ZigZag :nested loop 的教科书
ZigZag 在 PE array-memory hierarchy level 上对 nested-loop based 算子数据部署设计策略进行详细分析。文章作者来自鲁汶 MICAS [1]实验室。
软硬件建模
软件上只涉及 MAC-based 的网络算子(Linear、Convolutional),沿用 time-loop [2] 方法使用 nested-loop 建模,从 operand(Input、weight、output)以及不同维度(kernel size、channel size……)俩个角度囊括高维 tensor 算子。
架构上包括计算部分 2D PE array 和存储部分 unbalanced uneven memory hierarchy。Unbalanced-uneven 分别是从硬件架构-映射两个角度对不同 operator 定制化数据流,unbalanced 思想可追溯 14 年 DIANNAO, activation 和 weight buffer 物理上分离以便针对性发挥更自由的控制流,uneven 则是物理架构确定后,就算物理存储架构相同也可以根据 operator 制定不同映射策略。
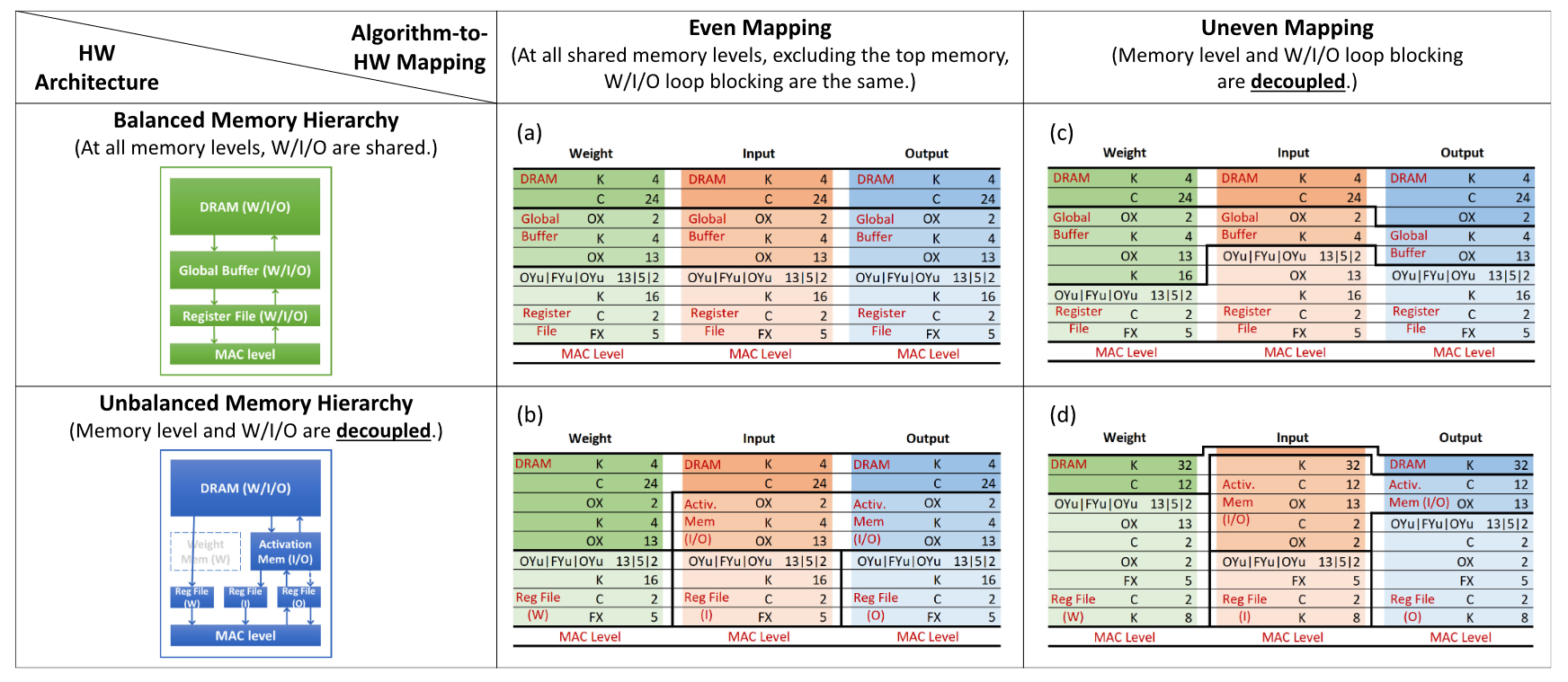
通过 nested loop 数据被抽象成一组维度的组合,将该数据的不同维度分配到不同的 memory level 的过程称之为部署。算法部署过程要满足计算正确的约束,即维度的循环顺序应当是一直的。通过 nested loop 模型可以导出 memory access 次数以及不同 hierarchy 之间的 datawidth,这之中的设计空间在于 trade-off 不同 operator、不同 hierarchy 之间的 data reuse。具体分析见原文或以前博文[3]不予展开。
搜索空间组成
搜索空间包括硬件参数以及映射策略俩层搜索。二者分层搜索,外层硬件内层软件映射,因此硬件搜索时不会以映射的性能作为 feedback(待考证)。硬件搜索根据 area-constraint 和用户定义的一系列 constraint 搜索出一系列符合要求的硬件参数组合(memory size、 data width ...),接着每个独立进行软件映射搜索。
映射搜索又分作两部分:计算阵列数据流的 Spatial Mapping 以及存储控制流 Temporal Mapping。Temporal Mapping 又分为 loop blocking 以及 loop ordering——先从篮子里挑出要排序的鸡蛋(分配调度维度大小),然后再给鸡蛋排序。
搜索空间剪枝
搜索空间剪枝分为俩种类型:(1)搜索空间中有许多点天然是完全等价的,因此可以无损剪枝减少搜索空间,理论上不会影响搜索结果;(2)另外基于一些先验进行剪枝,需要实验结果验证不影响搜索结果。
文中提及多个搜索策略,实际上他们之间有些并不是互斥而是兼容的(比如 heuristic search v2 就是对 v1 的全覆盖),将每个方法拎出来单独测试起到 sensitivity study 的作用。
- Spatial Mapping
- exhaustive search
- heuristic search v1
- heuristic search v2
- Temporal Mapping
- exhaustive search
- heuristic search v1
- heuristic search v2
- iterative search
Spatial Mapping 剪枝
heuristic v1 利用了 kernel 和 feature 中对于 x、y 方向维度的对称性,这些对称的点理论上性能表现是一样的;heurisitic v2 利用 operand 之间的依赖关系,通过加入 W/I/O 的 Pareto surface 函数关系减少搜索自由度(具体怎么得到 Pareto surface 有待考证)。
Temporal Mapping 剪枝
heuristic v1 则是固定数据(data stationary)提高数据复用度,无关维度应放在向下贴近 memory hierarchy 分界线的地方以扩大数据复用(如果从变量生存周期图上思考,将无关维度放循环最底层将变量调用的点连成了一条线,进而减少 memory access 的次数); heuristic v2 则是若某一个 level 的 memory 映射不存在无关维度,即不存在复用度,那么这个 level 之下的维度没有 ordering 的必要了(因为 DRAM 层包括所有维度一定包括无关维度对此层不成立)。
最后 iterative search 实际上是 rough/fine-grained search 策略,人为给 memory level 设置虚拟的 level 分界线,先搜索底层,得到结果后固定底层映射策略再囊括更高层。
总结
就目前阅读过的文章而言,这篇能够排在前三。本文非常适合 MAC 映射学习,从软件建模、硬件建模到部署策略的分析。当初也是通过阅读此文 get 到了 memory hierarchy 的含义。
此外文章主要是针对 1-layer 层面进行分析,全体网络结果只是简单相加实际,并且只涉及 MAC-based 的数据优化。Application domain 在链图(Path Graph)并且核心计算量在于 MAC 的网络(比如传统卷积 VGG、ResNet、MobileNet),对于图拓扑更加自由以及非线性算子也有相等比重的网络应当再弥补编译器方面的 scheduler problem 讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号