差的绝对值![]() |δ较大的样本更容易被采样,则我们的算法会比较容易收敛。下面我们看看Prioritized Replay DQN的算法思路。
|δ较大的样本更容易被采样,则我们的算法会比较容易收敛。下面我们看看Prioritized Replay DQN的算法思路。
2. Prioritized Replay DQN算法的建模
Prioritized Replay DQN根据每个样本的TD误差绝对值![]() |δ,给定该样本的优先级正比于
|δ,给定该样本的优先级正比于![]() |δ,将这个优先级的值存入经验回放池。回忆下之前的DQN算法,我们仅仅只保存和环境交互得到的样本状态,动作,奖励等数据,没有优先级这个说法。
|δ,将这个优先级的值存入经验回放池。回忆下之前的DQN算法,我们仅仅只保存和环境交互得到的样本状态,动作,奖励等数据,没有优先级这个说法。
由于引入了经验回放的优先级,那么Prioritized Replay DQN的经验回放池和之前的其他DQN算法的经验回放池就不一样了。因为这个优先级大小会影响它被采样的概率。在实际使用中,我们通常使用SumTree这样的二叉树结构来做我们的带优先级的经验回放池样本的存储。
具体的SumTree树结构如下图:
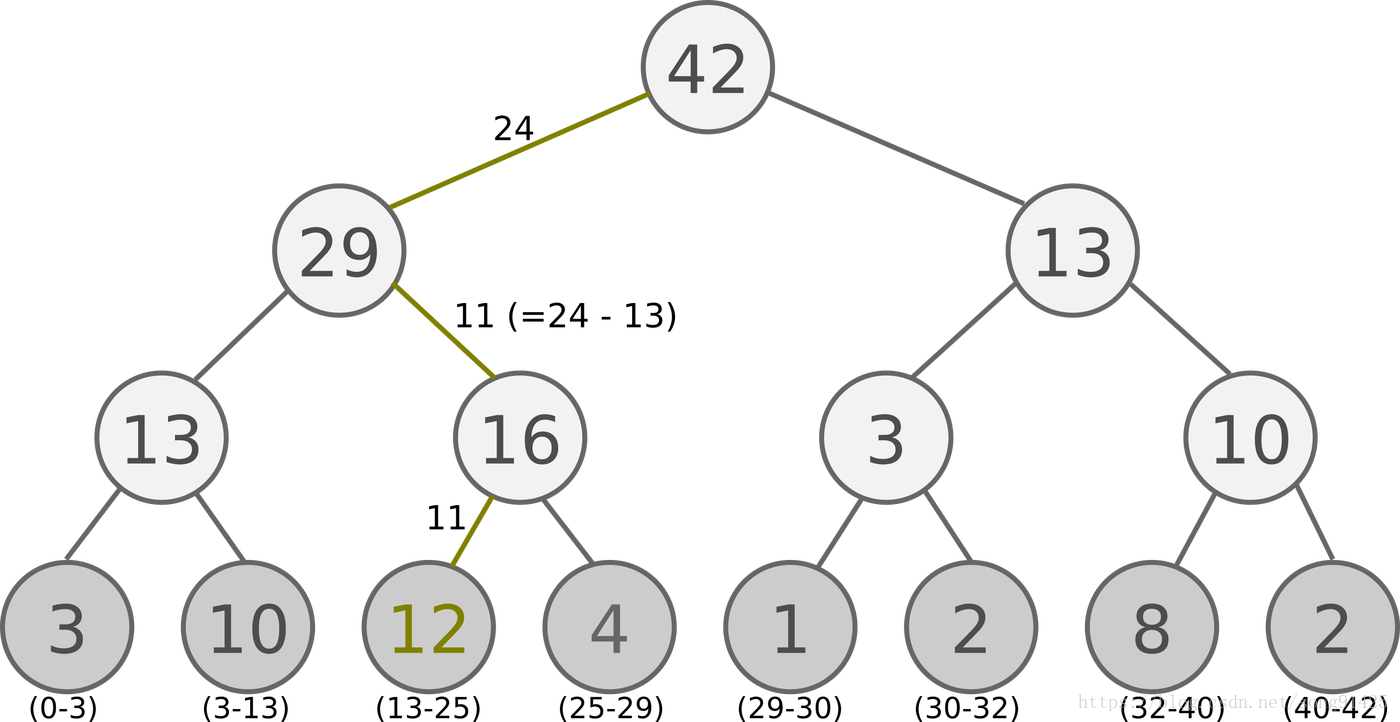
所有的经验回放样本只保存在最下面的叶子节点上面,一个节点一个样本。内部节点不保存样本数据。而叶子节点除了保存数据以外,还要保存该样本的优先级,就是图中的显示的数字。对于内部节点每个节点只保存自己的儿子节点的优先级值之和,如图中内部节点上显示的数字。
这样保存有什么好处呢?主要是方便采样。以上面的树结构为例,根节点是42,如果要采样一个样本,那么我们可以在[0,42]之间做均匀采样,采样到哪个区间,就是哪个样本。比如我们采样到了26, 在(25-29)这个区间,那么就是第四个叶子节点被采样到。而注意到第三个叶子节点优先级最高,是12,它的区间13-25也是最长的,会比其他节点更容易被采样到。
如果要采样两个样本,我们可以在[0,21],[21,42]两个区间做均匀采样,方法和上面采样一个样本类似。
类似的采样算法思想我们在word2vec原理(三) 基于Negative Sampling的模型第四节中也有讲到。
除了经验回放池,现在我们的Q网络的算法损失函数也有优化,之前我们的损失函数是:
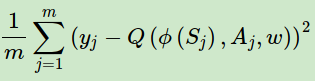
现在我们新的考虑了样本优先级的损失函数是
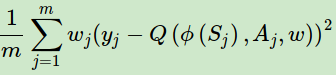

第三个要注意的点就是当我们对Q网络参数进行了梯度更新后,需要重新计算TD误差,并将TD误差更新到SunTree上面。
除了以上三个部分,Prioritized Replay DQN和DDQN的算法流程相同。
3. Prioritized Replay DQN算法流程
下面我们总结下Prioritized Replay DQN的算法流程,基于上一节的DDQN,因此这个算法我们应该叫做Prioritized Replay DDQN。主流程参考论文<Prioritized Experience Replay>(ICLR 2016)。


注意,上述第二步的f步和g步的Q值计算也都需要通过Q网络计算得到。另外,实际应用中,为了算法较好的收敛,探索率εϵ需要随着迭代的进行而变小。
4. Prioritized Replay DDQN算法流程
下面我们给出Prioritized Replay DDQN算法的实例代码。仍然使用了OpenAI Gym中的CartPole-v0游戏来作为我们算法应用。CartPole-v0游戏的介绍参见这里。它比较简单,基本要求就是控制下面的cart移动使连接在上面的pole保持垂直不倒。这个任务只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个cart的位置和速度, pole的角度和角速度,4维的特征。坚持到200分的奖励则为过关。
完整的代码参见我的github: https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/ddqn_prioritised_replay.py, 代码中的SumTree的结构和经验回放池的结构参考了morvanzhou的github代码。


def sample(self, n): b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty((n, 1)) pri_seg = self.tree.total_p / n # priority segment self.beta = np.min([1., self.beta + self.beta_increment_per_sampling]) # max = 1 min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweight if min_prob == 0: min_prob = 0.00001 for i in range(n): a, b = pri_seg * i, pri_seg * (i + 1) v = np.random.uniform(a, b) idx, p, data = self.tree.get_leaf(v) prob = p / self.tree.total_p ISWeights[i, 0] = np.power(prob/min_prob, -self.beta) b_idx[i], b_memory[i, :] = idx, data return b_idx, b_memory, ISWeights
上述代码的采样在第二节已经讲到。根据树的优先级的和total_p和采样数n,将要采样的区间划分为n段,每段来进行均匀采样,根据采样到的值落到的区间,决定被采样到的叶子节点。当我们拿到第i段的均匀采样值v以后,就可以去SumTree中找对应的叶子节点拿样本数据,样本叶子节点序号以及样本优先级了。代码如下:
def get_leaf(self, v): """ Tree structure and array storage: Tree index: -> storing priority sum / \ 2 / \ / \ 4 5 6 -> storing priority for transitions Array type for storing: [0,1,2,3,4,5,6] """ parent_idx = 0 while True: # the while loop is faster than the method in the reference code cl_idx = 2 * parent_idx + 1 # this leaf's left and right kids cr_idx = cl_idx + 1 if cl_idx >= len(self.tree): # reach bottom, end search leaf_idx = parent_idx break else: # downward search, always search for a higher priority node if v <= self.tree[cl_idx]: parent_idx = cl_idx else: v -= self.tree[cl_idx] parent_idx = cr_idx data_idx = leaf_idx - self.capacity + 1 return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
除了采样部分,要注意的就是当梯度更新完毕后,我们要去更新SumTree的权重,代码如下,注意叶子节点的权重更新后,要向上回溯,更新所有祖先节点的权重。
self.memory.batch_update(tree_idx, abs_errors) # update priority
def batch_update(self, tree_idx, abs_errors): abs_errors += self.epsilon # convert to abs and avoid 0 clipped_errors = np.minimum(abs_errors, self.abs_err_upper) ps = np.power(clipped_errors, self.alpha) for ti, p in zip(tree_idx, ps): self.tree.update(ti, p)
def update(self, tree_idx, p): change = p - self.tree[tree_idx] self.tree[tree_idx] = p # then propagate the change through tree while tree_idx != 0: # this method is faster than the recursive loop in the reference code tree_idx = (tree_idx - 1) // 2 self.tree[tree_idx] += change
除了上面这部分的区别,和DDQN比,TensorFlow的网络结构流程中多了一个TD误差的计算节点,以及损失函数多了一个ISWeights系数。此外,区别不大。
5. Prioritized Replay DQN小结
Prioritized Replay DQN和DDQN相比,收敛速度有了很大的提高,避免了一些没有价值的迭代,因此是一个不错的优化点。同时它也可以直接集成DDQN算法,所以是一个比较常用的DQN算法。
下一篇我们讨论DQN家族的另一个优化算法Duel DQN,它将价值Q分解为两部分,第一部分是仅仅受状态但不受动作影响的部分,第二部分才是同时受状态和动作影响的部分,算法的效果也很好。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
----------------------------------------------------------------------------------------------------------------
####################################################################### # Copyright (C) # # 2016 - 2019 Pinard Liu(liujianping-ok@163.com) # # https://www.cnblogs.com/pinard # # Permission given to modify the code as long as you keep this # # declaration at the top # ####################################################################### # SumTree and Memory class are referred from https://github.com/MorvanZhou # ## https://www.cnblogs.com/pinard/p/9797695.html ## ## 强化学习(十一) Prioritized Replay DQN ## import gym import tensorflow as tf import numpy as np import random from collections import deque # Hyper Parameters for DQN GAMMA = 0.9 # discount factor for target Q INITIAL_EPSILON = 0.5 # starting value of epsilon FINAL_EPSILON = 0.01 # final value of epsilon REPLAY_SIZE = 10000 # experience replay buffer size BATCH_SIZE = 128 # size of minibatch REPLACE_TARGET_FREQ = 10 # frequency to update target Q network class SumTree(object): """ This SumTree code is a modified version and the original code is from: https://github.com/jaara/AI-blog/blob/master/SumTree.py Story data with its priority in the tree. """ data_pointer = 0 def __init__(self, capacity): self.capacity = capacity # for all priority values self.tree = np.zeros(2 * capacity - 1) # [--------------Parent nodes-------------][-------leaves to recode priority-------] # size: capacity - 1 size: capacity self.data = np.zeros(capacity, dtype=object) # for all transitions # [--------------data frame-------------] # size: capacity def add(self, p, data): tree_idx = self.data_pointer + self.capacity - 1 self.data[self.data_pointer] = data # update data_frame self.update(tree_idx, p) # update tree_frame self.data_pointer += 1 if self.data_pointer >= self.capacity: # replace when exceed the capacity self.data_pointer = 0 def update(self, tree_idx, p): change = p - self.tree[tree_idx] self.tree[tree_idx] = p # then propagate the change through tree while tree_idx != 0: # this method is faster than the recursive loop in the reference code tree_idx = (tree_idx - 1) // 2 self.tree[tree_idx] += change def get_leaf(self, v): """ Tree structure and array storage: Tree index: 0 -> storing priority sum / \ 1 2 / \ / \ 3 4 5 6 -> storing priority for transitions Array type for storing: [0,1,2,3,4,5,6] """ parent_idx = 0 while True: # the while loop is faster than the method in the reference code cl_idx = 2 * parent_idx + 1 # this leaf's left and right kids cr_idx = cl_idx + 1 if cl_idx >= len(self.tree): # reach bottom, end search leaf_idx = parent_idx break else: # downward search, always search for a higher priority node if v <= self.tree[cl_idx]: parent_idx = cl_idx else: v -= self.tree[cl_idx] parent_idx = cr_idx data_idx = leaf_idx - self.capacity + 1 return leaf_idx, self.tree[leaf_idx], self.data[data_idx] @property def total_p(self): return self.tree[0] # the root class Memory(object): # stored as ( s, a, r, s_ ) in SumTree """ This Memory class is modified based on the original code from: https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py """ epsilon = 0.01 # small amount to avoid zero priority alpha = 0.6 # [0~1] convert the importance of TD error to priority beta = 0.4 # importance-sampling, from initial value increasing to 1 beta_increment_per_sampling = 0.001 abs_err_upper = 1. # clipped abs error def __init__(self, capacity): self.tree = SumTree(capacity) def store(self, transition): max_p = np.max(self.tree.tree[-self.tree.capacity:]) if max_p == 0: max_p = self.abs_err_upper self.tree.add(max_p, transition) # set the max p for new p def sample(self, n): b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty((n, 1)) pri_seg = self.tree.total_p / n # priority segment self.beta = np.min([1., self.beta + self.beta_increment_per_sampling]) # max = 1 min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweight if min_prob == 0: min_prob = 0.00001 for i in range(n): a, b = pri_seg * i, pri_seg * (i + 1) v = np.random.uniform(a, b) idx, p, data = self.tree.get_leaf(v) prob = p / self.tree.total_p ISWeights[i, 0] = np.power(prob/min_prob, -self.beta) b_idx[i], b_memory[i, :] = idx, data return b_idx, b_memory, ISWeights def batch_update(self, tree_idx, abs_errors): abs_errors += self.epsilon # convert to abs and avoid 0 clipped_errors = np.minimum(abs_errors, self.abs_err_upper) ps = np.power(clipped_errors, self.alpha) for ti, p in zip(tree_idx, ps): self.tree.update(ti, p) class DQN(): # DQN Agent def __init__(self, env): # init experience replay self.replay_total = 0 # init some parameters self.time_step = 0 self.epsilon = INITIAL_EPSILON self.state_dim = env.observation_space.shape[0] self.action_dim = env.action_space.n self.memory = Memory(capacity=REPLAY_SIZE) self.create_Q_network() self.create_training_method() # Init session self.session = tf.InteractiveSession() self.session.run(tf.global_variables_initializer()) def create_Q_network(self): # input layer self.state_input = tf.placeholder("float", [None, self.state_dim]) self.ISWeights = tf.placeholder(tf.float32, [None, 1]) # network weights with tf.variable_scope('current_net'): W1 = self.weight_variable([self.state_dim,20]) b1 = self.bias_variable([20]) W2 = self.weight_variable([20,self.action_dim]) b2 = self.bias_variable([self.action_dim]) # hidden layers h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1) # Q Value layer self.Q_value = tf.matmul(h_layer,W2) + b2 with tf.variable_scope('target_net'): W1t = self.weight_variable([self.state_dim,20]) b1t = self.bias_variable([20]) W2t = self.weight_variable([20,self.action_dim]) b2t = self.bias_variable([self.action_dim]) # hidden layers h_layer_t = tf.nn.relu(tf.matmul(self.state_input,W1t) + b1t) # Q Value layer self.target_Q_value = tf.matmul(h_layer,W2t) + b2t t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net') e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='current_net') with tf.variable_scope('soft_replacement'): self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)] def create_training_method(self): self.action_input = tf.placeholder("float",[None,self.action_dim]) # one hot presentation self.y_input = tf.placeholder("float",[None]) Q_action = tf.reduce_sum(tf.multiply(self.Q_value,self.action_input),reduction_indices = 1) self.cost = tf.reduce_mean(self.ISWeights *(tf.square(self.y_input - Q_action))) self.abs_errors =tf.abs(self.y_input - Q_action) self.optimizer = tf.train.AdamOptimizer(0.0001).minimize(self.cost) def store_transition(self, s, a, r, s_, done): transition = np.hstack((s, a, r, s_, done)) self.memory.store(transition) # have high priority for newly arrived transition def perceive(self,state,action,reward,next_state,done): one_hot_action = np.zeros(self.action_dim) one_hot_action[action] = 1 #print(state,one_hot_action,reward,next_state,done) self.store_transition(state,one_hot_action,reward,next_state,done) self.replay_total += 1 if self.replay_total > BATCH_SIZE: self.train_Q_network() def train_Q_network(self): self.time_step += 1 # Step 1: obtain random minibatch from replay memory tree_idx, minibatch, ISWeights = self.memory.sample(BATCH_SIZE) state_batch = minibatch[:,0:4] action_batch = minibatch[:,4:6] reward_batch = [data[6] for data in minibatch] next_state_batch = minibatch[:,7:11] # Step 2: calculate y y_batch = [] current_Q_batch = self.Q_value.eval(feed_dict={self.state_input: next_state_batch}) max_action_next = np.argmax(current_Q_batch, axis=1) target_Q_batch = self.target_Q_value.eval(feed_dict={self.state_input: next_state_batch}) for i in range(0,BATCH_SIZE): done = minibatch[i][11] if done: y_batch.append(reward_batch[i]) else : target_Q_value = target_Q_batch[i, max_action_next[i]] y_batch.append(reward_batch[i] + GAMMA * target_Q_value) self.optimizer.run(feed_dict={ self.y_input:y_batch, self.action_input:action_batch, self.state_input:state_batch, self.ISWeights: ISWeights }) _, abs_errors, _ = self.session.run([self.optimizer, self.abs_errors, self.cost], feed_dict={ self.y_input: y_batch, self.action_input: action_batch, self.state_input: state_batch, self.ISWeights: ISWeights }) self.memory.batch_update(tree_idx, abs_errors) # update priority def egreedy_action(self,state): Q_value = self.Q_value.eval(feed_dict = { self.state_input:[state] })[0] if random.random() <= self.epsilon: self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / 10000 return random.randint(0,self.action_dim - 1) else: self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / 10000 return np.argmax(Q_value) def action(self,state): return np.argmax(self.Q_value.eval(feed_dict = { self.state_input:[state] })[0]) def update_target_q_network(self, episode): # update target Q netowrk if episode % REPLACE_TARGET_FREQ == 0: self.session.run(self.target_replace_op) #print('episode '+str(episode) +', target Q network params replaced!') def weight_variable(self,shape): initial = tf.truncated_normal(shape) return tf.Variable(initial) def bias_variable(self,shape): initial = tf.constant(0.01, shape = shape) return tf.Variable(initial) # --------------------------------------------------------- # Hyper Parameters ENV_NAME = 'CartPole-v0' EPISODE = 3000 # Episode limitation STEP = 300 # Step limitation in an episode TEST = 5 # The number of experiment test every 100 episode def main(): # initialize OpenAI Gym env and dqn agent env = gym.make(ENV_NAME) agent = DQN(env) for episode in range(EPISODE): # initialize task state = env.reset() # Train for step in range(STEP): action = agent.egreedy_action(state) # e-greedy action for train next_state,reward,done,_ = env.step(action) # Define reward for agent reward = -1 if done else 0.1 agent.perceive(state,action,reward,next_state,done) state = next_state if done: break # Test every 100 episodes if episode % 100 == 0: total_reward = 0 for i in range(TEST): state = env.reset() for j in range(STEP): env.render() action = agent.action(state) # direct action for test state,reward,done,_ = env.step(action) total_reward += reward if done: break ave_reward = total_reward/TEST print ('episode: ',episode,'Evaluation Average Reward:',ave_reward) agent.update_target_q_network(episode) if __name__ == '__main__': main()
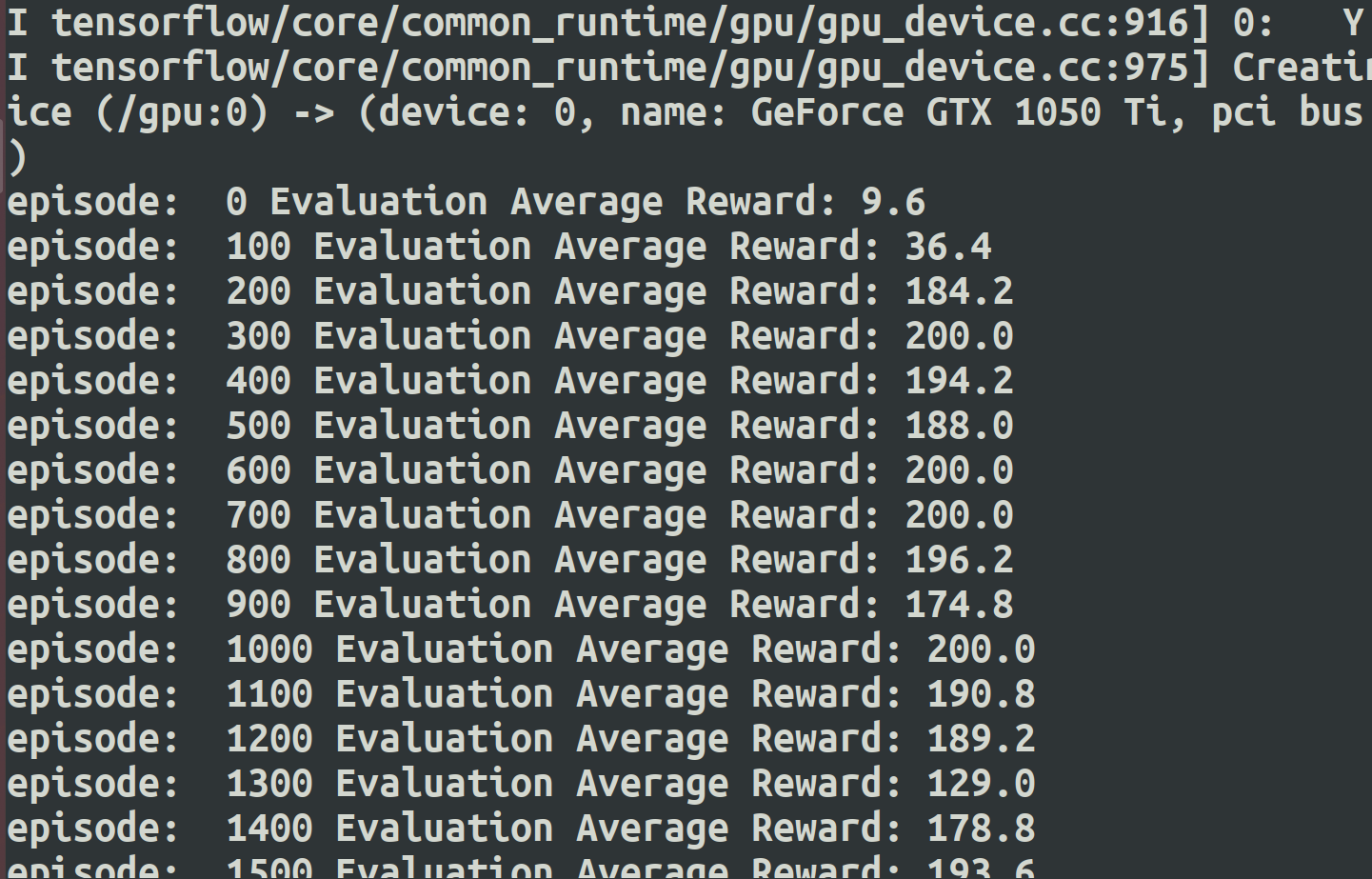
ps: prioritized replay DQN 运算速度奇慢,大约能有数倍分之前面的DQN算法,但是效果看来却有提升。
posted on 2019-04-10 09:56 Angry_Panda 阅读(998) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号