互联架构的图建模分析
互联网络泛泛谈
互联网络是一种图结构,节点之间通过边连接。比如一般总线计算机架构中 CPU、Memory、Timer 等模块看作节点, 通过总线相连。
每个节点在网络中的身份是不对等的,有 master 和 slave 之分,或者按 TLM 中的模型 initiator 和 target。Initiator 有权申请发起传输事务,而 target 只能被动响应事务。最简单的结构中心架构——拥有唯一 initiator 和数个 target,由于所有事务必须经过唯一的 initiator 发起,该 initiator 知道所有的传输事务,进而了解所有 target 的工作状态,比如简化 SoC 总线系统由 CPU 作为唯一的 initiator 调度其余模块。
当网络中存在多个 initiator 时网络情况将变得复杂。比如 CPU 去调用其余模块时是 initiator,而其余中断源向 CPU 传递中断信息时 CPU 则变为 target。这种情况还较为容易处理,因为 initiator 之间(CPU 和 中断源)的 target 并不重叠(CPU 的 target 是除 CPU 的模块,其余中断源的 target 是 CPU)。但当网络中多个 initiator 重叠 target 时,每个 initiator 不能完全控制它 target 的行为,因此也不能掌握 target 状态的全部信息,比如多核系统中的缓存一致性问题。这种情况则需要某种同步机制来更新状态。
综上从三个角度理解互联网络:互联拓扑、通信带宽以及主从架构。
图论建模
考虑互联拓扑和主从关系,互联网络是有向图结构,可用邻接矩阵表示。每个节点代表一个模块,比如模块 A、模块 B、模块 C……
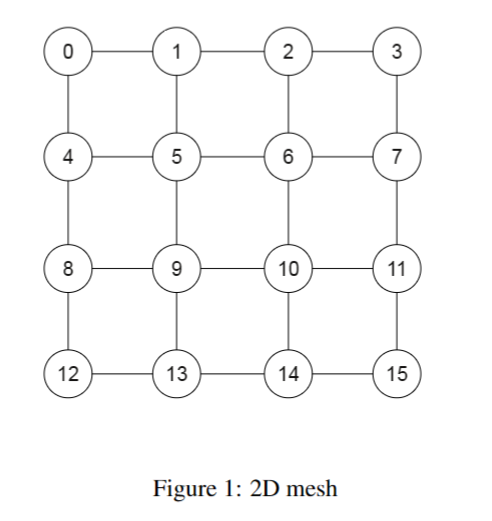
(initiator,target) 表示从 initiator 到 target 的有向边,红色/白色 表示俩模块之间 有互联/无互联。图(a)中 A 是 CPU,BCDE 是其他模块,其中 BCD 是中断源。任意一列只有一个红色方格,因此 initiator 的 target 之间互相不重叠;而图 (b)中 A、B 节点作为 initiator 时 C、D、E 的 target 重叠,对于 A、B 不能完全知道 C、D、E 的状态。图(c)则是表示任意节点之间都可以构成双向互联(不考虑对自己通信的情况)。
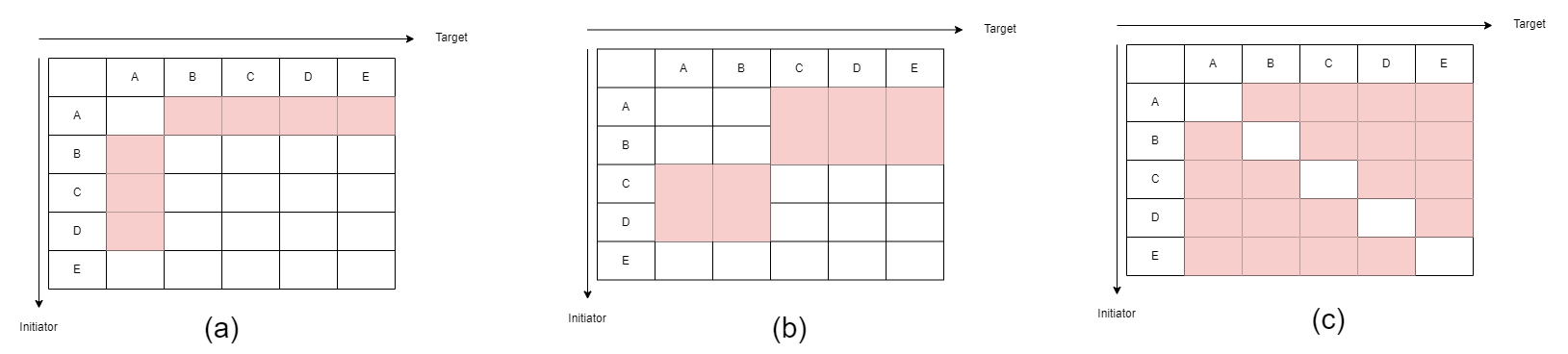
理想总线架构中挂载在总线的任意 initiator 都能对(除自身外的)任意 target 发起通信事务,假设某架构 A 作为 initiator 身份,B、C、D 作为 target 身份,E 既是 initiator 又是 target。邻接表示中纯 target 身份一行全为白色,是 initiator 的那一行则是标红所有 target。而考虑 2D Mesh 降维的 1D sequence,即 A-B-C-D-E 只能和相邻节点之间双向通信,则是图中俩条带状。
硬件模块的划分并不是唯一的,比如将 A、B、C 合成为一个节点,对外统一接口,这样在外面的网络看来 A、B、C 是一个节点,而 ABC 系统内部又有个小网络规划通信,很多加速器便是这种架构,将加速器挂在 SoC 总线上,而加速器内部又有矩阵单元、非线性单元、buffer 的互联网络。容易推导合并操作如何从原来一个邻接矩阵变化到表示大网络和小网络的俩个邻接矩阵。
网络的调度:软硬件同一图表示
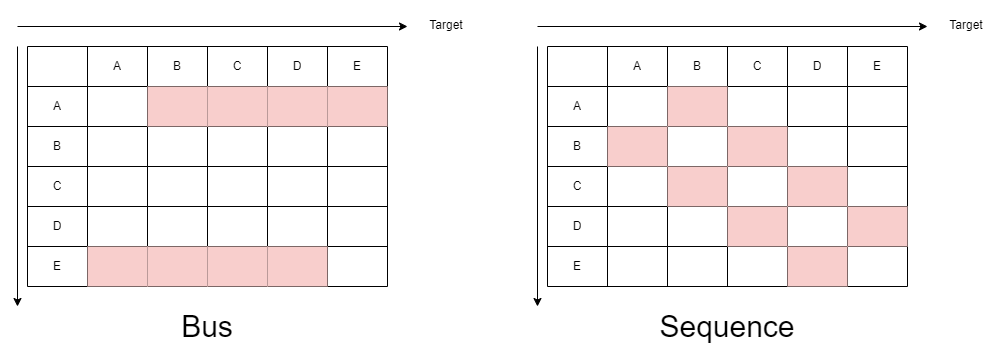
程序可以用算法表示,计算图也是有向图结构。算法在硬件上执行首先要经过 mapping 将计算图的节点(算子)映射到具体执行硬件上,同一套算法和硬件存在不同的映射方式(比如系统中有多个矩阵乘法核,矩阵乘法可以映射到其中任意之一)。Mapping 完成后用硬件模块替换算子,根据数据依赖关系则可以绘制出这种映射策略下的软件执行邻接矩阵。由于程序不唯一、mapping 策略不唯一,硬件执行互联图并不唯一。而硬件固定了互联拓扑就是唯一的。
若软件执行图是硬件互联图的子图,则硬件直接将对应模块通信即可,否则则需要通过中间者传递通信事务。比如 Figure 1 的 2D mesh,mapping 后的程序要求节点 1 和节点 3 通信,但二者并不直接相连接,需要通过中间节点规划传输路径。直观感受规划通信路径越长,则开销越大。
设计复杂度感性体会
以上图表只反映了硬件逻辑的互联拓扑,未考虑时间上的调度信息(比如总线架构同一时刻只能有一个传输事务,计算图中执行的先后顺序)。不同网络控制器设计难度区别极大,感性理解决策空间复杂度由同一时刻系统要规划的通信路径数量、initiator 和 target 分布以及 mapping 策略决定。比如每个节点都是同质的 2D mesh 结构,不像金字塔结构构建层层抽象,有个高级节点统领全局,本文所提及的俩个问题都存在,一致性问题和中间节点通信问题,且同质意味着 mapping 空间也极大。{硬件异步通信策略、软件 mapping 策略、路径规划策略}几个决策空间叠加使得软硬件设计极其复杂。
SRAM 存算最诟病一点便是没有解决数据搬运核心 DRAM 开销,一种技术路线是用 chiplet 拼凑晶圆级系统提升 SRAM 容量规避 DRAM,chiplet 天然2D mesh 互联结构将使得软件编译器设计极其困难为了cue 2D mesh 这个醋包了本文这个饺子。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号