强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)
强化学习入门最经典的数据估计就是那个大名鼎鼎的 reinforcement learning: An Introduction 了, 最近在看这本书,第一章中给出了一个例子用来说明什么是强化学习,那就是tic-and-toc游戏, 感觉这个名很不Chinese,感觉要是用中文来说应该叫三子棋啥的才形象。

这个例子就是下面,在一个3*3的格子里面双方轮流各执一色棋进行对弈,哪一方先把自方的棋子连成一条线则算赢,包括横竖一线,两个对角线斜连一条线。
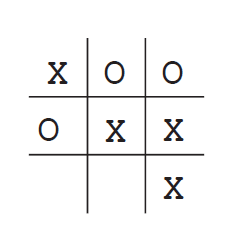

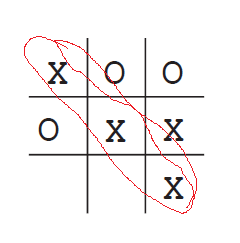
上图,则是 X 方赢,即:
reinforcement learning 的对应代码地址为:
https://github.com/ShangtongZhang/reinforcement-learning-an-introduction
该代码虽然很好,但是看起来较费力,于是自己就该它的基础上加了些注释并把结构进行了改动,具体代码如下:
源码地址:(本文给出的结构重建,注释版)
https://files.cnblogs.com/files/devilmaycry812839668/tic_tac_toe_code.zip
关于算法的解释可以具体参见书中的介绍,Reinforcement Learning:An Introduction 第一章
关于这个代码的,或者说是算法的设计主要是为了解释什么是时序差分的强化学习。
每一种状态都用一个值来表示,并用一个hash码表示,
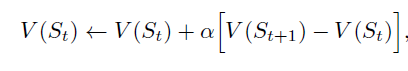
St 是此刻的棋盘状态值, St+1 是下一时刻的棋盘状态值。但是, 如果St状态到St+1 状态是因为自方进行策略探索而选择的不是最优的下一状态的动作,那么不进行此次计算。
状态值的变化树结构如下图:
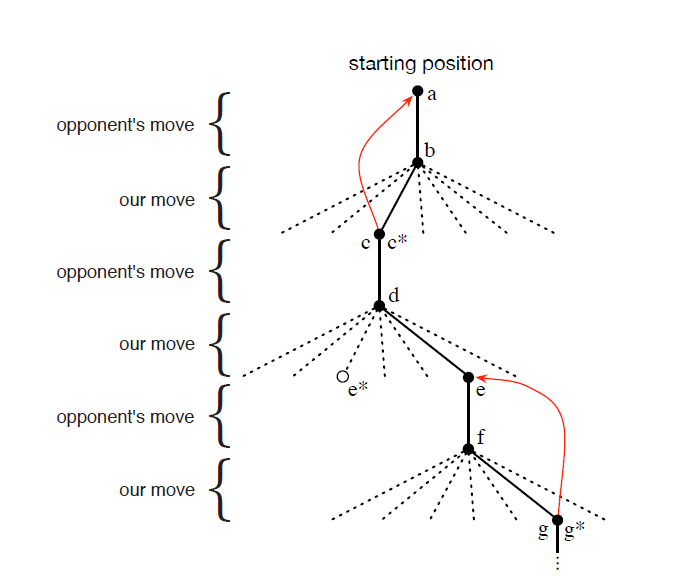
由 d 状态 到 e* 状态是此时可以选择的最优状态,但是我们选择了进入 e 状态的操作,这就是策略的探索操作。
具体的算法思想参照 reinforcement learning: An Introduction 原书。
==========================================================
目录结构如下图:
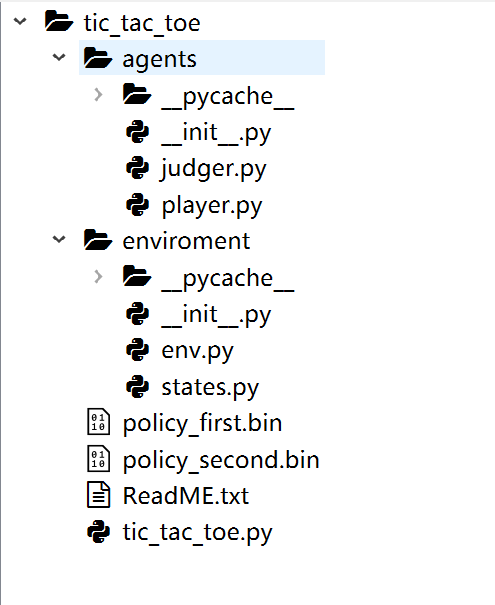
tic_tac_toe.py 是代码的主文件,需要运行该代码。
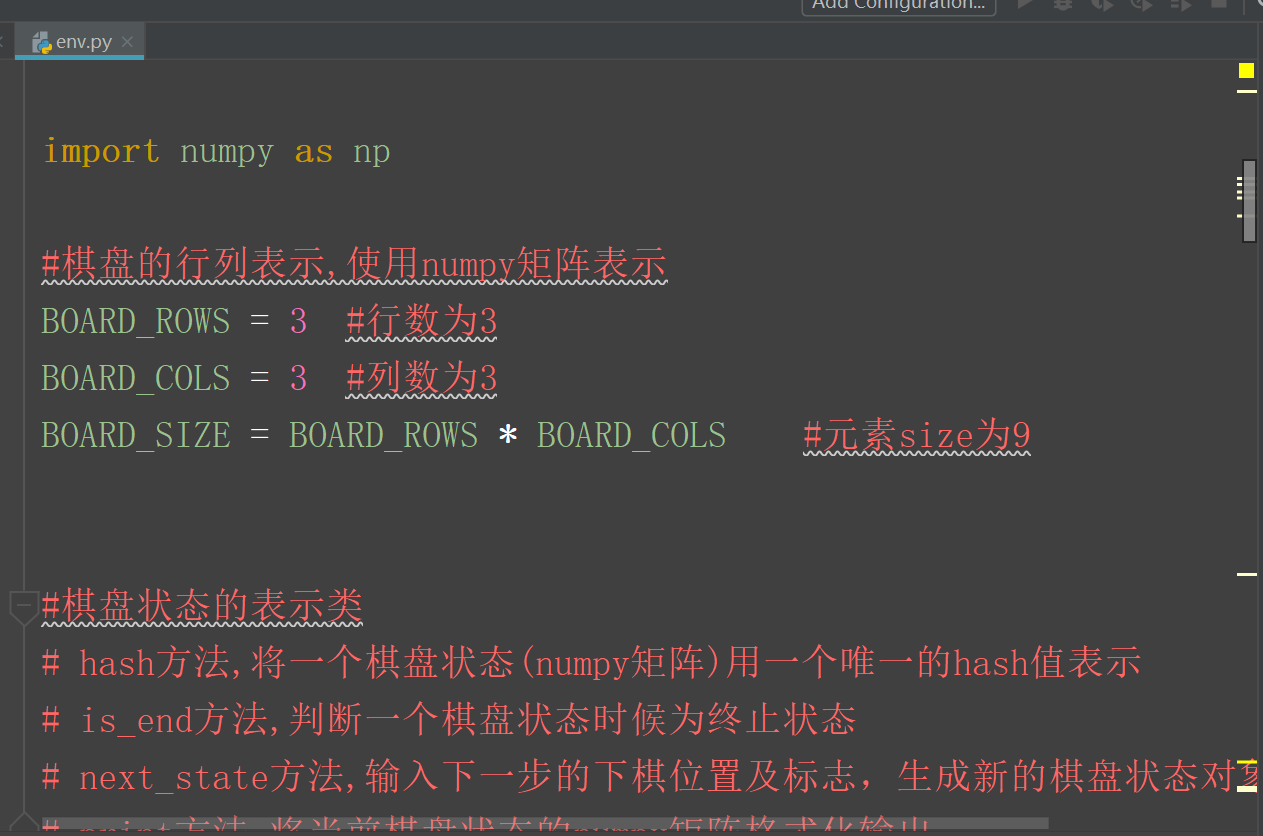
enviroment 文件夹中放的是 关于棋盘状态的类文件代码,和环境初始化的代码。

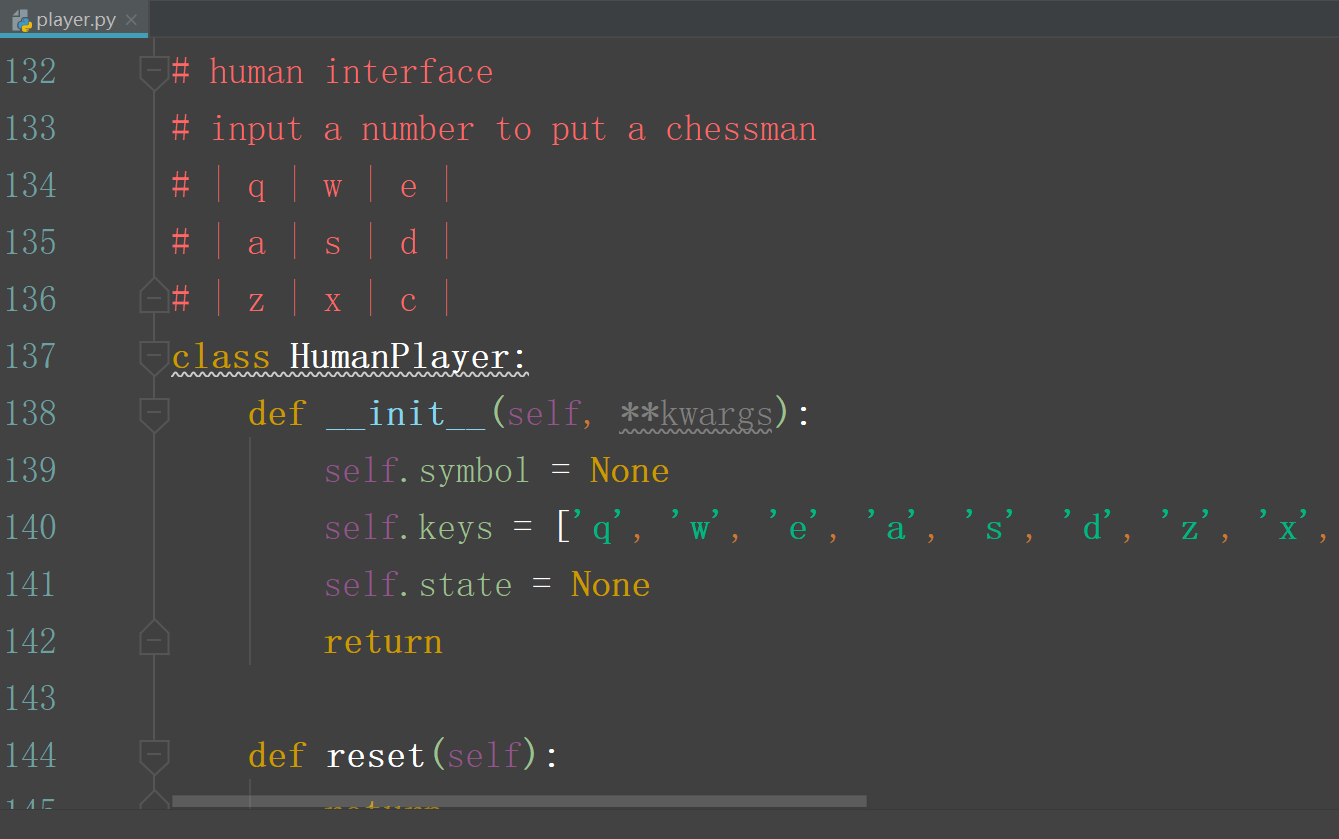
agents 文件夹中放的是 具体的下起策略中agent的代码:

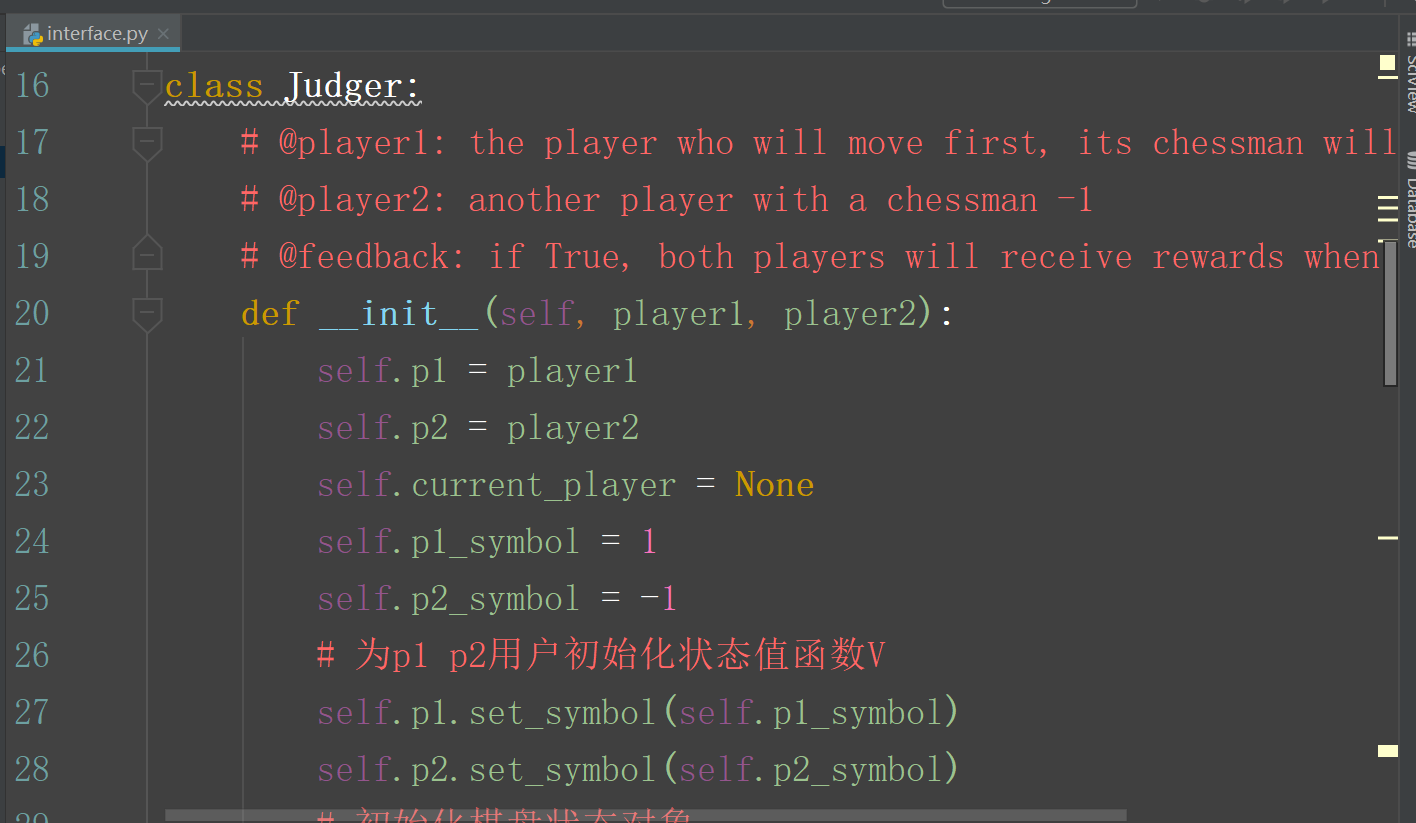
judger.py 中的代码是 agent 代码和主程序的接口文件:
主文件 tic_toe_tac.py
--------------------------------------------------------------------------
代码做了一下更新,上传网址:
https://gitee.com/devilmaycry812839668/tic_tac_toe
对书中给出的方法进行一些分析:在下棋情况下一个MDP过程可以下图表示:

可以看到黑框部分是symbol=+1选手下棋过程,选手+1在状态S0时下棋,下棋动作为a0, 下棋后的状态为S 。红色框部分是symbol=-1选手下棋过程,选手-1在状态S时下棋,下棋动作为a, 下棋后的状态为 S' 。
上面这个描述的图可以看做是选手+1和-1的一个轮流下棋的过程。
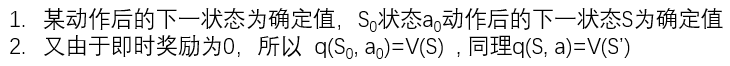
使用采样方法对一个变量进行评估的时候可以采样 “近因指数加权平均法”:
比如对一个变量 X 进行评估,现有对变量X的评估记作 Xold, 新一次对变量X的采样记为Xnew, 新一次对变量X采样后更新的变量X记为Xupdate,在下一次对变量X进行采样评估时这个Xupdate就成了下一采样中的Xold 。具体的 “近因指数加权平均法”如下:
while True: # 不断的对变量X 进行采样 Xupdate=Xold+step_size*(Xnew-Xold) Xold=Xupdate
其中,step_size 是步长,也可以看做是学习率。
Xnew-Xold 可以看做是新采样的值与旧值的差。在强化学习中,这一项也经常以TD_error的形式出现,即TD_error=新采样值-原值, 其中新采样值一般按时序展开,
如 TD_error=r+q(s',a')-q(s,a) 。
在Q-learning中, TD_error=r+max{a' }q(s', a')-q(s, a) ,
在Sarsa中, TD_error=r+{epsilon-greedy}q(s', a')-q(s, a) 。
在Q-learning中用 r+max{a}q(s', a') 作为对q(s, a)的一次采样, 在Sarsa中则使用 {epsilon-greedy}q(s', a') 作为对q(s, a)的一次采样。
因为在Q-learning 和 Sarsa 中我们是无法直接对q(s, a)进行采样的,我们只能对reward进行采样, 而且对所有的动作值函数,即q值有初始值。
不论是Q-learning还是Sarsa , 状态S选择动作a后跳转到的状态均记作S' , 不同的是在S' 处选择的评估动作是怎么选的。
在TD_error中:
TD_error=r+q(s',a')-q(s,a)
r+q(s', a')为什么能替代q(s, a)呢?因为根据贝尔曼方程可知 q(s, a)= Σ P( s' |s, a )*(r+V(s')) =Es'|s,a( r+V( s' ) ) ,
虽然采用 “近因指数加权平均法” 对q(s, a)进行采样评估是有偏的, 但是根据“近因指数加权平均法”用r+V( s' ) 来替代直接采样q(s, a) 是可以近似看做对q(s, a)的采样评估的。但是这里又出现了一个问题,就是 V( S' ) 其实也是未知的,虽然此时已经有了对q(s', a') 的初始值, 那能否使用q(s', a') 来替代V(S') 呢, 这里Sarsa方法做的就是比较易懂的,在Sarsa中q(s', a')的动作 a' 是 S' 状态下依据 epsilon-greedy 策略选择的, 而根据贝尔曼方程在这样策略的选择下 q(s', a')的期望正好等于V(S') 。
但是Q-learning里面的V(S') 是使用 r+ max{a'}q(s' , a' ) 来替代的,这是因为根据贝尔曼最优方程 在最优策略下 V(S' )= max{a'}q(s' , a' ) , 所有采用这样的替代方法目标是在最终停止迭代训练后得到的确定性最优策略中真实的V(S' )和 q(s' , a' )的关系就是满足 V(S' )= max{a'}q(s' , a' ) 的。
实际中的效果应该是Q-learning的收敛速度快于Sarsa , 不过理论层面上只能保证表格法的情况下Sarsa和Q-learning是一定收敛的,在函数近似的方法情况下是不能在理论层面保证Sarsa和Q-learning是收敛的。不论是Sarsa还是Q-learning设计的出发点或者说是假设或目的都是最终可以收敛的,因为只有这样才能保证在不断的值迭代过程中对策略的更新 能满足在Sarsa中 epsilon-greedy 策略选择的 q(s', a')的期望等于V(S') ,Q-learning中V(S' )= max{a'}q(s' , a' ) 关系的,但是在Sarsa和Q-learning中对q(s' , a' )本身也是未知的,正如对q(s, a)的评估一样也需要将q(s', a' )展开进行评估,这样就容易陷入一个死循环中,就是说对一个变量的评估需要另一个待评估的变量,这是一个连锁的依赖关系,没有正确的q(s', a' )是难以正确评估出正确的q(s, a), 而q(s', a' )需要另一个未知的待估计的变量来评估,这一点在Sarsa和Q-learning都是一样的。这方面的研究文献还是很多的,自己也不太理解,所以上面的个人理解也不知道对错。
-------------------------------------------------
再次回到本项目中,如下图:( 假设现在的agent是symbol=+1的那一方player )

再依据“近因指数加权平均法”也就有了下面的更新公式:(其中 V(St+1 ) 的 St+1 是后继状态中值函数最大的状态 )
不过本项目中的更新方法又和Sarsa和Q-learning中的不太一样:
TD_error大致框架的更新方法:
采样q(s,a)=r+q(s',a')
TD_error=采样q(s,a)-原q(s,a)=r+q(s',a') - q(s,a)
更新q(s,a)=原q(s,a)+step_size*TD_error= q(s,a) + step_size*( r+q(s',a') - q(s,a) )
Sarsa 方法:
采样策略为epsilon-greedy策略,也就是说q(s,a)的选择是通过epsilon-greedy策略的,但是对q(s',a')的选择也是通过epsilon-greedy策略的。
Q方法:
采样策略为epsilon-greedy策略,也就是说q(s,a)的选择是通过epsilon-greedy策略的,但是对q(s',a')的选择也是通过贪婪greedy策略的,
q(s',a')这一项在这里是max{a}q(s', 'a) 。
本项目:
本项目的代码也是使用TD_error框架,但是和Saras方法和Q_learning方法还不完全相同,Saras和Q-learning和本项目都是在采样时采用epsilon-greedy策略,在更新时Saras是采用epsilon-greedy策略,Q-learning采用greedy策略, 而本项目在更新时以(1-epsilon)概率使用greedy策略更新,以epsilon概率不进行策略更新。
在对手下棋的部分也需要对所经历状态的值函数进行学习:
选手+1 同样也对选手-1下棋过程所经历的状态进行更新计算,即上图的红色框内部分。由于红色框内部分为对手下棋的部分可以看到状态S的下一状态S' 是受对手策略所决定的,又因为从S状态经过对手下棋后跳转到S' 状态不会受到任何即时奖励, V(S)等于对手策略P与V(S' )的加权和, 也就是说V(S)的评估可以通过对V(S' )的采样并根据“近因指数加权平均法” 可以获得,也就是 V(S)=V(S)+step_size*( V(S' )-V(S) ) 。
本项目中的更新方法和Q-learning还是最为相近的,不同的在于Q-learning中每一步按策略选择动作后都会进行评估改进,而本项目是对一个片段采样结束后再从后向前逐个改进历史轨迹中状态的状态值,正因为不是Q-learning 中每一步选择动作后就更新策略而是把轨迹中的历史状态保存后再逐个更新策略,因此在使用贪婪策略选择动作的状态才对其进行更新,而使用epsilon-greedy方法选择动作的状态不对其进行更新,当然这时我们也不知道该状态的贪婪策略所该选择的状态是哪个,而这需要再单独计算一下。
而对手所下棋的过程中, V(S)等于对手策略P与V(S' )的加权和, 也就是说V(S)的评估可以通过对V(S' )的采样并根据“近因指数加权平均法” 可以获得,也就是 V(S)=V(S)+step_size*( V(S' )-V(S) ) 。
-----------------------------------------------
Q-learning
对本项目中的 agents包中的player.py 中的backup函数进行修改,并加入q函数, 则可以实现完全的Q-learning学习方式,如下:
# update value estimation def backup(self): # for debug # print('player trajectory') # for state in self.states: # state.print() # 状态值V的更新函数 # player所有遍历状态的hash值集合 self.states_hash = [state.hash() for state in self.states] for i in reversed(range(len(self.states_hash) - 1)): pre_hash = self.states_hash[i] next_hash = self.states_hash[i+1] # 根据贝尔曼最优方程 采样V(S)用 max q(s,a) 替代, max q(s,a) = r+V(S') ,r=0,采样V(S)可用 max V(S') 替代 # 采样V(S)=max V(S') # v(s)=v(s)+step_size*(reward+v(s')-v(s)) 对v(s)进行更新 # td_error = self.greedy[i] * (0+self.estimations[next_hash] - self.estimations[pre_hash]) if self.greedy[i]==True: td_error = self.greedy[i] * (self.estimations[next_hash] - self.estimations[pre_hash]) else: n_v=self.q(self.states[i]) td_error = (n_v - self.estimations[pre_hash]) # td_error = self.greedy[i] * (self.estimations[next_hash] - self.estimations[pre_hash]) self.estimations[pre_hash] += self.step_size * td_error
def q(self, state): """ """ # 下一步的可能状态,及对应的下棋位置 next_states_hash = [] next_positions = [] for i in range(BOARD_ROWS): for j in range(BOARD_COLS): if state.data[i, j] == 0: # 选择的新下棋位置 next_positions.append([i, j]) # 产生的新棋盘状态 next_states_hash.append(state.next_state(i, j, self.symbol).hash()) # 采用贪婪greedy方法选取动作,即V值最大的动作 # values元素为状态V值和动作位置构成的二元组 values = [] for hash in next_states_hash: values.append(self.estimations[hash]) return max(values)
-------------------------------------------------
Sarsa
而把原项目改为Sarsa 方法则更为简单一些,对本项目中的 agents包中的player.py 模块中的backup函数进行修改即可:
# update value estimation def backup(self): # for debug # print('player trajectory') # for state in self.states: # state.print() # 状态值V的更新函数 # player所有遍历状态的hash值集合 self.states_hash = [state.hash() for state in self.states] for i in reversed(range(len(self.states_hash) - 1)): pre_hash = self.states_hash[i] next_hash = self.states_hash[i+1] # 根据贝尔曼最优方程 采样V(S)用 max q(s,a) 替代, max q(s,a) = r+V(S') ,r=0,采样V(S)可用 max V(S') 替代 # 采样V(S)=max V(S') # v(s)=v(s)+step_size*(reward+v(s')-v(s)) 对v(s)进行更新 # td_error = self.greedy[i] * (0+self.estimations[next_hash] - self.estimations[pre_hash]) td_error = (self.estimations[next_hash] - self.estimations[pre_hash]) self.estimations[pre_hash] += self.step_size * td_error
-----------------------------------
注:
有一点需要注意的是本项目中的问题是有限状态的强化学习问题,而我们解决的方法不论是原项目中的还是后改的Q-learning和Sarsa 方法都是属于表格法的。由于是表格法所以Q-learning和Sarsa法最终都是可以收敛的(当然我们还需要在训练过程中不断减少epsilon-greedy策略的epsilon探索概率,这样才会最终得到确定性策略),不过本项目采用了一个最为常用也是最为简单的方法得到确定性策略,那就是将Q-leanring或Sarsa或本项目得到的不确定性的最终策略转化为确定性策略(就是在每个状态下动作选择不按照学习到的epsilon-greedy策略来选择而是按照贪婪greedy策略来选择)。
表格型的强化学习问题收敛,非表格型强化学习问题未必收敛。
这方面的研究文献还是很多的,自己也不太理解,所以上面的个人理解也不知道对错。
本文中讨论的强化学习方法都是在折扣率为1.0的情况下。
------------------------------------
posted on 2019-01-10 10:02 Angry_Panda 阅读(1330) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号