RRAM SRAM Fusion CIM 论文阅读
CIM 发展这么多年,RRAM CIM 和 SRAM CIM 各自精彩。前几天 TSMC+新竹清华的张孟凡老师团队在 Science 上发表 RRAM + SRAM CIM 的 Fusion CIM 工作[1]。
Review
Digital SRAM CIM 相较其他主流 AI 加速器范式区别不大,也是最 promising 接近商用的路线(今年 ISSCC 已有工业界 Axelera AI 和 MediaTek 的工作亮相)。
个人见解,SRAM CIM 是固定 weight 不断刷新输入 activation,计算策略上和 systolic array weight-stationary 策略异曲同工。而 SRAM CIM 准确来说都是 NMC(Near-Memory Computing) 而非像 RRAM 那样真正存储和计算在器件层面融合,计算单元和存储单元还是分离的,只是你中有我我中有你,计算架构上对比 GPU 同一个 SM(Streaming Multiprocessor)中的 share memory SRAM cache 也非常相似,只是 SRAM CIM 的容量往往比 GPU 的 shared memory 更大一些(SRAM Macro 的 size 一般 10 ~ 100 KB 量级不等,而 A100 的 shared memory 则是 5.125 KB[2])。
RRAM CIM 范式则更加特立独行。作为存储 RRAM 的好处是 non-volatile,即是 on-chip memory 也发挥 storge 的功能。然而即使 1T1R-RRAM 相比同为片上的 6T-SRAM 大概有 6x 的密度提升,相比 multi-layer 的 DRAM 或是 flash 单元还是远远不足。所以 RRAM CIM 的工作都会尽量避开和 DRAM 或是 SSD 的交互来突出应用价值,也因此所有在 RRAM 上跑的网络都是类似 ResNet-20 或是 MobileNet 这种轻量级卷积网络。
虽然说 RRAM+SRAM Fusion CIM,但 RRAM CIM 和 SRAM CIM 的地位并非对等,更贴切的是说,用 SRAM 辅助 RRAM CIM。
RRAM drawback
确定了 SRAM 辅助 RRAM 的立意,我们再来回顾 RRAM 的缺点:
- 写入问题。写入上 RRAM 有 endurance 和 reset-latency 俩个问题。所以一般 RRAM 在 inference 时避免频繁地擦写。
- 精度问题。模拟计算大大降低了系统鲁棒性,容易受到噪声影响计算精度。有三个主要噪声源:制造工艺噪声(Process Variation)、电源噪声(稳压器噪声、IR drop 等)、温度(热噪声等)。为了提高鲁棒性一般降低 RRAM 的阻态数量和提供更大的电压进而提供动态范围,然而这又会降低 RRAM 存储量和能耗表现。
为了减少由制造工艺的误差引起的器件特有的精度损失,除了在虚拟平台先完成模拟的训练,还会在芯片实体上 on-chip training 微调,这又不可避免地引入 RRAM 的写入。
Fusion CIM
围绕 RRAM 的缺点,Fusion CIM 这篇俩个核心创新改进
- precision-throughput 之间的 trade-off
- Adaptive Local Training,减少 on-chip training RRAM 的写入次数
Precision Design Space
Fusion CIM 的核心是 fusion UNIT,每个 fusion UNIT 通过 fusin bridge 将 RRAM CIM 和 SRAM CIM 相连接。
Fusion UNIT 从部署 weight 位置来看,有三种工作模式 memristor-CIM mode、mixed-device CIM mode、SRAM-CIM mode。其中 memristor 又可以进一步挑 MLC,SLC-MLC,SLC 模式,一共是 MM-M、MM-2、MM-1、MM-S、MDM、SM 五种模式,精度依次上升。
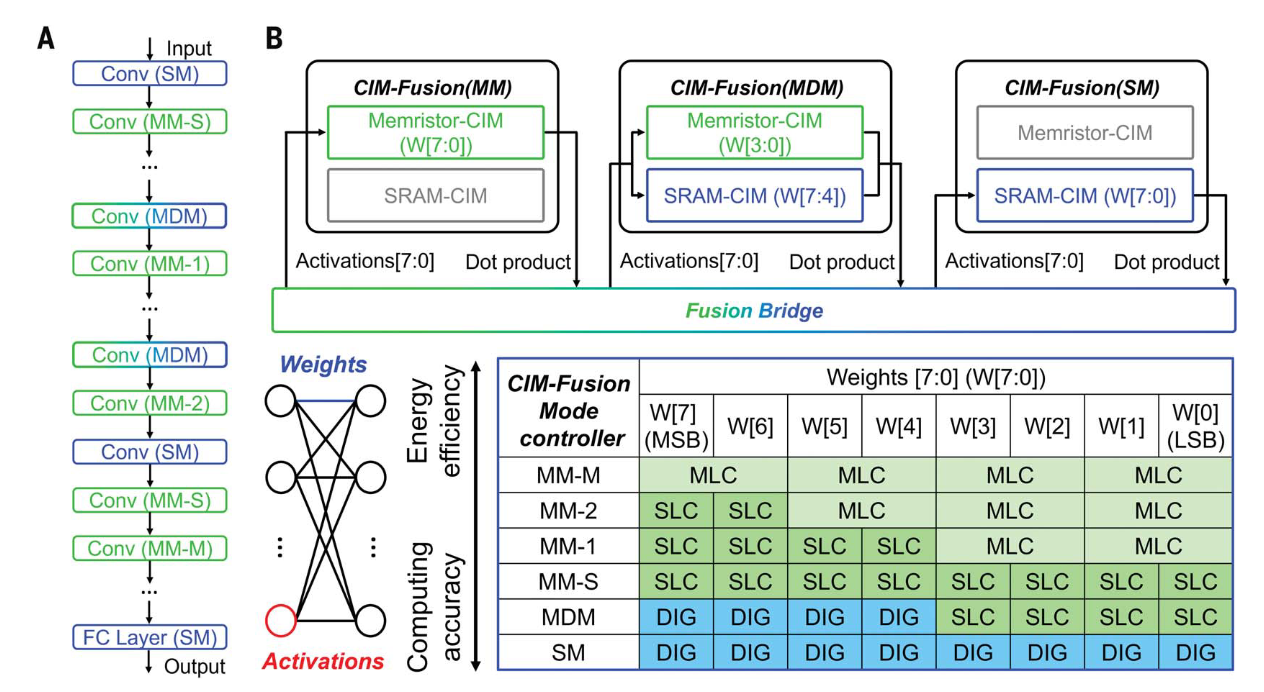
神经网络不同计算对精度需求是不一样的,核心部分对精度的需求更大,而其余部分对精度要求相对较低。这也是各种复杂量化策略层出不穷的原因。
基于这个先验,我们可以牺牲一部分网络精度,换取其他指标的提升。这个核心立意继承之前的工作[3],只是加上 SRAM 后又添加了几种新模式。
这分为俩个层次,layer wise 和 in-layer。不同的 layer 可以部署在不同的模式。在同一层,更高位 bit(数值更大的数据)对结果的贡献比低位 bit 贡献更大,因此对同一个数据不同精度的混合模式,都是把高精度放在高位。
除了权重部署,每次执行求和操作数数量也会影响精度,更多的数据相加,带来更大的 throughput 和更低的精度(Voltage supply 不变,更多数据相加需要减小单位 bit-line current 从而受到噪声影响更大)。这篇工作使用 dynamic accumulation 在 throughput 和 precision 之间 trade-off。
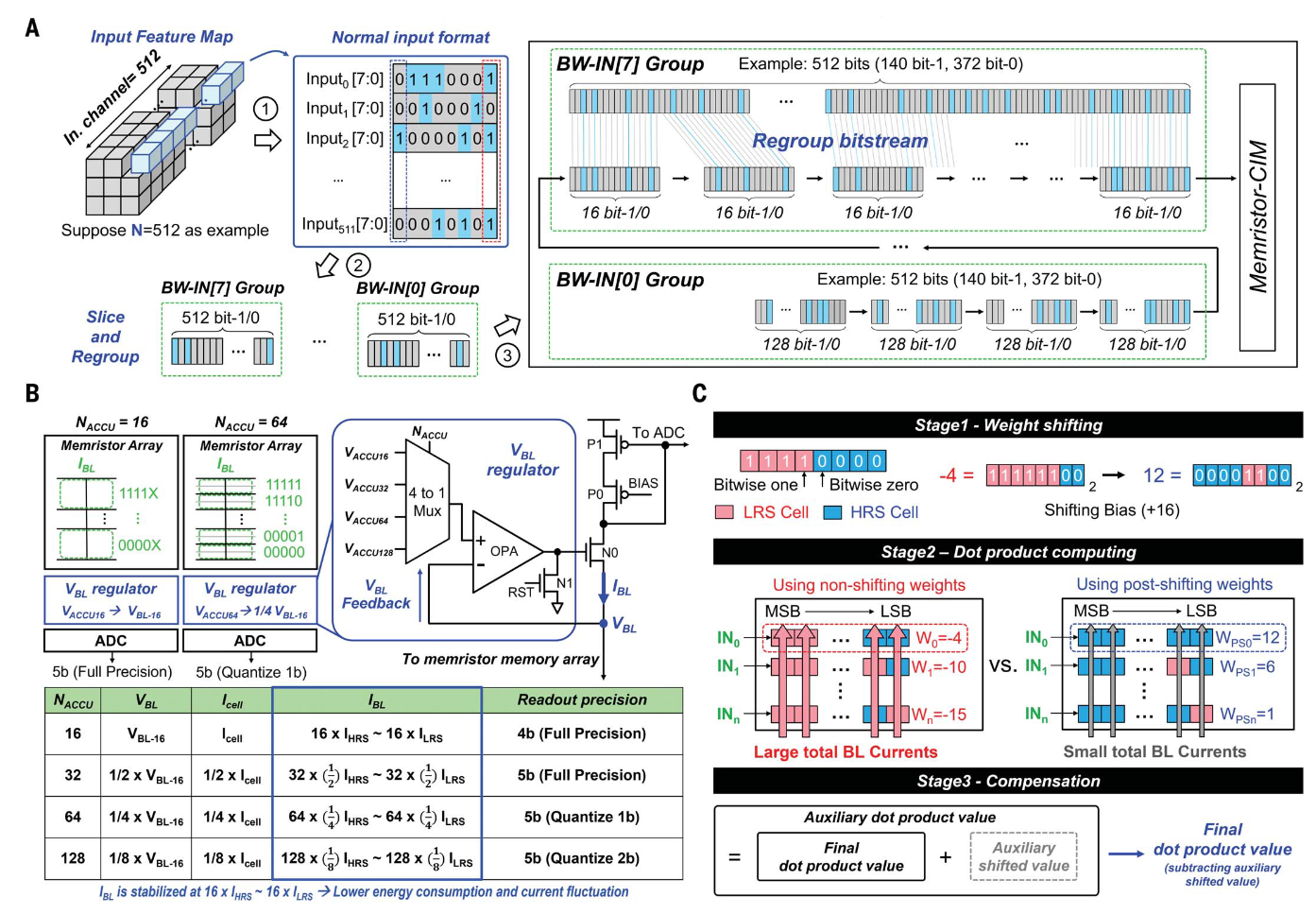
Adaptive Local Training
之前的 RRAM on-chip learning 要大量擦写 RRAM,而本篇工作 forward 时部分权重部署在 SRAM 上,那么我们固定 RRAM 上的权重,而只修改 SRAM 那部分,用 SRAM 那部分权重修正其余部分 RRAM 噪声带来的影响,从而减少 on-chip training 的写入开销。实际实施 SRAM 的权重只占整体很小一部分,有些网络一次推理中还要多次擦写 SRAM。
写入无法彻底避免,毕竟不涉及 DRAM / SSD,SRAM forward 的权重也是通过 weight transfer 从 RRAM 中读出来的,最终训练完了还是要写回去。
而训练时产生的大量中间变量放置在 512 KB 的片上 buffer,实现彻底纯片上训练[4]。
Conclusion
本篇工作选择的工艺节点是 22 nm 流片,如果要在更高节点下模拟精度问题进一步扩大,模拟计算相比纯数字范式吸引力大大降低。虽然 RRAM SRAM Fusion CIM 名称很好听,但正如前文所说,本篇工作还是在 RRAM 赛道上驰骋。
Wen, T.-H., Hung, J.-M., Huang, W.-H., Jhang, C.-J., Lo, Y.-C., Hsu, H.-H., Ke, Z.-E., Chen, Y.-C., Chin, Y.-H., Su, C.-I., Khwa, W.-S., Lo, C.-C., Liu, R.-S., Hsieh, C.-C., Tang, K.-T., Ho, M.-S., Chou, C.-C., Chih, Y.-D., Chang, T.-Y. J., & Chang, M.-F. (2024). Fusion of memristor and digital compute-in-memory processing for energy-efficient edge computing. Science, 384(6693), 325–332. https://doi.org/10.1126/science.adf5538 ↩︎
A100 数据来源见 Song, X., Wen, Y., Hu, X., Liu, T., Zhou, H., Han, H., Zhi, T., Du, Z., Li, W., Zhang, R., Zhang, C., Gao, L., Guo, Q., & Chen, T. (2023). Cambricon-R: A Fully Fused Accelerator for Real-Time Learning of Neural Scene Representation. 56th Annual IEEE/ACM International Symposium on Microarchitecture, 1305–1318. https://doi.org/10.1145/3613424.3614250 ↩︎
Hsu, H.-H., Wen, T.-H., Huang, W.-H., Khwa, W.-S., Lo, Y.-C., Jhang, C.-J., Chin, Y.-H., Chen, Y.-C., Lo, C.-C., Liu, R.-S., Tang, K.-T., Hsieh, C.-C., Chih, Y.-D., Chang, T.-Y. J., & Chang, M.-F. (2024). A Nonvolatile AI-Edge Processor With SLC–MLC Hybrid ReRAM Compute-in-Memory Macro Using Current–Voltage-Hybrid Readout Scheme. IEEE Journal of Solid-State Circuits, 59(1), 116–127. https://doi.org/10.1109/JSSC.2023.3314433 ↩︎
涂老师指出补充 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号