针对粗粒度架构的粗粒度调研
Big Picture
Reconfigurable: CGRA vs FPGA
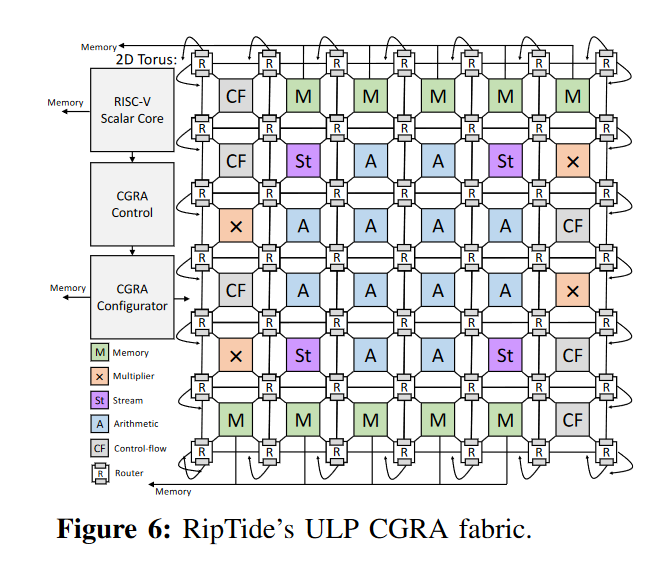
从架构来看 CGRA(Coarse-Grained Reconfigurable Architecture) 和 FPGA 非常类似,Memory、PE 以及 NoC 片上网络。调研反馈实际二者边界也是逐渐模糊:
| 硬件 | CGRA | FPGA |
|---|---|---|
| PE 粒度 | Arithemtic | Logic(LE), Arithemtic(Logic Element), Core(PS) |
| 重构程序 | 软件语言 | 硬件语言(RTL), 软件语言(HLS) |
从粒度和重构程序上,FPGA 对 CGRA 是全覆盖,或者说 FPGA = CGRA + PL,CGRA 是缩小了应用领域的 FPGA,放弃了 RTL level 专注于软件语言。从这个层面来说 CGRA 的比较对象应是 CPU 或是 GPU,而方法论和 FPGA 重叠。
缩小到底能够带来多大的提升?这个问题不太好回答,CGRA 的 application domain 还是太大了,日后可选取一个具体领域切入。
Tool Flow
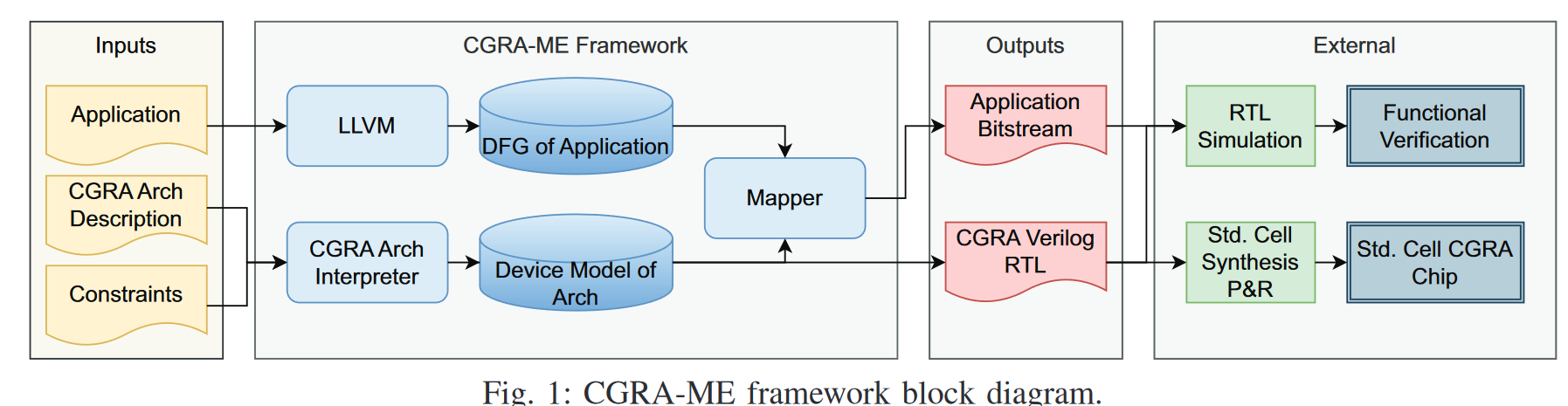
选取 CGRA-ME 的 flow [1]
输入文件
- Application: 描述软件,一般是 C / 汇编
- CGRA Arch Description:描述硬件,包含架构组成和参数,只有 CGRA 和 Morpher [2] 支持更改组成
- Constraints: 描述 Mapping 过程的限制,但是我在 CGRA-ME 2.0 的代码中没找到这部分的对应实现
输出文件
- RTL
- Application Bitstream:描述 Mapping 后的结果
流程图上可见,mapper 的结果不影响 RTL 生成,RTL 只受 Arch Description 影响。类似 FPGA tool chain 将整个 flow 泛化了,如果是固定某种型号的 CGRA 可以将这一条路砍掉剩下的只作为 compiler 使用。
Application 一般会按照一个公认的 benchmark 评估结果,常见的 benchmark 包含 FFT、conv 、ADPCM coder/decoder 等。
Graph-based Accelerator
Application 会经过编译转为 DFG,可以说 CGRA 是 spatial-computing 的 DFG-processor。近期 AI 领域 graph processor 以及 dataflow accelerator 重新进入视线 [3],dataflow 和 graph processor 之间没有必然联系,CGRA 既有 dynamic scheduling 也有 static scheduling 方法。
Reconfigurable Mapping 经典问题
由于 mapping 的搜索空间非常大,调研感觉 CGRA 领域研究核心在于 mapping 方法,这么说方法论和编译器领域更接近了。这里挑循环和 control flow这俩个经典问题展开太编译器了。
Loop in CGRA
Loop 由 loop bound 和 loop body 组成,如果包含多个 loop 循环叫做嵌套循环(nested loop)。根据循环各个部分的性质可以进一步细分:
- Loop bounds
- Irregular inner loop : 边界是动态的
- Affine inner loop : 可以用仿射变换表示边界,如之前 blog 多面体模型表示介绍[4]
- Loop Body 和循环的位置
- Imperfectly nested loop : 在 nested loop 之间还有 loop body
- Perfectly nested loop:在 nested loop 之间没有 loop body
- Loop Body 多个语句之间的关系
- Doall loop: loop body 内部数据和其余循环无关,比如循环体内 a[i] 的值不依赖 a[i-1]
- Doacross loop: 有关
依次分类,timeloop 针对 MAC 的循环建模属于 affine inner + prefectly nested + doall loop,非常简单的特例。怪不得编译器领域的对于 loop 的工作这么多,而 DNN 只需要一篇 timeloop 就基本理清了。反过来也说明如果要进一步发挥 CGRA 的性能,就得增大通过涵盖更多算子增加软件复杂度。
CGRA 里处理 loop 的常用方法是 module scheduling[5],核心在于根据硬件规格和算法依赖调整循环之间的间隔时间(II, initiation interval),具体来说,先求解间隔的边界值,再通过某种方法在剩余空间里搜索。边界值是求解 MII(minimum initiation interval),通过取硬件资源的 ResMII 和软件依赖的 RecMII 的最大值得到,ResMII 好求,而 RecMII 要解析图就更加麻烦了,常见包括 Enumeration、Shortest Path、Path Algebra 等算法[6]。
Control Flow
分支预测一种逻辑便是和 CPU 一样基于 prediction 方法,而 CGRA 执行这种方法的性能优势劣势还需要进一步分析。
因为 CGRA 属于 sptial computing,可以采用与 VLIW brach splitting 类似方法将不同分支映射到空间上。这么做分支逻辑就进一步映射到路由单元上,路由逻辑常常涉及到 \(\phi\) function,在编译器里常用的 permitive。RipTide[7] 提及这种方式会损失能耗,而采用 \(\phi^{-1}\) 的 steering control 更加节能,这二者似乎又和 control flow、dataflow 有一定的耦合关系,待后续调研。
前几年 DNN 模型的大都都是 determinstic model,没有什么 control flow,不过近期新模型确实可能有研究 control flow 的空间,比如复杂残差连接的数据依赖、MoE 的专家选择、LLM decodeing phase 的 speculation ,但 AI 面临问题在于数据量太大了,基本不可能完整映射到硬件上,限制了 spatial computing control flow 的空间,更多还是在 memory 上面,找到一个合适的切入点得好好思考。
CGRA-ME 2.0: A Research Framework for Next-Generation CGRA Architectures and CAD ↩︎
Morpher: An Open-Source Integrated Compilation and Simulation Framework for CGRA ↩︎
可见从前 blog 《从 GPU 到 SambaNova,spatial computing 的数据流解决方案》,但当时没有分清 graph accelerator 和 data flow 之间的关系 https://www.cnblogs.com/devil-sx/p/18476553 ↩︎
Polyhedral Model: DNN Nested Loop 的实现模型 https://www.cnblogs.com/devil-sx/p/18209577 ↩︎
DRESC: a retargetable compiler for coarse-grained reconfigurable architectures ↩︎
可重构计算,魏少军,刘雷波,尹首一 ↩︎
A programmable, energy-minimal dataflow compiler and architecture ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号