PostgreSQL:进程结构
本文分享自天翼云开发者社区@《PostgreSQL:进程结构》,作者: 周*****平
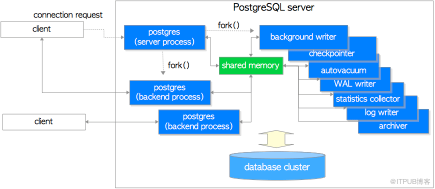
Postgresql 是一个C/S架构的关系型数据库,由多个后台进程管理数据库,下面分别介绍一些这些进程
postgres server process 一个服务器端进程,是所有进程的父进程。该进程管理数据库文件,接受客户端与数据库的连接,且代表客户端对数据库进行操作。该进程的程序名叫做 postgres。
backend process 每一个客户端的连接都有一个后端进程存在
backgroud processes 为管理数据库而产生的一些进程
backgroud work processes 9.3 以后版本开始有这个进程,这里不做详细介绍
postgres server process
管理后端的常驻进程,是所有进程的父进程,早期的版本叫 ’postmaster’。
主要职责:
数据库的启停
监听客户端连接。
为每个客户连接 fork 单独的 postgres 服务进程。
当服务进程出错时进行修复。
管理数据文件。
管理与数据库运行相关的辅助进程
流程如下:
1.pg_ctl start 执行后,这个进程就会启动
2.从物理内存中分配内给给 shared memory,然后产生很多其他的 backgroup processes
3.等待客户端连接,每产生一个连接就会生成一个 backend process,一个 postgres server process 只能监听一个端口,默认端口是 5432。

一旦有前端连接过来,postgres 会通过 fork(2) 生成子进程。没有 Fork(2) 的 windows 平台的话,则利用 createProcess() 生成新的进程。这种情形的话,和 fork(2) 不同的是,父进程的数据不会被继承过来,所以需要利用共享内存把父进程的数据继承过来。
backend processes
通过 TCP 协议和客户端建立通讯,当客户端断开时,连接消失。允许多个客户端同时连接,连接数由 max_connections 参数控制,默认是 100,如果客户端频繁的和服务端建立连接然后断开,会增加数据库的开销,导致服务器负载不正常,因为数据库本身不提供连接池的功能,如果有需要,可以使用 pgbouncer 或者 pgpool-II。
后端的处理流程
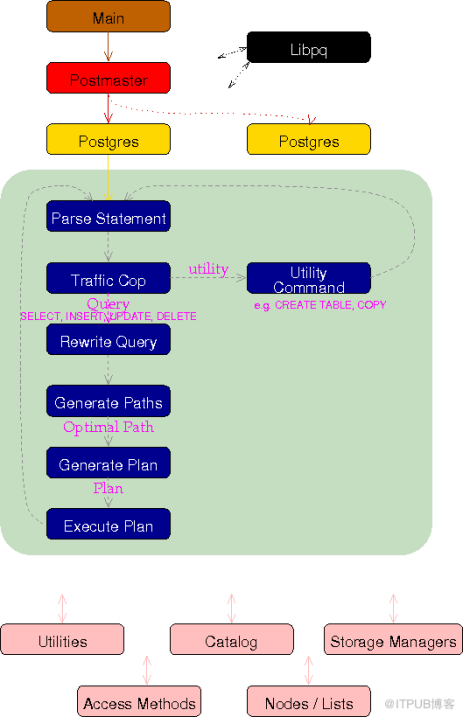
下面看看数据库引擎 postgres 子进程的处理概要。为了简单起见下面的说明中,把 backendprocess 简称为backend。Backend 的 main 函数是 PostgresMain (tcop/postgres.c)。
1.接收前端发送过来的查询(SQL文)
2.SQL文是单纯的文字,电脑是认识不了的,所以要转换成比较容易处理的内部形式构文树parser tree,这个处理的称为构文解析。构文解析的模块称为parser.这个阶段只能够使用文字字面上得来的信息,所以只要没语法错误之类的错误,即使是select不存在的表也不会报错。这个阶段的构文树被称为raw parse tree. 构文处理的入口在raw_parser (parser/parser.c)。
3.构文树解析完以后,会转换为查询树(Query tree)。这个时候,会访问数据库,检查表是否存在,如果存在的话,则把表名转换为OID。这个处理称为分析处理(Analyze), 进行分析处理的模块是analyzer。 另外,PostgreSQL的代码里面提到构文树parser tree的时候,更多的时候是指查询树Query tree。分析处理的模块的入口在parse_analyze (parser/analyze.c)
4.PostgreSQL还通过查询语句的重写实现视图(view)和规则(rule), 所以需要的时候,在这个阶段会对查询语句进行重写。这个处理称为重写(rewrite),重写的入口在QueryRewrite (rewrite/rewriteHandler.c)。
5.通过解析查询树,可以实际生成计划树。生成查询树的处理称为‘执行计划处理’,最关键是要生成估计能在最短的时间内完成的计划树(plan tree)。这个步骤称为’查询优化’(不叫query optimize, 而是optimize), 而完成这个处理的模块称为查询优化器(不叫query optimizer,而是optimizer, 或者称为planner)。执行计划处理的入口在standard_planner (optimizer/plan/planner.c)。
6.按照执行计划里面的步骤可以完成查询要达到的目的。运行执行计划树里面步骤的处理称为执行处理‘execute’, 完成这个处理的模块称为执行器‘Executor’, 执行器的入口地址为,ExecutorRun (executor/execMain.c)
7.执行结果返回给前端。
8.返回到步骤一重复执行。
backgroud processes
根据 pg_hba.conf 定义的安全策略来判断是否允许进行连接,根据策略,会拒绝某些特定的 IP 及网络,或者也可以只允许某些特定的用户或者对某些数据库进行连接。
Postgres 会接受前端过来的查询,然后对数据库进行检索,最好把结果返回,有时也会对数据库进行更新。更新的数据同时还会记录在事务日志里面(PostgreSQL 称为 WAL 日志),这个主要是当停电的时候,服务器当机,重新启动的时候进行恢复处理的时候使用的。另外,把日志归档保存起来,可在需要进行恢复的时候使用。在 PostgreSQL 9.0 以后,通过把 WAL 日志传送其他的 postgreSQL,可以实时得进行数据库复制,这就是所谓的‘数据库复制’功能。
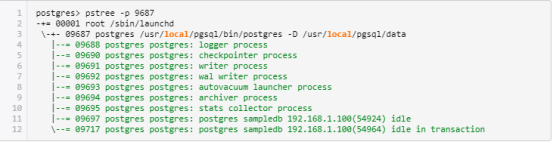
这里显示了 PostgreSQL 数据库的进程信息。在以下示例中,一个 postgres 服务器进程(pid 为 9687),两个后端进程(pids 为 9697 和 9717)以及表 2.1 中列出的几个后台进程正在运行。
PostgreSQL 数据库系统的主要功能都集中于 Postgres 程序,其入口是 Main 模块中的 main 函数,在初始化数据集簇,启动数据库服务器是,都将从这里开始执行。Main 模块主要的工作时确定当前的操作系统平台,并据此做一些平台相关的环境变量设置和初始化,然后通过对命令行参数的判断,将控制转到相应的模块中去。下图是 main 函数的调用流程。

PostgreSQL 系统主函数 main 的流程
PostgreSQL 守护进程 Postmaster 为用户连接请求分配后台 Postgres 服务进程,还将启动相关的后台服务进程:SysLogger(系统日志进程)、PgStat(统计数据收集进程)、AutoVacuum(系统自动清理进程)。在 Postmaster 进入到循环监听中时启动如下进行:BgWriter(后台写进程)、WalWriter(预写式日志写进程)、PgArch(预写式日志归档进程)。这些进程将在后续文章中介绍。
下图是 PostgreSQL 的后台流程图:
blackground writer
Writer process 在适当的时间点把共享内存上的缓存写往磁盘。通过这个进程,可以防止在检查点的时候(checkpoint),大量的往磁盘写而导致性能恶化,使得服务器可以保持比较稳定的性能。Background writer 起来以后就一直常驻内存,但是并非一直在工作,它会在工作一段时间后进行休眠,休眠的时间间隔通过postgresql.conf 里面的参数 bgwriter_delay 设置,默认是 200 微秒。
这个进程的另外一个重要的功能是定期执行检查点(checkpoint)。
检查点的时候,会把共享内存上的缓存内容往数据库文件写,使得内存和文件的状态一致。通过这样,可以在系统崩溃的时候可以缩短从 WAL 恢复的时间,另外也可以防止 WAL 无限的增长。 可以通过 postgresql.conf 的 checkpoint_segments、checkpoint_timeout 指定执行检查点的时间间隔。
Writer 进程是把共享内存中的脏页写到磁盘上的进程。它的作用有两个:一是定期把脏数据从内存缓冲区刷出到磁盘中,减少查询时的阻塞;二是 PG 在定期作检查点时需要把所有脏页写出到磁盘,通过 BgWriter 预先写出一些脏页,可以减少设置检查点(CheckPoint,数据库恢复技术的一种)时要进行的IO操作,使系统的IO负载趋向平稳。BgWriter 是 PostgreSQL8.0 以后新加的特性,它的机制可以通过 postgresql.conf 文件中以"bgwriter_"开头配置参数来控制:
bgwriter_delay:backgroud writer 进程连续两次 flush 数据之间的时间的间隔。默认值是 200,单位是毫秒。
bgwriter_lru_maxpages:backgroud writer 进程每次写的最多数据量,默认值是 100,单位 buffers。如果脏数据量小于该数值时,写操作全部由 backgroud writer 进程完成;反之,大于该值时,大于的部分将有 server process 进程完成。设置该值为0时表示禁用 backgroud writer 写进程,完全有 server process 来完成;配置为-1时表示所有脏数据都由 backgroud writer 来完成。(这里不包括 checkpoint 操作)
bgwriter_lru_multiplier:这个参数表示每次往磁盘写数据块的数量,当然该值必须小于 bgwriter_lru_maxpages。设置太小时需要写入的脏数据量大于每次写入的数据量,这样剩余需要写入磁盘的工作需要 server process 进程来完成,将会降低性能;值配置太大说明写入的脏数据量多于当时所需 buffer 的数量,方便了后面再次申请 buffer 工作,同时可能出现 IO 的浪费。该参数的默认值是 2.0。
bgwriter 的最大数据量计算方式:
1000/bgwriter_delay\*bgwriter_lru_maxpages\*8K = 最大数据量
bgwriter_flush_after:数据页大小达到 bgwriter_flush_after 时触发 BgWriter,默认是 512KB。
vacuum进程
Autovacuum(自动清理)启动进程
autovacuum launcher process 是依赖于 postmaster 间接启动 vacuum 进程。而其自身是不直接启动自动vacuum进程的。通过这样可以提高系统的可靠性。
在 PG 数据库中,对数据进行 UPDATE 或者 DELETE 操作后,数据库不会立即删除旧版本的数据,而是标记为删除状态。这是因为PG数据库具有多版本的机制,如果这些旧版本的数据正在被另外的事务打开,那么暂时保留他们是很有必要的。当事务提交后,旧版本的数据已经没有价值了,数据库需要清理垃圾数据腾出空间,而清理工作就是 AutoVacuum 进程进行的。postgresql.conf 文件中与 AutoVacuum 进程相关的参数有:
autovacuum:是否启动系统自动清理功能,默认值为 on。
log_autovacuum_min_duration:这个参数用来记录 autovacuum 的执行时间,当 autovaccum 的执行时间超过 log_autovacuum_min_duration 参数设置时,则 autovacuum 信息记录到日志里,默认为 "-1", 表示不记录。
autovacuum_max_workers:设置系统自动清理工作进程的最大数量。
autovacuum_naptime:设置两次系统自动清理操作之间的间隔时间。
autovacuum_vacuum_threshold 和 autovacuum_analyze_threshold:设置当表上被更新的元组数的阈值超过这些阈值时分别需要执行 vacuum 和 analyze。
autovacuum_vacuum_scale_factor 和 autovacuum_analyze_scale_factor:设置表大小的缩放系数。
autovacuum_freeze_max_age:设置需要强制对数据库进行清理的XID上限值。
autovacuum_vacuum_cost_delay:当 autovacuum 进程即将执行时,对 vacuum 执行 cost 进行评估,如果超过 autovacuum_vacuum_cost_limit 设置值时,则延迟,这个延迟的时间即为 autovacuum_vacuum_cost_delay。如果值为 -1,表示使用 vacuum_cost_delay 值,默认值为 20 ms。
autovacuum_vacuum_cost_limit:这个值为 autovacuum 进程的评估阀值, 默认为 -1,表示使用 "vacuum_cost_limit " 值,如果在执行 autovacuum 进程期间评估的 cost 超过autovacuum_vacuum_cost_limit,则 autovacuum 进程则会休眠。
自动vacuum进程
autovacuum worker process 进程实际执行 vacuum 的任务。有时候会同时启动多个 vacuum 进程。
WAL writer(预写式日志写)
WAL writer process 把共享内存上的 WAL 缓存在适当的时间点往磁盘写,通过这样,可以减轻后端进程在写自己的 WAL 缓存时的压力,提高性能。另外,非同步提交设为 true 的时候,可以保证在一定的时间间隔内,把 WAL 缓存上的内容写入 WAL 日志文件。
预写式日志 WAL(Write Ahead Log,也称为 Xlog)的中心思想是对数据文件的修改必须是只能发生在这些修改已经记录到日志之后,也就是先写日志后写数据(日志先行)。使用这种机制可以避免数据频繁的写入磁盘,可以减少磁盘 I/O。数据库在宕机重启后可以运用这些 WAL 日志来恢复数据库。postgresql.conf 文件中与 WalWriter 进程相关的参数如下:
wal_level:控制 wal 存储的级别。wal_level 决定有多少信息被写入到 WAL 中。 默认值是最小的(minimal),其中只写入从崩溃或立即关机中恢复的所需信息。replica 增加 wal 归档信息同时包括只读服务器需要的信息。(9.6 中新增,将之前版本的 archive 和 hot_standby 合并)
logical 主要用于logical decoding 场景
fsync:该参数直接控制日志是否先写入磁盘。默认值是 ON(先写入),表示更新数据写入磁盘时系统必须等待 WAL 的写入完成。可以配置该参数为 OFF,表示更新数据写入磁盘完全不用等待 WAL 的写入完成。
synchronous_commit:参数配置是否等待 WAL 完成后才返回给用户事务的状态信息。默认值是 ON,表明必须等待 WAL 完成后才返回事务状态信息;配置成 OFF 能够更快地反馈回事务状态。
wal_sync_method:WAL 写入磁盘的控制方式,默认值是 fsync,可选用值包括 open_datasync、fdatasync、fsync_writethrough、fsync、open_sync。open_datasync 和 open_sync 分别表示在打开 WAL文件时使用 O_DSYNC 和 O_SYNC 标志;fdatasync 和 fsync 分别表示在每次提交时调用 fdatasync 和 fsync 函数进行数据写入,两个函数都是把操作系统的磁盘缓存写回磁盘,但前者只写入文件的数据部分,而后者还会同步更新文件的属性;fsync_writethrough 表示在每次提交并写回磁盘会保证操作系统磁盘缓存和内存中的内容一致。
full_page_writes:表明是否将整个 page 写入 WAL。
wal_buffers:用于存放 WAL 数据的内存空间大小,系统默认值是 64K,该参数还受 wal_writer_delay、commit_delay 两个参数的影响。
wal_writer_delay:WalWriter 进程的写间隔时间,默认值是 200 毫秒,如果时间过长可能造成 WAL 缓冲区的内存不足;时间过短将会引起 WAL 的不断写入,增加磁盘 I/O 负担。
commit_delay:表示一个已经提交的数据在 WAL 缓冲区中存放的时间,默认值是 0 毫秒,表示不用延迟;设置为非 0 值时事务执行 commit 后不会立即写入 WAL 中,而仍存放在 WAL 缓冲区中,等待 WalWriter 进程周期性地写入磁盘。
commit_siblings:表示当一个事务发出提交请求时,如果数据库中正在执行的事务数量大于 commit_siblings 值,则该事务将等待一段时间(commit_delay 的值);否则该事务则直接写入 WAL。系统默认值是 5,该参数还决定了 commit_delay 的有效性。
wal_writer_flush_after:当脏数据超过阈值时,会被刷出到磁盘。
CheckPoint(检查点)进程
检查点是系统设置的事务序列点,设置检查点保证检查点前的日志信息刷到磁盘中。postgresql.conf 文件中与之相关的参数有:
stats collector process
统计信息的收集进程。收集好统计表的访问次数,磁盘的访问次数等信息。收集到的信息除了能被 autovaccum 利用,还可以给其他数据库管理员作为数据库管理的参考信息。
PgStat 进程是 PostgreSQL 数据库的统计信息收集器,用来收集数据库运行期间的统计信息,如表的增删改次数,数据块的个数,索引的变化等等。收集统计信息主要是为了让优化器做出正确的判断,选择最佳的执行计划。 postgresql.conf 文件中与 PgStat 进程相关的参数,如下:
track_activities:表示是否对会话中当前执行的命令开启统计信息收集功能,该参数只对超级用户和会话所有者可见,默认值为 on(开启)。
track_counts:表示是否对数据库活动开启统计信息收集功能,由于在 AutoVacuum 自动清理进程中选择清理的数据库时,需要数据库的统计信息,因此该参数默认值为 on。
track_io_timing:定时调用数据块 I/O,默认是 off,因为设置为开启状态会反复的调用数据库时间,这给数据库增加了很多开销。只有超级用户可以设置
track_functions:表示是否开启函数的调用次数和调用耗时统计。
track_activity_query_size:设置用于跟踪每一个活动会话的当前执行命令的字节数,默认值为 1024,只能在数据库启动后设置。
stats_temp_directory:统计信息的临时存储路径。路径可以是相对路径或者绝对路径,参数默认为 pg_stat_tmp,设置此参数可以减少数据库的物理 I/O,提高性能。此参数只能在 postgresql.conf 文件或者服务器命令行中修改。
Logging collector
把 postgresql 的活动状态写到日志信息文件(并非事务日志),在指定的时间间隔里面,对日志文件进行 rotate.
Archiver
Archive process 把 WAL 日志转移到归档日志里。如果保存了基础备份以及归档日志,即使实在磁盘完全损坏的时候,也可以回复数据库到最新的状态。
类似于 Oracle 数据库的 ARCH 归档进程,不同的是 ARCH 是吧 redo log 进行归档,PgArch 是把 WAL 日志进行归档。再深入点,WAL 日志会被循环使用,也就是说,过去的 WAL 日志会被新产生的日志覆盖,PgArch 进程就是为了在覆盖前把 WAL 日志备份出来。归档日志的作用是为了数据库能够使用全量备份和备份后产生的归档日志,从而让数据库回到过去的任一时间点。PG 从 8.X 版本开始提供的 PITR(Point-In-Time-Recovery)技术,就是运用的归档日志。
PgArch 进程通过 postgresql.conf 文件中的如下参数进行
archive_mode:表示是否进行归档操作,可选择为 off(关闭)、on(启动)和 always(总是开启),默认值为 off(关闭)。
archive_command:由管理员设置的用于归档 WAL 日志的命令。在用于归档的命令中,预定义变量“%p”用来指代需要归档的 WAL 全路径文件名,“%f”表示不带路径的文件名(这里的路径都是相对于当前工作目录的路径)。每个WAL段文件归档时将调用archive_command所指定的命令。当归档命令返回 0 时,PostgreSQL 就会认为文件被成功归档,然后就会删除或循环使用该 WAL 段文件。否则,如果返回一个非零值,PostgreSQL 会认为文件没有被成功归档,便会周期性地重试直到成功。
archive_timeout:表示归档周期,在超过该参数设定的时间时强制切换 WAL 段,默认值为 0(表示禁用该功能)。
wal sender / wal receiver
wal sender 进程和 wal receiver 进程是实现 postgresql 复制(streaming replication)的进程。Wal sender 进程通过网络传送 WAL 日志,而其他 PostgreSQL 实例的 wal receiver 进程则接收相应的日志。Wal receiver 进程的宿主PostgreSQL(也称为 Standby)接受到 WAL 日志后,在自身的数据库上还原,生成一个和发送端的 PostgreSQL(也称为 Master)完全一样的数据库。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31490526/viewspace-2716590/,如需转载,请注明出处,否则将追究法律责任。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号