MySQL高级知识(十六)——小表驱动大表
前言:本来小表驱动大表的知识应该在前面就讲解的,但是由于之前并没有学习数据批量插入,因此将其放在这里。在查询的优化中永远小表驱动大表。
1.为什么要小表驱动大表呢
类似循环嵌套
for(int i=5;.......)
{
for(int j=1000;......)
{}
}
如果小的循环在外层,对于数据库连接来说就只连接5次,进行5000次操作,如果1000在外,则需要进行1000次数据库连接,从而浪费资源,增加消耗。这就是为什么要小表驱动大表。
2.数据准备
根据MySQL高级知识(十)——批量插入数据脚本中的相应步骤在tb_dept_bigdata表中插入100条数据,在tb_emp_bigdata表中插入5000条数据。
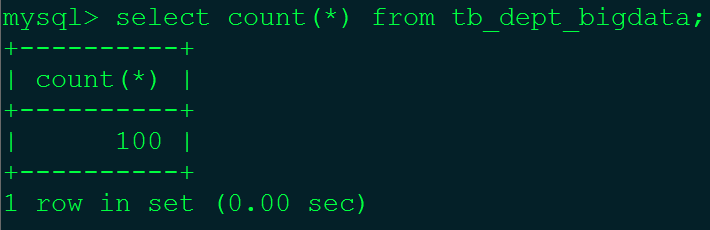
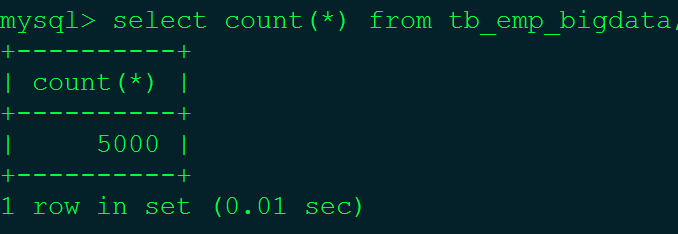
注:100个部门,5000个员工。tb_dept_bigdata(小表),tb_emp_bigdata(大表)。
3.案例演示
①当B表的数据集小于A表数据集时,用in优于exists。
select *from tb_emp_bigdata A where A.deptno in (select B.deptno from tb_dept_bigdata B)
B表为tb_dept_bigdata:100条数据,A表tb_emp_bigdata:5000条数据。
用in的查询时间为:

将上面sql转换成exists:
select *from tb_emp_bigdata A where exists(select 1 from tb_dept_bigdata B where B.deptno=A.deptno);
用exists的查询时间:

经对比可看到,在B表数据集小于A表的时候,用in要优于exists,当前的数据集并不大,所以查询时间相差并不多。
②当A表的数据集小于B表的数据集时,用exists优于in。
select *from tb_dept_bigdata A where A.deptno in(select B.deptno from tb_emp_bigdata B);
用in的查询时间为:

将上面sql转换成exists:
select *from tb_dept_bigdata A where exists(select 1 from tb_emp_bigdata B where B.deptno=A.deptno);
用exists的查询时间:

由于数据量并不是很大,因此对比并不是难么的强烈。
附上视频的结论截图:

4.总结
下面结论都是针对in或exists的。
in后面跟的是小表,exists后面跟的是大表。
简记:in小,exists大。
对于exists
select .....from table where exists(subquery);
可以理解为:将主查询的数据放入子查询中做条件验证,根据验证结果(true或false)来决定主查询的数据是否得以保留。
by Shawn Chen,2018.6.30日,下午。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号