从 GPU 到 SambaNova,spatial computing 的数据流解决方案
很早前看到知乎的这篇回答[1],技术栈太浅薄不能理解 spatial computing 的核心问题,而今年 groq、tensotorrent、SambaNova 各种新鲜技术范式出现层出不穷,把我的胃口吊得高高的,遂调研 spatial computing。
Dataflow Accelerator
Spatial computing 对应的概念是 sequential computing [2],而 dataflow 对应的概念是 control flow。
- dataflow <-> control flow
- spatial computing <-> squential computing
程序展开可表达为数据依赖图(DFG),DFG 的基础单元是算子,将算子在时间和空间上分配给硬件的过程就是某种执行。什么 computing 决定了硬件性质,什么 flow 决定了算子到硬件的执行顺序依据。data flow 依据数据的依赖关系,而 control flow 依赖程序给定的序列性的计算顺序。
就和时空域[3]一样,dataflow 和 control flow这俩者没有一个明确的边界线,或者说,现有硬件的“幸存者”很难在体系架构理论体系内找到对应的分界概念,都是混杂了各种血统的混血儿。比如冯诺伊曼架构中底层分为 I-Cache 和 D-Cache 属于哈佛架构[4]。整个架构是在求解一个非常复杂的优化问题,根据不同的边界条件(i.e. 应用场景)求解参数和方法之间的 trade-off,最后优化的结果就是什么概念都带一点。
control flow 有一个同步的逻辑监管记录各个功能执行的次序和时间(e.g. 顺序指令),而 dataflow 更关注数据的依赖关系,检测状态是否 ready 而执行,具体执行顺序和执行时间不能确定。更细致地分析,这是由于往往将系统建模成 un-deterministic system,系统中存在大量的随机因素,比如 cache 的 prediction、DRAM refresh 通信等等,这些数据传输的开销都是不可预测的[^determinstic]。
就如前文所述,为了执行高效,现有传统处理器是在 control flow 的底子上不断加 dataflow 的异步处理机制,宏观上都是以顺序指令的形式编程,在局部微观上又会以乱序执行,比如 CPU 中的 reservation station 、GPU 中的 giga thread wrapper scheduler [5] 以及 Hopper 中的 TMA 机制。
传统 CPU/GPU 处理器是 control flow 高于 dataflow,在宏观层次上先后是固定的,微观局部乱序数据流,不同的乱序。具体说,宏观上通过在异步的块之间插入同步点,消除随机因素的影响同时确定执行顺序,同步点序列反映了宏观的 control flow,而局部的乱序处理交给运行时的 wrap scheduler 动态处理,而新型的 spatial computing 计算方法则是进一步提高了 dataflow 的比重,将一部分运行时的问题交给运行前的编译器处理。因为依赖关系可以表示为图结构,所以也被称为 spatial graph-based acclerator。就如知乎回答所说,传统的 CPU/GPU 处理器是将计算的执行建模成 sequential convex problem,而新型则是从 global convex optimization 出发。
虽然 CPU/GPU 都是 control flow 优先的硬件,但处理的问题不一样。 CPU 处理的是串行能力,针对的更多是时间上的不确定性,代表是 branch prediction,而 GPU 处理的并行问题这种时序执行上的分支更少,传统 DNN 都没有任何的条件结构,当然最近 DNN 也越来越多引入这种问题,比如结构上广度上的 MoE 和深度上的 skip layer, phase 上的 speculative decoding。
Sptial Graph Machine
"If you want to solve a vector problem, then build a vector machine." —— 某次听讲座不记得谁说的
不同的问题在硬件上的开销是什么呢?
上面提到,SCP 会在计算中加入同步点,而这是以保存上下文的形式实现的,即在 kernel function 中间插入对 DRAM 的访问。
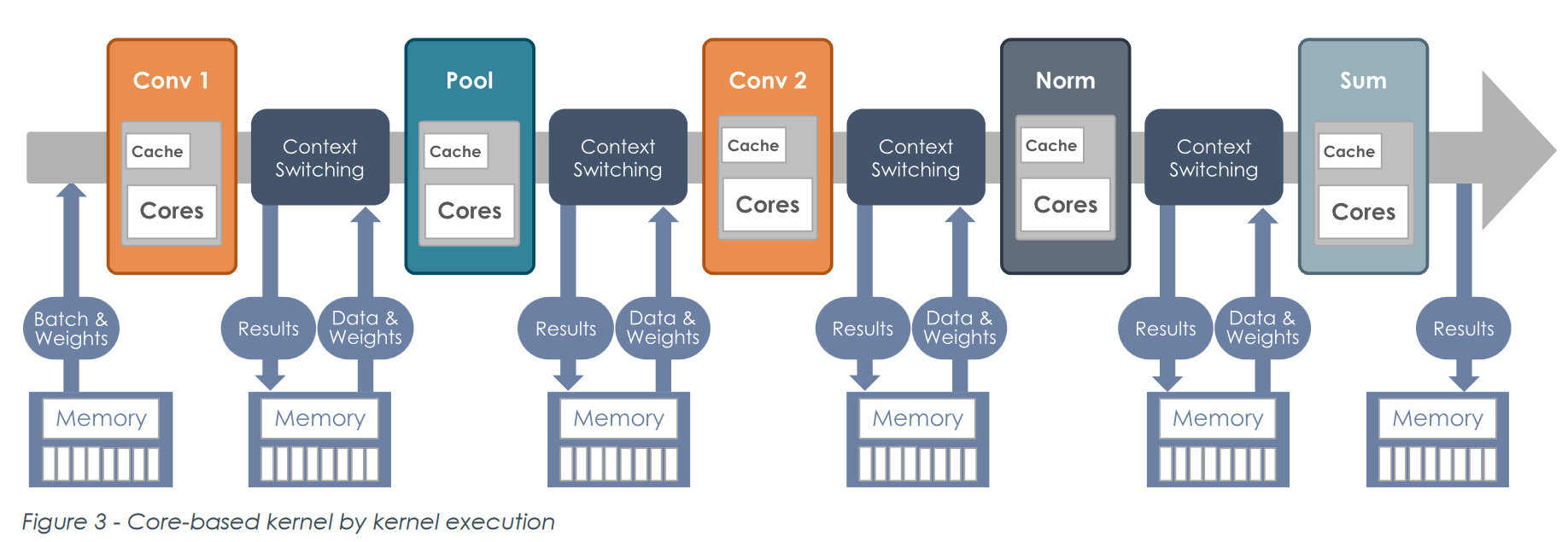
现有的 memory hierarchy 体系分为多层,NVM —— Memory —— L2 Cache —— L1 Cache —— Register File, 层级越高,访问的开销越大。访问 DRAM 的能耗和延时非常高昂,而有很多操作实际上并没有必要写回 DRAM,可以直接通过更底层的访问回避开销,比如 SM 内的 shared memory。这所方法称作 fused operation,将算子融合,fused operation 在 DSA 中有的直接通过特定架构不与 SRAM 交互,而在通用 GPU 中则是只有底层的 SRAM 交互上下文而避开了高层 DRAM 的访问。
但现有 GPU 架构上的 fused operation 粒度实际还是很大,这是由于数据复用关系,fused operation 实际上是把时域上的复用转移到了空域上,如果一个数据没有复用关系,比如 element-wise,就很容易做成 fused-operation,甚至很多工具可以自动化生成 [6];而若一个数据结构复用关系非常复杂,难度大大增加,这也是有人说 GPU 的核心问题是 tilling。比如涂老师的 TranCIM[7],能使用 reconfig streaming network 将 CIM 配置成 pipeline 形式的前提是使用了 sparse attention 稀疏化矩阵从而减少了复用关系。如果是原版的 attention 机制,纯使用通路避开 memory access 是不可能的,毕竟一般数据量大小远远大于硬件规格。
所以如果要最大化数据流的能力,一是提供底层之间的数据通路,具体来说是扁平化网络层次,将硬件体系树结构的深度减少,增加 peer-peer 之间的通路,另一个则是用底层存储的访问避开高层的访问,这通过增加底层 SRAM 的容量实现。 对比 GPU 的 Memory-L2 Cache-L1 Cache-RF 层次,tensotorrent、SambaNova 都是俩层扁平化结构 DRAM-SRAM;比较存储容量,SRAM 的比重也是大大提高,对比 H100 NVL、wormhole n300s、groq 的 SRAM 缓存分别是 71 MB、192 MB 和 230 MB!
| H 100 NVL [8] | n 300 s | |
|---|---|---|
| SM / Tensix Core | 114 | 128 |
| Freq | 1,080 MHz - 1755 MHz | 1 GHz |
| SRAM | 50 MB (L 2), 21 MB (L 1) | 192 MB |
| TFLOPs (FP 16) | 1671 (with sparisty, boost freqency) | 131 |
| Power | 350-400 W | 300 W |
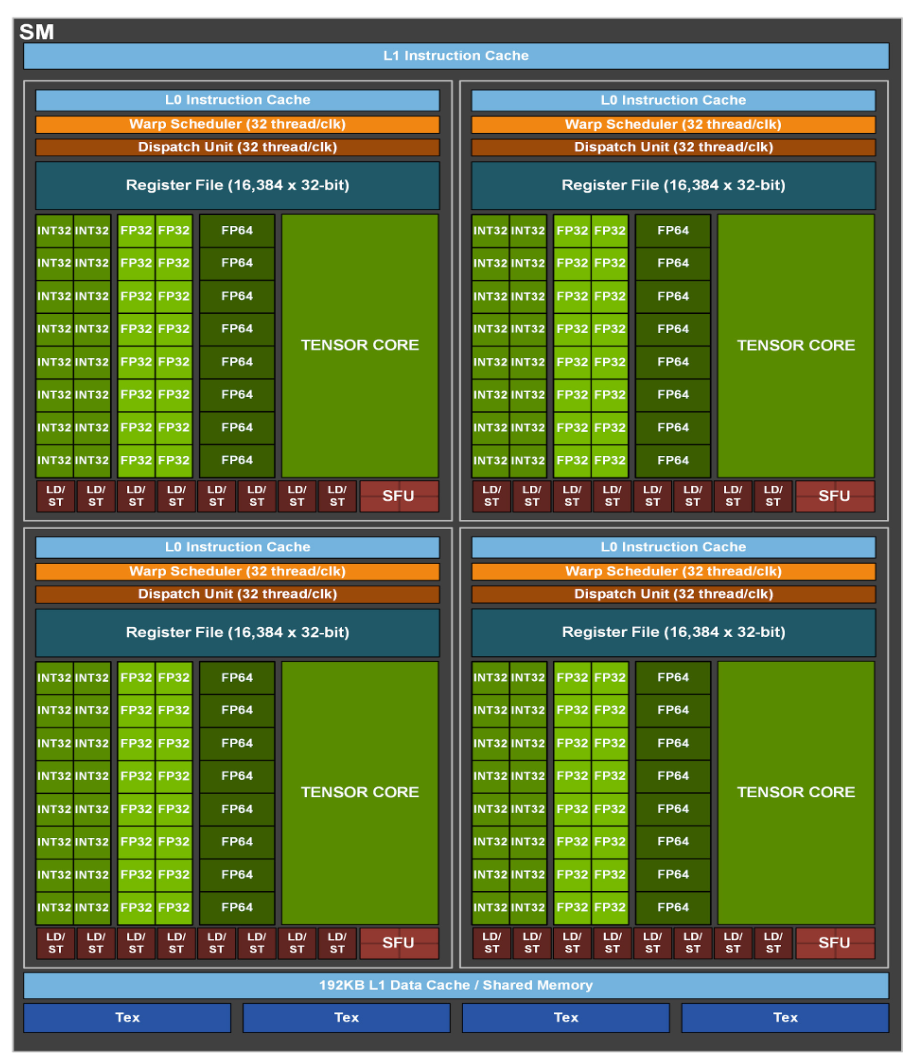
存储计算:根据 H100 white paper[9],H 100 NVL 拥有 50MB L2 缓存以及 114 个 SM,每个 SM 有 192 KB L1 缓存,一共是 21 MB。register file 有多少就不清楚了。
但是,代价是什么呢?Memory hierarchy 是多年迭代优化的结果,抛弃的代价是什么?
SRAM 面积开销相当大,放眼最近 ISSCC DSA ,die 的面积主要都在缓存上,增大存储面积势必要挤兑其余功能的分配。芯片面积四个部分,控制、计算、存储、IO,spatial computing 会增大存储和 IO 的面积(无论 multi-chip 还是 chiplet),而计算单元保持算力相对固定,最后挤兑的就是控制的面积,这通过把控制任务转移到编译器实现。
扩展 SRAM 有俩个方向,一是做大每个 SRAM 容量,二是增加数量做多。前者根据上网对 Tran CIM 的分析,可以减少对高层次缓存的访问,而后者则可以提供自由配置的带宽,也能进一步增加底层的数据通路。自由配置指的是地址信号的选址上,因为我们处理计算的粒度是操作数,每个操作数有不同的数据流特性,映射到硬件上控制流也不一样,像前文中提到的 I-Cache、D-Cache 以及现在广泛应用在 DSA 中由 DIANNAO 首次提出的 split buffer 都是根据数据特征划分存储的例子。又比如 DRAM 或者 SRAM 的多 bank 功能,虽然能够提高带宽,但地址接口数量还是不变,并非是我提到的“自由配置”的带宽。而增多 memory 不仅意味着存储开销,也有额外的控制逻辑的开销比例增加。先前 groq 团队的文章中 [10] 也有提到增大存储控制逻辑在系统中的比例。
所以总结最后反映到硬件上的结果便是,数据流架构处理器扩充了 SRAM 的深度和数量。那么这种“分布式”架构则特别适用于复杂的数据流,即计算图依赖越乱越好。放小了说本身神经网络结构中引入的 skip 连接能增加计算图复杂度,放大了也可以把不同的 stage 加进来增加系统复杂度。

图为 SambaNova 的重构模式。左图引入了多个 stage 增加计算图复杂度从而发挥 graph-based accelerator 的潜力。但数据维度往往是大于硬件维度的,也许这是一个更大多 chip level 的示意图,又或者增加了 SRAM 的深度就能够进一步发挥 fused operation 的潜力,使得这成为现实。
SambaNova / Tenstorrent 架构分析
扯完了 high-level 的改进,来看看更具体的架构设计。
SambaNova 有多个 PCU 的 tile mesh 构成,主要包括数据流路由结构 Switch、每个 memory 的控制结构 PMU 以及执行单元 PCU。
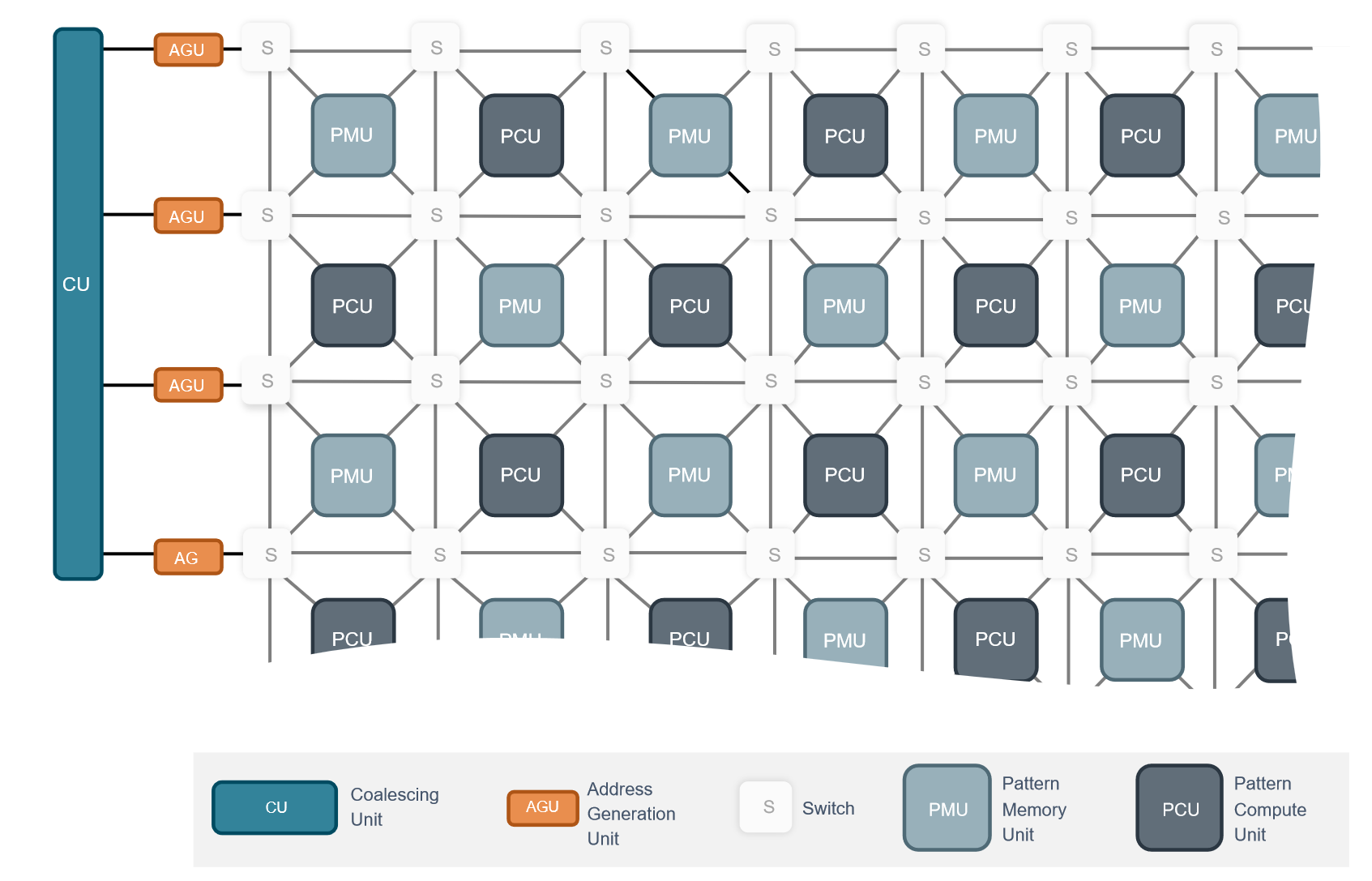
在执行时,通过 fused operation 重构数据流和执行功能。
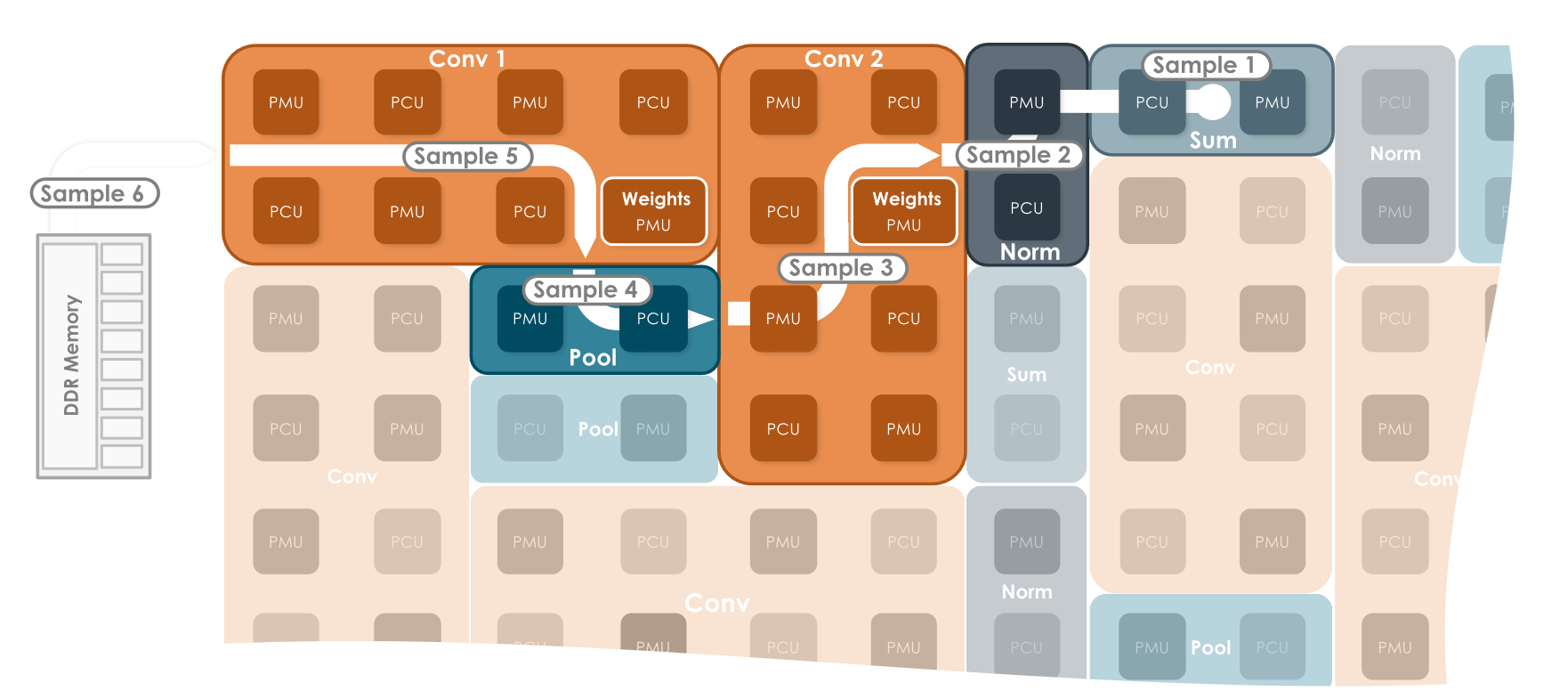
既有分散的存储单元,又有可重构的计算逻辑和数据通路,模式非常像 FPGA 啊,毕竟都是可重构计算。不过 FPGA 更加通用,所以 SambaNova 说自己重构成本更低,能做到 run-time 重构。
SambaNova 的软件栈编译 flow 也非常值得一看[11],不过多展开了。值得一提的是编译器提供了 o0、o1、o3 三种优化等级,增加 dataflow 的比例会提高异步性,给 debug 带来困难,o0 模式每个 kernel 还是依次顺序执行,适合用来 debug,o1 模式则是在宏观上保证一定的顺序,将整个图划分成多个 section,每个 section 内部优化,而 o3 则是彻彻底底将整个计算图放在一起优化了。这三种选项反映了不断向 dataflow accelerator 靠近的过程。
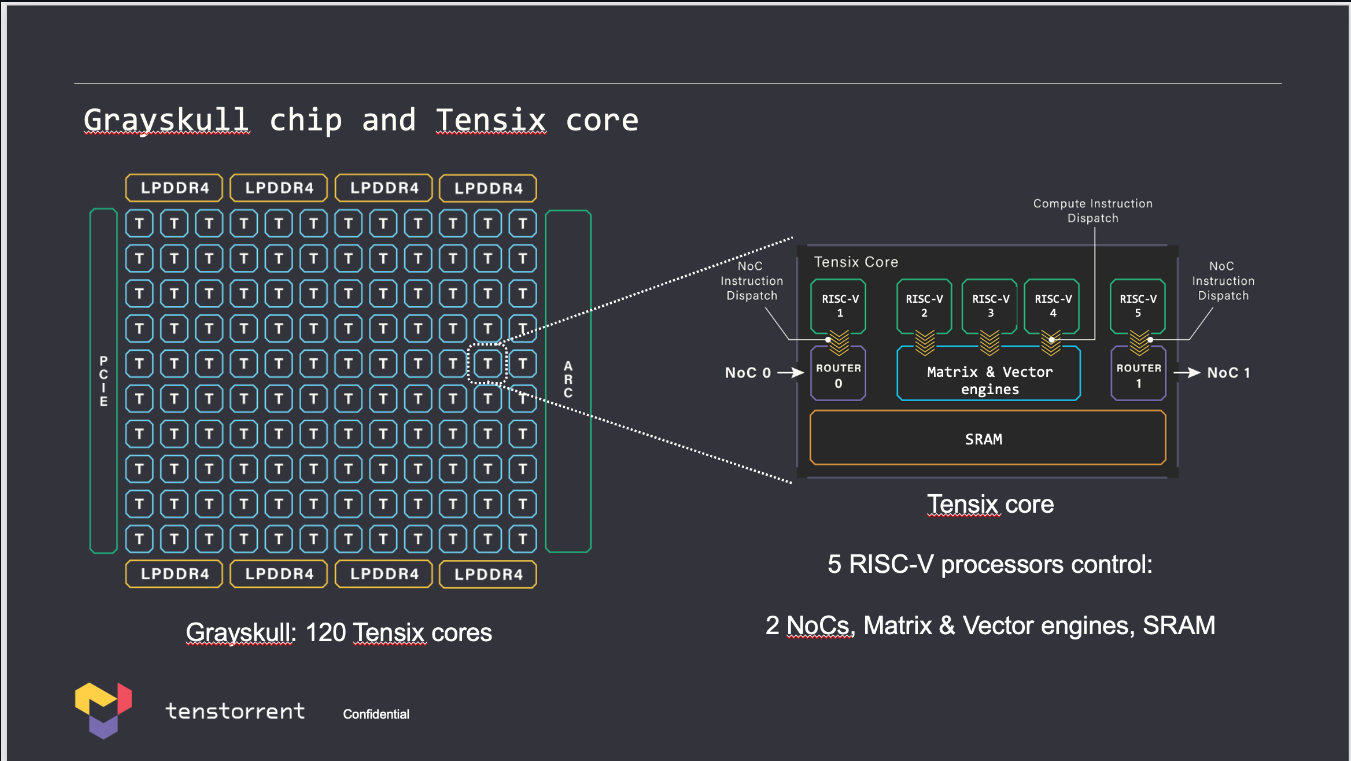
tenstorrent 的基础单元是 tensix core,包含 5 个 “baby" RISCV 核、一个 matrix & vector 执行单元、片上 SRAM 以及输入输出的 Router。结构上和 GPU 的 SM 非常相似,用 CPU 核处理调度对应 SM 中的 wrap scheduler,只不过专门将路由和计算的逻辑分开,根据先前 groq 的文章猜测 GPU 路由的逻辑也是在 SP 的 CPU 中处理,不过 Hopper 添加了 TMA 处理数据搬运俩者就更像了。Tensix Core 中矩阵执行单元可以处理 32x32 大小的 tile 计算,这里应该不是指 Tensor Core 中一周期处理 32x32 矩阵计算结果,那样的复杂度是 32x32x32,而是应该类似 Systolic Array 的 32x32 个 FMA,如果矩阵计算需要多个周期完成,不然和 SPEC 中的 FLOPS 对应不上。32x32 的 FMA,正好和一个 SM 中 4 个 8x4x8 的 Tensor Core 规格相对应。
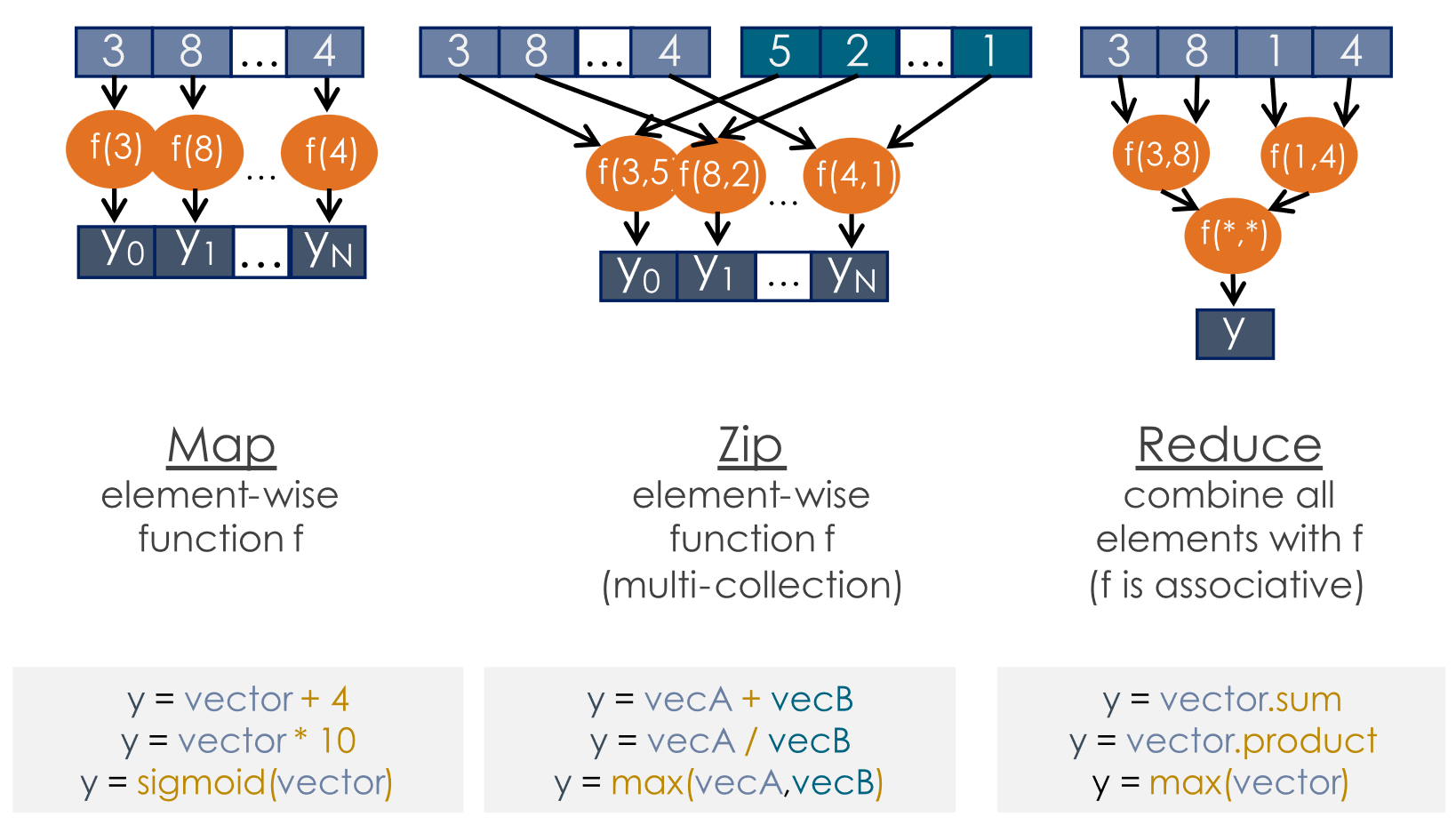
SambaNova 和 Tenstorrent 文档中都对不同操作的数据流类型进行了分类,大体分类思路是类似的,SambaNova 概括分类更加准确。
Tenstorrent 也有称自己是近存计算,因为存算范式实在太多,这个名词太广,就连 SRAM 存算都有很多种类,这里稍微区分一下。狭义 SRAM 存算不仅要节省计算单元到存储单元的读取开销,将二者尽可能放得近,还要求利用存储 cross-bar 结构内部带宽高,外部带宽低的特点,操作得是 reduce 类型的数据操作。而广义 SRAM 存算就没有太多繁文缛节,只是要求计算单元和存储相邻安放。
进一步分析,将计算单元和存储放置较近提升的原因在于将数据写入 cell 的时候同时已经更新计算单元书输入的电平,从而节约了读取出来时 pre-charge + sense amplifier 的能耗,这通过固定存储和计算的连线,每个 cell 都配置一个计算逻辑,这样写入时一定可以充上电,但种架构实际上和 SRAM 关系并不是很大,相当于存储作为 latch 的固定数据流架构处理器,而且由于固定数据流,数据流类型适用范围很窄,像 transpose 操作、DRAM PIM 的 memory interleaved 都不好解决;若要考虑 SRAM 的深度,可能还是需要一个 SRAM 的 pre-charge + SA 结构,这样仅仅是走线更短节省些导线上的能耗了,具体不同的方法能节省多少还要理论分析做个 breakdown。个人感觉 tenstorrent 应该是属于这种情况。
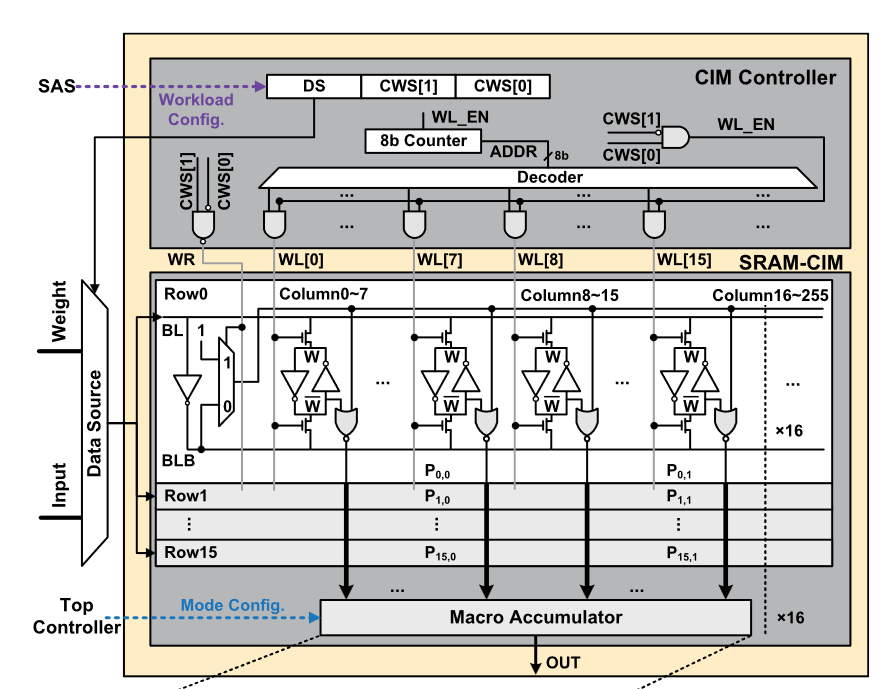
tranCIM 的 CIM Macro,已经看不到 SA 结构了
架构固定数据流的 DSA dataflow acclerator 相当于编译的过程交给架构师了,应用范围窄,而本文提到的几种 spatial computing 则是将优化工作交给了编译器(和开发编译器的算法工程师)。对于这部分的探索前人 TRIPS 有一部分工作,留个坑日后再看[12]。
总结
为了避开多层次额外读写的能耗,需要将系统扁平化增加 peer-peer 的通路,以及增加底层存储的容量,虽然总体层次减少了,但总存储开销更大了。
增加总存储,挤占了控制逻辑的面积。减少控制逻辑需要相应减少控制任务,否则控制逻辑的 pending 会影响总体性能。
以往从 CPU 到 GPU 控制逻辑让位给计算逻辑,是通过减少应用场景成立的,GPU 到 NPU 同样可以通过砍掉图形渲染/科学计算的应用进一步延续这个思路。而从专注 DNN 的 NPU 到 graph-based ,减少了 hierarhcy 反而会增加控制的复杂度,此时有俩种思路,进一步减少应用场景,从 DNN 到只关注几个模型(比如 transformer),或者更为激进,将控制任务交给编译器预先处理,类似 VLIW 的巨大生态变革。
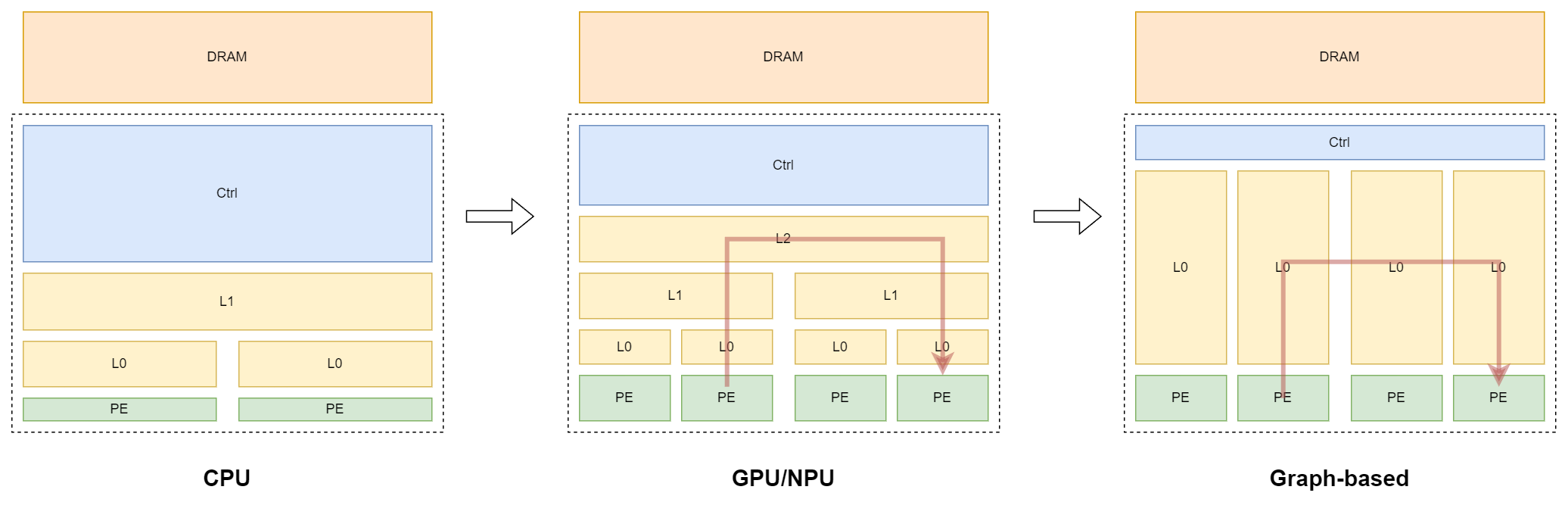
上图是对全文的总结,绿色仅表示执行单元不包括控制逻辑,而蓝色的控制逻辑是 hierarchy 各层的控制逻辑集中在一起。
https://www.zhihu.com/question/664743230/answer/3610329487 ↩︎
squential 和 spatial 没有专门术语,习惯叫法。如果知道严谨定义欢迎指正。 ↩︎
时空域划分的讨论见以前 blog https://www.cnblogs.com/devil-sx/p/18411963 ↩︎
哈佛和冯诺依曼架构并非是对立的概念,因为冯诺依曼架构概念针对的是“固定程序架构”,即固定架构只需要存储数据,程序不可修改,而冯诺依曼架构既存数据也存程序,因此可编程。哈佛架构只是将数据和程序分开存储,但仍满足“程序和数据皆可存储”的定义。这里意会就好。 ↩︎
由于 NVIDIA 闭源,GPU 具体怎么调度 SM-SM、SP 内部的实现不是很清晰,只见到 http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf ↩︎
https://www.zhihu.com/question/666742071/answer/3621306102 ↩︎
TranCIM: Full-Digital Bitline-Transpose CIM-based Sparse Transformer Accelerator With Pipeline/Parallel Reconfigurable Modes ↩︎
https://www.techpowerup.com/gpu-specs/h100-pcie-80-gb.c3899 ↩︎
Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads ↩︎
https://docs.sambanova.ai/developer/latest/compiler-overview.html ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号