PyTorch 数据集类 和 数据加载类 的一些尝试
最近在学习PyTorch, 但是对里面的数据类和数据加载类比较迷糊,可能是封装的太好大部分情况下是不需要有什么自己的操作的,不过偶然遇到一些自己导入的数据时就会遇到一些问题,因此自己对此做了一些小实验,小尝试。
下面给出一个常用的数据类使用方式:
def data_tf(x): x = np.array(x, dtype='float32') / 255 # 将数据变到 0 ~ 1 之间 x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到 x = x.reshape((-1,)) # 拉平 x = torch.from_numpy(x) return x from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据 train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换 test_set = MNIST('./data', train=False, transform=data_tf, download=True)
其中, data_tf 并不是必须要有的,比如:
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据 train_set = MNIST('./data', train=True, download=True) # 载入数据集,申明定义的数据变换 test_set = MNIST('./data', train=False, download=True)
这里面的MNIST类是框架自带的,可以自动下载MNIST数据库, ./data 是指将下载的数据集存放在当前目录下的哪个目录下, train 这个属性 True时 则在 ./data文件夹下面在建立一个 train的文件夹然后把下载的数据存放在其中, 当train属性是False的时候则把下载的数据放在 test文件夹下面。
划线部分是老版本的PyTorch的处理方式, 最近试了一下最新版本 PyTorch 1.0 , train为True的时候是把数据放在 ./data/processed 文件夹下面, 命名为training.pt , 为False 的时候则放在 ./data/processed 文件夹下面, 命名为test.pt 。
这时候就出现了一个问题, 如果你使用的数据集不是框架自带的那么如何使用数据类呢,这个时候就要使用 pytorch 中的 Dataset 类了。
from torch.utils.data import Dataset
我们需要重写 Dataset类, 需要实现的方法为 __len__ 和 __getitem__ 这两个内置方法, 这里可以看出其思想就是要重写的类需要支持按照索引查找的方法。
这里我们还是举个例子:
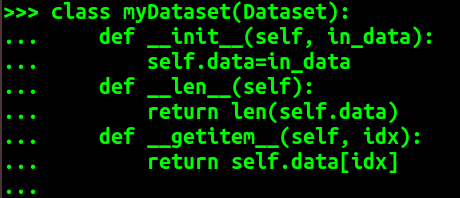


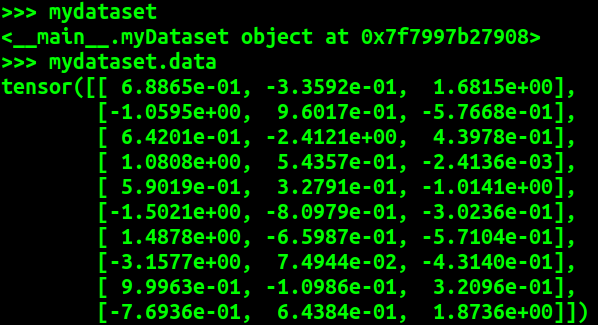
从这个例子可以看出 mydataset就是我们自定义的 myDataset 类生成的自定义数据类对象。我们可以在myDataset类中自定义一些方法来对需要的数据进行处理。
为说明该问题另附加一个例子:
from torch.utils.data import Dataset #需要在pytorch中使用的数据 data=[[1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3], [5.1, 5.2, 5.3]] class myDataset(Dataset): def __init__(self, indata): self.data=indata def __len__(self): return len(self.data) def __getitem__(self, idx): return self.data[idx] mydataset=myDataset(data)
那么又来了一个问题,我们不重写 Dataset类的话可不可以呢, 经过尝试发现还真可以,如下:

又如:



由这个例子可以看出数据类对象可以不重写Dataset类, 只要具备 __len__ __getitem__ 方法就可以。而且从这个例子我们可以看出 DataLoader 是一个迭代器, 如果shuffle 设置为 True 那么在每次迭代之前都会重新排序。
同时由上面两个例子可以看出 DataLoader类会把传入的数据集合中的数据转化为 torch.tensor 类型, 当然是采用默认的 DataLoader类中转化函数 transform的情况下。
这也就是说 DataLoader 默认的转化函数 transform操作为 传入的[ [x, x, x], [y, y, y] ] 输出的是 [ tensor([x, x, x]), tensor([y, y, y]) ] ,
传入的是 tensor([ [x, x, x], [y, y, y] ]) 输出的是 tensor([ tensor([x, x, x]), tensor([y, y, y]) ] ), (这个例子是在 batch_size=2 的情况)。
综上,可知 其实 Dataset类, 和 DataLoader类其实在pytorch 计算过程中都不是一定要有的, 其中Dataset类是起一个规范作用,意义在于要人们对不同的类型数据做一些初步的调整,使其支持按照索引读取,以使其可以在 DataLoader中使用。
DataLoader 是一个迭代器, 可以方便的通过设置 batch_size 来实现 batch过程,transform则是对数据的一些处理。
---------------------------------------------------------------------------------------------------
上述内容更正:
import torch import numpy as np from torch.utils.data import Dataset from torch.utils.data import DataLoader #需要在pytorch中使用的数据 data=[[1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3], [5.1, 5.2, 5.3]] class myDataset(Dataset): def __init__(self, indata): self.data=indata def __len__(self): return len(self.data) def __getitem__(self, idx): return self.data[idx] mydataset=myDataset(data) train_data=DataLoader(mydataset, batch_size=3, shuffle=True) print("上文的错误操作:") for i in train_data: print(i) print('-'*30) print('again') for i in train_data: print(i) print('-'*30) ######################################### data=np.array(data) data=torch.from_numpy(data) mydataset=myDataset(data) train_data=DataLoader(mydataset, batch_size=3, shuffle=True) print("修正后的正确操作:") for i in train_data: print(i) print('-'*30) print('again') for i in train_data: print(i) print('-'*30)
(base) devil@devilmaycry:/tmp$ python w.py 上文的错误操作: [tensor([3.1000, 4.1000, 5.1000], dtype=torch.float64), tensor([3.2000, 4.2000, 5.2000], dtype=torch.float64), tensor([3.3000, 4.3000, 5.3000], dtype=torch.float64)] ------------------------------ [tensor([1.1000, 2.1000], dtype=torch.float64), tensor([1.2000, 2.2000], dtype=torch.float64), tensor([1.3000, 2.3000], dtype=torch.float64)] ------------------------------ again [tensor([3.1000, 5.1000, 1.1000], dtype=torch.float64), tensor([3.2000, 5.2000, 1.2000], dtype=torch.float64), tensor([3.3000, 5.3000, 1.3000], dtype=torch.float64)] ------------------------------ [tensor([2.1000, 4.1000], dtype=torch.float64), tensor([2.2000, 4.2000], dtype=torch.float64), tensor([2.3000, 4.3000], dtype=torch.float64)]
------------------------------
修正后的正确操作: tensor([[2.1000, 2.2000, 2.3000], [1.1000, 1.2000, 1.3000], [3.1000, 3.2000, 3.3000]], dtype=torch.float64) ------------------------------ tensor([[4.1000, 4.2000, 4.3000], [5.1000, 5.2000, 5.3000]], dtype=torch.float64) ------------------------------ again tensor([[5.1000, 5.2000, 5.3000], [4.1000, 4.2000, 4.3000], [3.1000, 3.2000, 3.3000]], dtype=torch.float64) ------------------------------ tensor([[2.1000, 2.2000, 2.3000], [1.1000, 1.2000, 1.3000]], dtype=torch.float64) ------------------------------
可以看出 传入到 Dataset 中的对象必须是 torch 类型的 tensor 类型, 如果传入的是list则会得出错误结果。
-----------------------------------------------------------------------------------------------------
补充:
之所以发现上面的这个错误,是因为发现了下面的代码:
import numpy as np from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据 from torch.utils.data import DataLoader #from torch.utils.data import Dataset def data_tf(x): x = np.array(x, dtype='float32') / 255 x = (x - 0.5) / 0.5 # 数据预处理,标准化 x = x.reshape((-1,)) # 拉平 x = torch.from_numpy(x) return x #Dataset # 重新载入数据集,申明定义的数据变换 train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True) test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True) train_data = DataLoader(train_set, batch_size=64, shuffle=True) test_data = DataLoader(test_set, batch_size=128, shuffle=False)
从上面的 data_tf 函数中我们发现, Dataset对象返回的是 torch 的 tensor 对象。
posted on 2018-12-14 22:56 Angry_Panda 阅读(3084) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号