Dark Silicon 暗硅,先进节点的运算极限
Introduction
ITRS [1]每次预测未来 15 年半导体的发展,2024 年恰好是 Dark Silicon 文章写作年份 ITRS 预测最后一年[2]。15 年回首,重温 《Dark silicon and the end of multicore scaling》[3] 这篇伟大文章。
提出背景
架构视角:多核处理器发展
Moore's Law 描述晶体管密度越来越高。然而产品的尺寸由人物理尺寸决定的,笔记本尺寸总不能随着晶体管尺寸缩小吧!有那么多面积可以放电路板子,自然都要利用上,对于一个固定的场景,设计往往不会变动面积,而 transistor count 越来越多。
按理说算力正比于 transistor count,核做得越大,性能自然越强。然而代码天然的顺序执行结构导致单核性能存在边际递减效应。Polloack's Rule 描述单核性能和面积成开方增长关系。
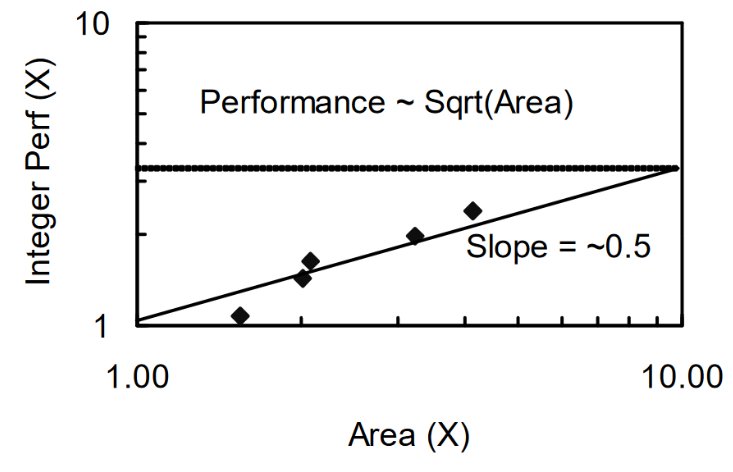
比如执行某数据格式 A + B 的指令,计算量就是固定的,并且由于顺序结构不能提前执行后面的指令。transistor count 增大计算能力上升了,但要处理的指令和数据就那么多,计算的容器没有那么多数据的水来装。这是单核处理器边际递减效应笼统的理解,实际情况单核也可以提前执行后面的指令(超标量,分支预测),也不一定按顺序执行(乱序),更确切地说,应该是数据依赖导致无法填满容器。
一看到非线性收益曲线,搞研究的特别高兴,非线性意味着存在优化问题,可以 trade-off 水文章呐!想要更大发挥每一个晶体管收益,便发掘程序中可以并行处理的部分,增大同时需要处理的数据量以匹配增长的计算能力,这就是多线程编程和多核处理器。
在相同面积下,多核处理器对比单个大核处理器,相当于降低单核性能,提高核的数量增大并行能力。其收益取决于代码中允许并行的部分,也就是以 Amdahl's Law 衡量多核收益,代码中允许并行的部分以并行系数 \(f\) 囊括。
工艺视角:Dennard Scaling 失灵
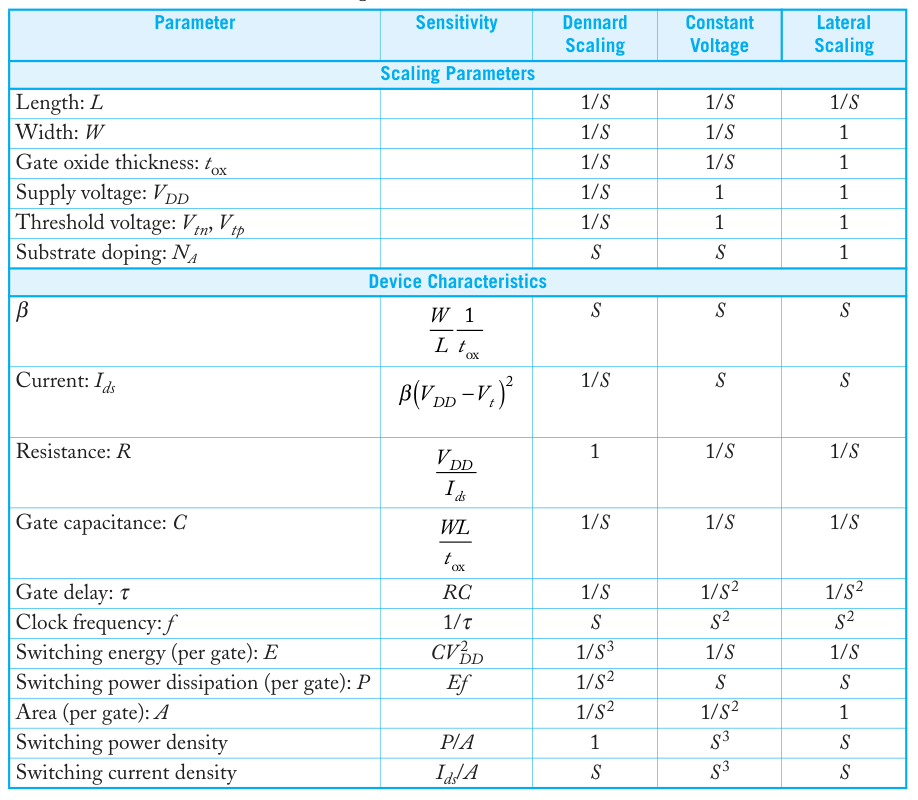
2011 年 Moore's law 还能依靠 FinEFT 续几年命,然而由于低节点下漏电流问题越来越显著 Dennard Scaling 已经快要失灵 [4]。Dennard Scaling 模型中 power density 不随工艺变化,失灵意味更先进节点下 TDP 更加重要。
十年的预言:Dark Silicon
文章站在这俩个大背景下,架构上接算法下接电路,工艺(器件)上接电路下接基础物理,文章视野不可谓之不广。结论很易懂,随着 Dennard Scaling 失灵电路热密度越来越高,而材料散热能力是固定的(半导体材料不变),所以如果继续按照原来的设计芯片就成大火炉了。对于固定的面积,芯片一部分 transistor activate 另一部分就必须强制休息了,这部分不工作的 transistor 就和宇宙中观测不到的暗物质一样,称作 dark silicon[5]。
结论并不复杂,当时有敏锐 sense 的设计师科研人员应该也能察觉到这个趋势,文章难得可贵的是量化分析给出可信数据结果。本文重点学习分析文章如何对如此复杂范围广阔的问题的建模。
建模思路
文章从三个层次建模硬件:
- Device Scaling 工艺缩放
- Core Scaling 单核性能
- Multicore Scaling 多核性能
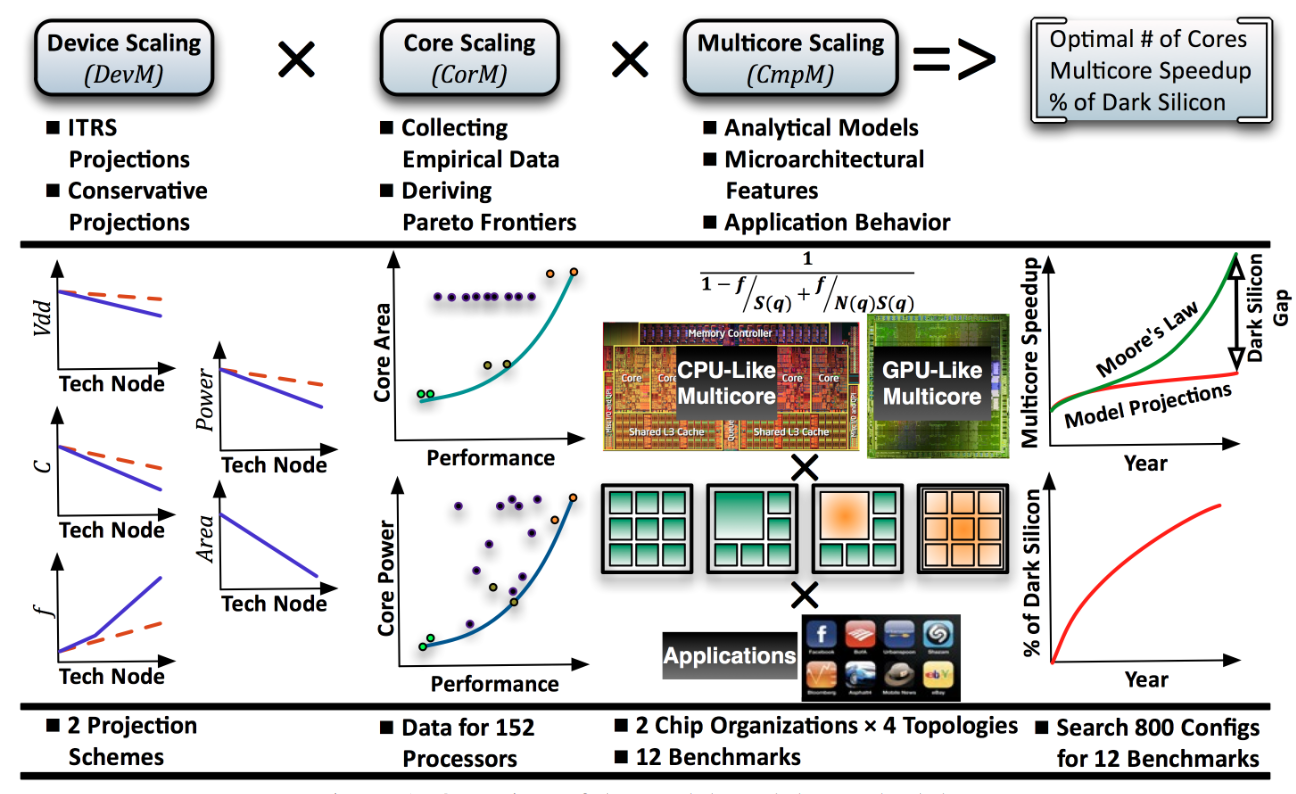
| Model Level | Device Scaling | Core Scaling | Multicore Scaling |
|---|---|---|---|
| Hardware Specification | 工艺放缩预测 | 处理器面积、能耗 | 缓存组织 + 多核组织 |
| Software Performance | SPEC | PARSEC benchmark + system level 表现建模 | |
| Verification | 经验预测,无验证 | 实测数据拟合 | GPGPU Sim 仿真验证 |
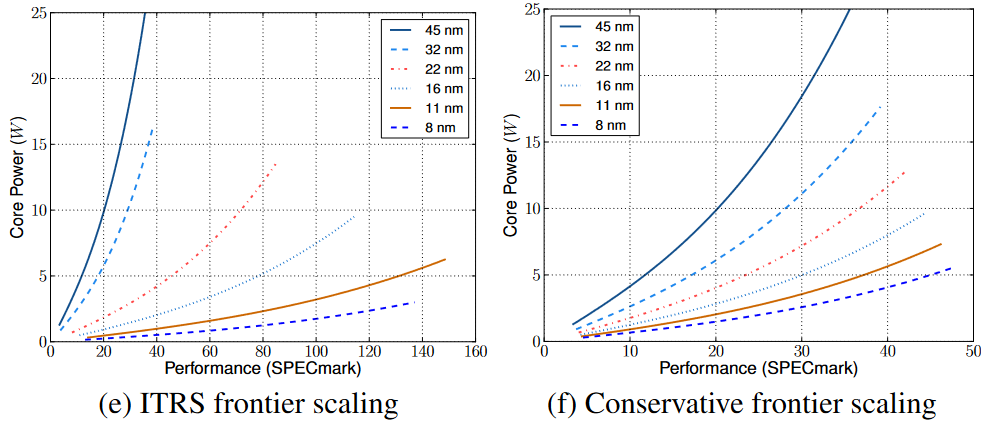
工艺方面直接使用了 ITRS Roadmap 和 Borkar 演讲中更保守的数据,对频率、电容、功耗、面积进行 scaling,能耗数据只有纯动态功耗中并不包括漏电流。现在看来 ITRS 当时的预测确实过于乐观。
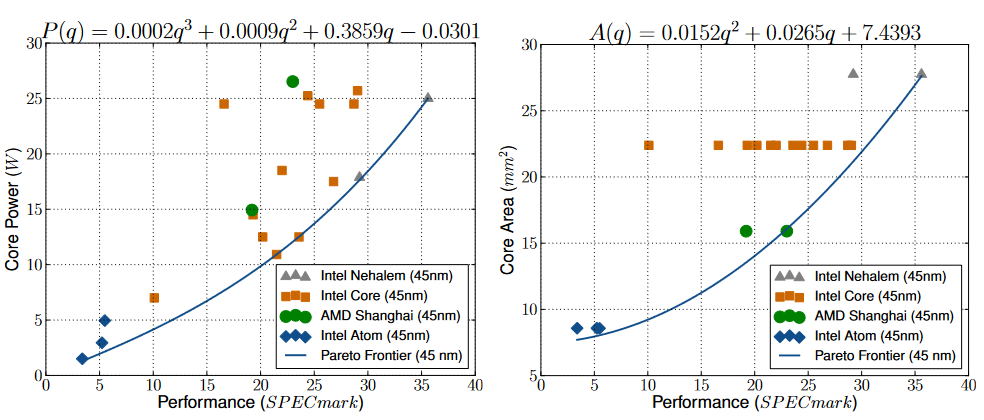
单核上关键要概括不同设计之间 trade-off 的搜索空间。设计因素那就多了去了,架构、电路、电压、频率、面积一堆因素相互制约,但不需要研究太细,只把结果简化为 PPA。Power使用了 TDP 数据,假设 20% 的功耗由漏电流贡献, performance 用 SPEC 数据代替,area 直接看的 die shot。并且功耗和面积都排除了 L2、L3 缓存。对主流工艺 45 nm 下实验数据分别拟合 “能耗-表现” 的三次、“面积-表现” 和二次 Pareto frontier 曲线[6],再结合之前的 Device Scaling 关系对 Pareto frontier 曲线放缩。
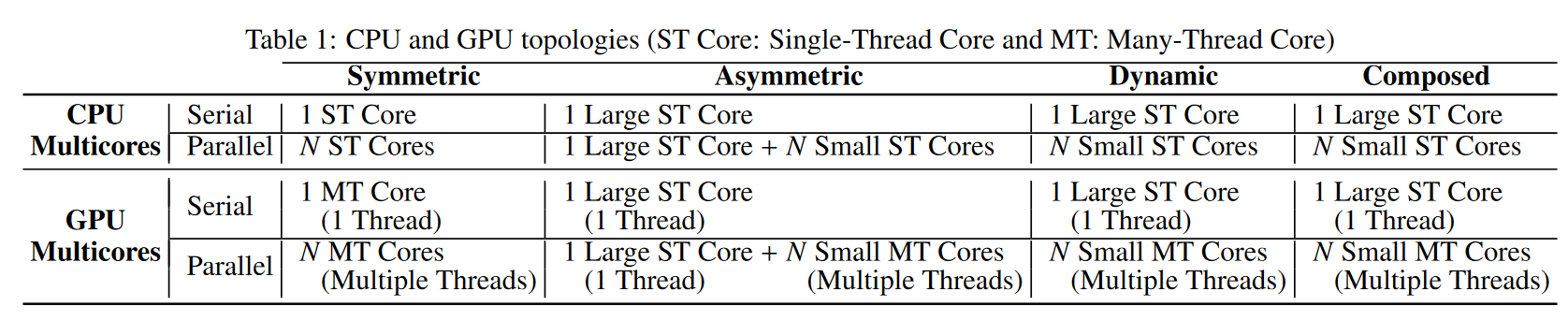
如果说单核性能是实测数据高屋建瓴地进行概括,多核建模恰恰相反,从底至顶完整设计了一套模型进行参数搜索。因为程序中不可能百分百都允许并行,架构往往是大小核配合,根据大小核组合的方式划分四种分类,又根据单核性能——缓存的组织方式划分了 CPU-like,GPU-like 俩种架构[7],总共是 8 个 setting。
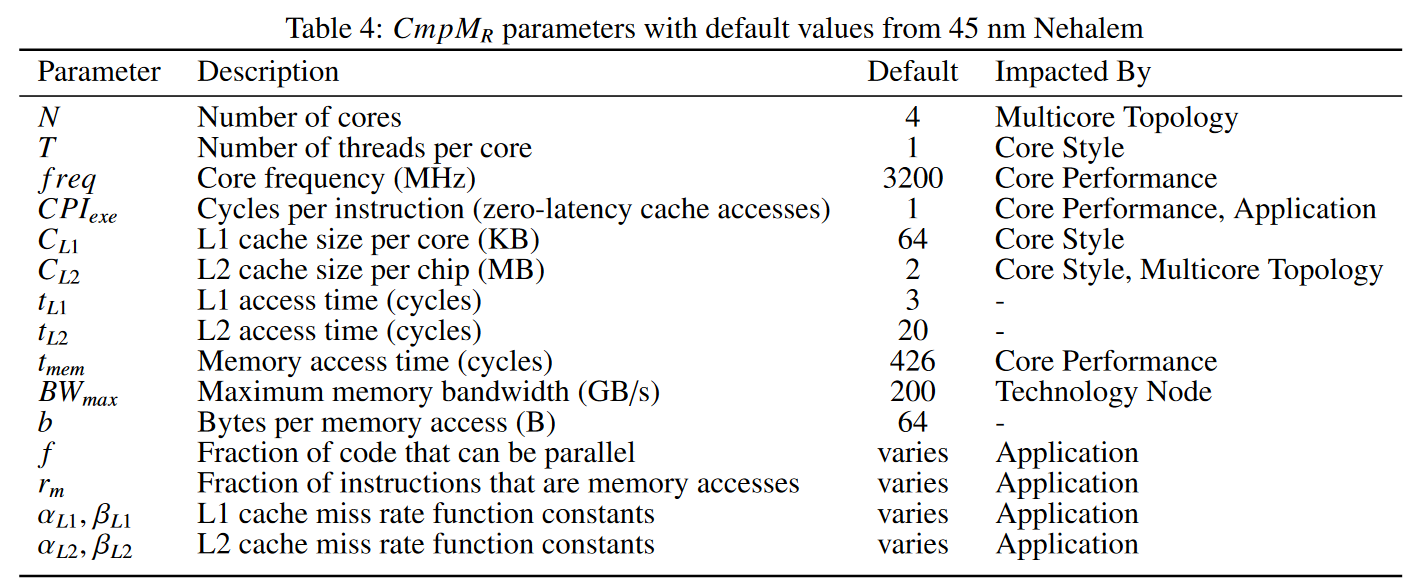
- 搜索空间:前级的工艺数据、单核架构 PPA(Pareto frontier),以及本级核的数量
- 搜索边界:能耗 TDP 和面积 Die Area
- 模型和结果:总体上使用 Amdahl's law 相比 45 nm 单核 Nehalem 衡量相对提升。硬件上除了考虑处理器外,还建模了完整的 Memory Hierarchy,考虑数据传输的影响。使用上一级 performance 建模 CPI 和 frequency, 假设 \(P = f\times CPI\) 这样结合 Pareto frontier,CPI 和 frequency 只有一个自由度。软件上使用了 PARSEC benchmark,根据前人的工作拟合了并行系数,并拟合了 cache 预测率函数。
结论分析
在不同节点下使用了相同的功耗面积约束以及相同 baseline,对不同的 setting 进行参数搜索,当搜索遇到边界或者开始下降时停止搜索。将 percent dark silicon 定义为
随着工艺进步,dark silicon [8]比例逐渐增高。
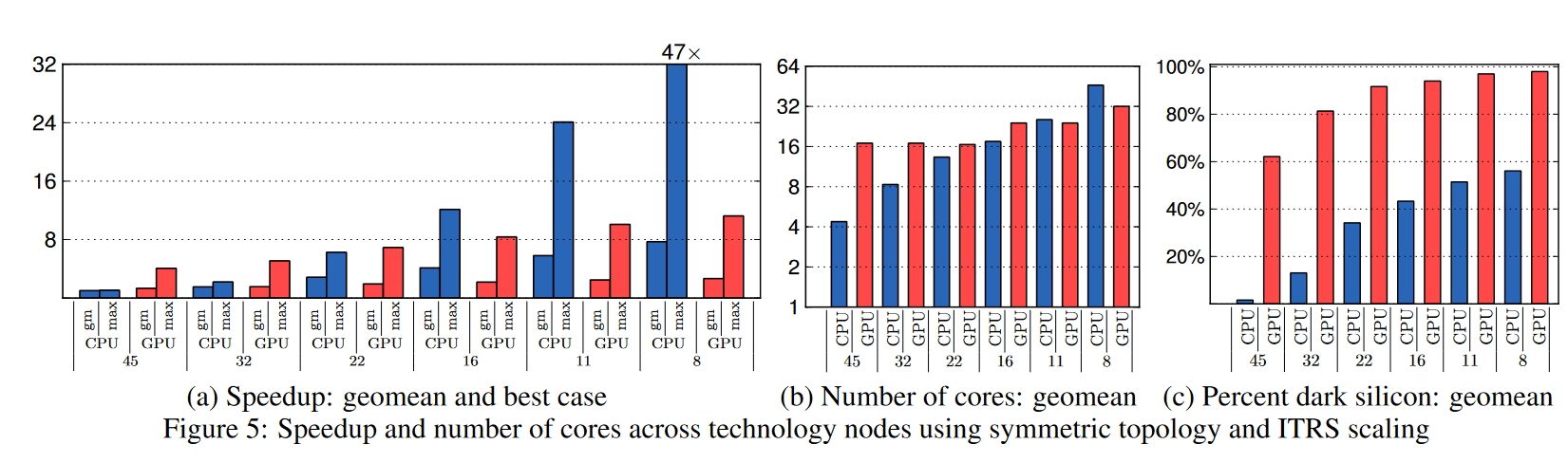
由于 TDP 限制芯片无法充分利用分配面积,从而限制 performance 的 scaling。
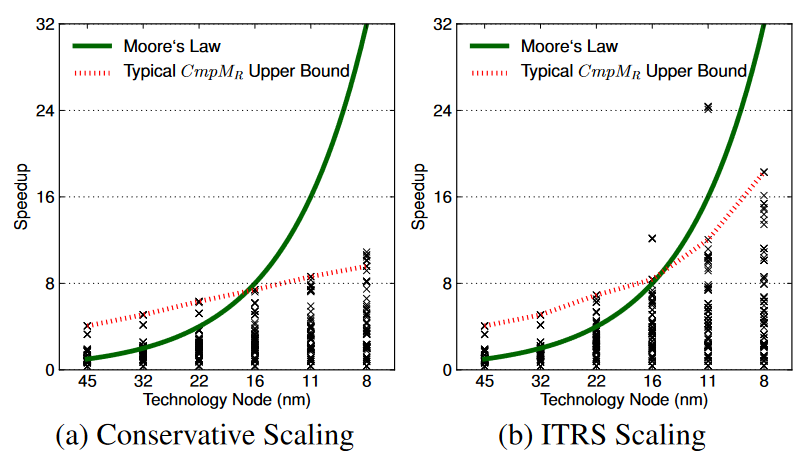
那么到底 dark silicon 的来源在哪?是本身 Dennard Scaling 失灵语境下工艺节点导致失灵?还是结果仅限于多核架构的语境之下?
从计算单元角度思考这个问题:
- 一个任务需要的时间为 performance
- 任务所需要的算力和具体执行算法有关
- 硬件提供的算力 \(\text{Ops} = \text{Transistor Count} \times \text{Utilization Rate} \times \text{Frequency}\) [9]
粗略理解,假设某个任务算法需要计算量相近且在相同 frequency 下,Polloack's Rule 单核性能的边缘递减效应来自随着 transistor count 增加, utilization rate 却下降了,于是使用多核架构发掘算法并行性提高 utilization rate。所以并行架构上 transistor-level utilization rate 相当高,进而导致相同的 constraint 下,GPU 发热现象会比 CPU 更加显著。
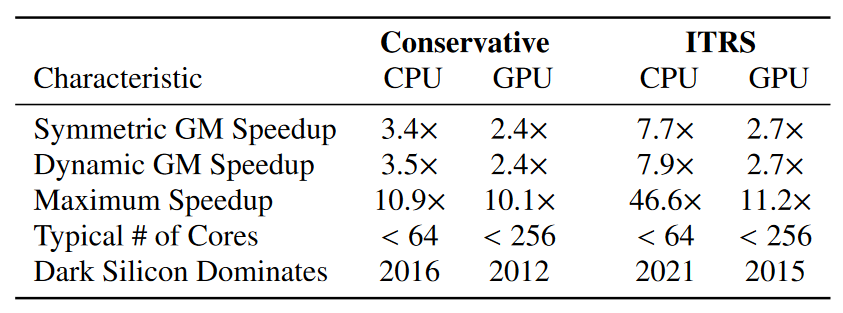
但这并不足以严谨论证 dark silicon 的来源来自多核架构,公式对存储组织并不能很好概括。深入分析我还没由太搞清楚,欢迎同好指点。
个人思考
这篇架构工作非常典型,涵盖层次上至算法下至电路/器件,建模分析方法也非常全面,十分适合学习。
硬件是一个非常复杂和封闭的系统,非常难对全局系统进行仿真分析,因此各种理论模型也层出不穷[10]架构就是数模大赛。建模本身就是一个 trade-off,节约研究时间/仿真时间,但降低了可信度准确度。模型可信需要大量的经验和扎实的验证工作,文中有诸多假设,比如假设 power-performance 呈现三次关系,这种拟合设置更多是一种经验定律。经验和汗水重要性再次凸显硬件行业吃工程的特点。
本文是在一篇又一篇的积累基础上诞生的。器件上,Moore's Law 和 Dennard's Scaling 作为背景,以 ITRS 和 S. Borkar 的演讲[11]作为节点预测;单核上,peformance-area 关系使用了 Polloack's Rule,软件 benchmark 用 SPEC;多核系统上,基础理论根据 Adaml's Law,Adaml's Law 在不同多核拓扑的扩展参考了 Hill and Marty 的方法[12],多核计算和带宽模型取自 Z. Guz 的工作,软件 benchmark 使用 PARSEC,用 GPGPUSim 作为 simulator 仿真验证。
这样一想架构和经济学非常相似?都是研究人造的复杂系统,都是需要提出许多假设进行建模,其方法论想必也有共通之处?
具体的方法来看,本文单核表现通过现实数据拟合建模,解释性差准确性高;而多核表现则是自己建模再用 simulator 验证,解释性好难建模非常困难。这俩种建模方式都相当于构建了一个解析模型,可以在仿真环境里快速计算迭代搜索。解析模型建模比较依靠经验,另一种范式是通过纯仿真模型,对算力开销非常之大。此外最近听说也有用机器学习方法,通过学习数据构建解析解,兼顾计算效率和设计难度。比如 CIM 领域有名的建模工具,NeuroCIM [13]便是走得仿真思路(对 Circuit level 的仿真),而最近的 CiMLoop [14]则使用统计值囊括,算是构建解析模型了(不过这里只有值而没有函数)。
行业 sense 上,文章一是提醒要有全局观念,研究就像优化,很容易在复杂系统里优化到一个局部值陷进去了,文章中也提及当初有人在研究数千核系统,然而本文直接说明纯在一个核数量的上限。BTW,这种存在一个 upper bound 的思想也非常符合我的科学观。架构是站在半导体和算法两处上工作,这都是环环相扣的,比如 Moore's Law 晶体管密度持续增加并不意味着性能持续增加,需要 Dennard's Scaling 或是多核处理;比如文章假设 Moore's Law 持续并在 PARSEC 上测试验证结果,倘若 Moore's Law 停止增长,算法更换,结论又该如何呢。这一切都是紧密耦合的,现在无论是上层还是下层都经历巨变,新时代架构又以什么为基础理论?
International Technology Roadmap for Semiconductors, 最后一次于 2013 年发布,其功能现已被 International Roadmap for Devices and Systems 取代 https://irds.ieee.org/ ↩︎
文章发布于 2011 年,写作时最新 ITRS 更新到 2009 年 https://www.itrs2.net/itrs-reports.html ↩︎
2011 年 TSMC 刚发布 28/22 nm 工艺, TSMC 在 16 nm 节点首次应用 FinEFT。文章写作时主流工艺是 45/40 nm,漏电流问题还不能算破坏了 Dennard Scaling,文章非常有前瞻性 https://www.tsmc.com/english/dedicatedFoundry/technology/logic ↩︎
说起 dark silicon 想起来今年 intel lunnar lake 里的空硅片 233 https://www.intel.com/content/www/us/en/newsroom/news/intels-lunar-lake-processors-arriving-q3-2024.html#gs.c23ywe ↩︎
无论二次还是三次,拟合都是一种经验定律。二次是 Polloack's Rule,三次的出处可参考 Deep submicron microprocessor design issues ↩︎
从指令流(Instruction)和数据流(Data)角度理解处理器,一个处理器看作有处理指令的(fetch,decode,brach prediction)和处理数据的 (execution unit, write back)。多核的 GPU 和 CPU 架构都是 MIMD,区别在每个核 I 和 D 的比例不同。从文章用缓存组织方式区分 CPU、GPU 可见 I 的部分核心反映在于缓存的预测性能。 ↩︎
为啥 GPU 架构比 CPU dark silicon rate 更高呀? ↩︎
这个公式非常粗糙:逻辑单元可以很好用上述公式概括,但存储单元表现不太一样,而大量的面积由存储单元贡献 ↩︎
人类自个儿造出来的复杂系统也无法用完善理论概括,不过社会也是人建造出来的,more is different 嘛 ↩︎
S. Borkar. The exascale challenge. Keynote at International Symposium on VLSI Design, Automation and Test (VLSIDAT), 2010 ↩︎
G. M. Amdahl. Validity of the single processor approach to achieving large-scale computing capabilities. In AFIPS ’67 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号