
从0开始学大数据
一、大数据起源
从 2003 年开始,互联网巨头谷歌先后发表了 3 篇论文:《The Google File System》《MapReduce:Simplified Data Processing on Large Clusters》《Bigtable:A Distributed Storage System for Structed Data》。
这三篇论文奠定了现代大数据的技术基础。它们提出了一种新的,面向数据分析的海量异构数据的统一计算、存储的方法。
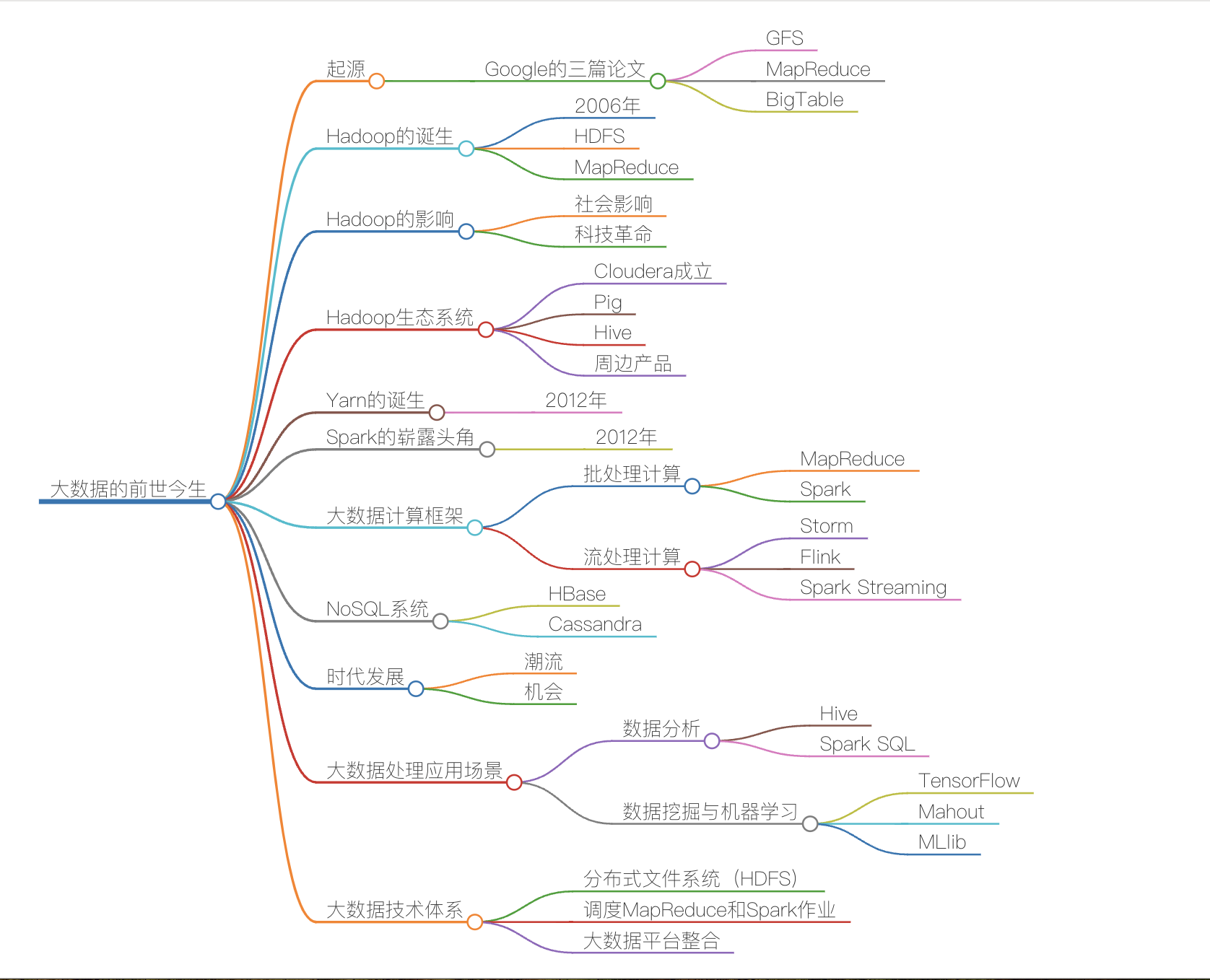
二、Hadoop
2.1 Hadoop介绍
Hadoop:Hadoop 是一个开源的、分布式计算框架,专门设计用于在由普通商用硬件组成的集群上可靠地存储和处理海量数据(大数据)。
它的核心思想是:将巨大的数据集分割成小块,并将这些块分散存储在多台机器上(存储),然后利用这些机器并行处理数据(计算),从而显著提高处理速度和效率。
大数据平台的底层是以 Hadoop 为代表的基础设施,分为计算、资源调度和存储。
Hadoop,主要包括 Hadoop 分布式文件系统 HDFS 和大数据计算引擎 MapReduce,YARN。
Hadoop Distributed File System: 是一个高度容错的分布式文件系统。负责存储海量数据。
Hadoop MapReduce:一个用于并行处理存储在 HDFS 上的海量数据集的编程模型和计算框架。
YARN:Yet Another Resource Negotiator。在 Hadoop 2.x 中引入,是集群的资源管理和作业调度系统。
2.2 通俗易懂地介绍 Hadoop


2.3 Hadoop的优势:
Hadoop 的核心优势在于解决大数据或传统数据仓库带来的挑战:
- 数据量巨大: 传统数据库难以存储和处理 TB、PB 甚至 EB 级别的数据。
- 处理速度要求: 单台机器处理海量数据耗时过长,无法满足需求。(超强计算能力: 成百上千台机器并行计算,速度飞快。)
- 成本: 使用昂贵的高端服务器存储和处理海量数据成本极高。(花小钱办大事: 不需要昂贵的大型机,用普通PC服务器组集群。)
- 可靠性: 单台机器故障可能导致数据丢失或任务失败。(高容错: 机器挂了?数据丢了?别怕!多副本机制让你的数据和工作任务自动恢复(HDFS副本 + YARN任务重试)。)
- 高扩展性:数据或计算需求变大了?加机器(节点)就行了,几乎能线性扩展。
- 批处理利器:非常适合处理历史数据批量分析(比如日志分析、ETL、数据仓库)
2.4 Hadoop 生态系统
围绕 HDFS, MapReduce 和 YARN 这三个核心,Hadoop 发展出了一个极其丰富的生态系统,包含众多工具和框架,用于解决不同的大数据问题:
-
Hive: 数据仓库工具,提供类似 SQL 的查询语言(HiveQL),将查询转换为 MapReduce、Tez 或 Spark 作业。适合数据摘要、查询和分析。
-
Pig: 高级脚本语言平台,用于表达复杂的数据转换流程,最终转换为 MapReduce 作业。
-
HBase: 构建在 HDFS 之上的分布式、可伸缩的 NoSQL 数据库,支持实时读写随机访问。
-
Spark: 一个快速、通用的大规模数据处理引擎(内存计算)。可以运行在 YARN 上,速度远超 MapReduce,支持批处理、流处理、机器学习和图计算。
-
ZooKeeper: 分布式协调服务,用于维护配置信息、命名、提供分布式同步和组服务(如 HBase 的主节点选举依赖它)。
-
Sqoop: 用于在 Hadoop 和关系型数据库(如 MySQL, Oracle)之间高效传输批量数据。
-
Flume: 用于高效收集、聚合和移动大量日志数据到 HDFS。
-
Oozie: 工作流调度系统,用于管理和协调 Hadoop 作业(如 MapReduce, Pig, Hive, Sqoop 等)。
-
Mahout: 可扩展的机器学习算法库(现在很多场景被 Spark MLlib 取代)。
-
Ambari: 用于 Hadoop 集群的供应、管理和监控。
-
Kafka: 分布式流处理平台(虽然独立,但常与 Hadoop 生态集成),用于构建实时数据管道和流应用。
Hive、Spark、Flink、Impala 提供了大数据计算引擎:Hive、Spark 主要解决离线数据清洗、加工的场景,目前,Spark 用得越来越多,性能要比 Hive 高不少;Flink 主要是解决实时计算的场景;Impala 主要是解决交互式查询的场景。
三、 待输入
2013年大数据元年。
分布式文件系统 GFS、大数据分布式计算框架 MapReduce 和 NoSQL 数据库系统 BigTable。
Hadoop,主要包括 Hadoop 分布式文件系统 HDFS 和大数据计算引擎 MapReduce。
Facebook发布Hive。Hive 支持使用 SQL 语法来进行大数据计算,比如说你可以写个 Select 语句进行数据查询,然后 Hive 会把 SQL 语句转化成 MapReduce 的计算程序。
分布式文件系统HDFS,大数据分布式计算框架 Hive ,NoSQL 数据库系统-HBase。

通过从数据库,日志等获取的数据,sqoop,flume导入到大数据产品HDFS储存。Mapreduce,spark对储存的数据进行批计算处理,flink,storm等进行实时处理。Yarn负责对数据的资源调度。
名词解释:
1.
Hadoop生态
HDFS 分布式文件系统
MapReduce 大数据计算引擎
Hive 使用SQL进行大数据计算 - 将SQL转换为MapReduce的计算过程
Sqoop 将关系型数据库导入到Hadoop平台
Flume 大规模日志分布式收集聚合传输
Oozie MapReduce工作流调度
Yarn 资源调度,从MapReduce分离
Spark :MapReduce的升级,使用内存作为存储介质
离线计算框架: MapReuce、Spark 离
流式计算框架: Strom、Flink、Spark Streaming
2.
大数据应用: 数据分析 Hive 、Spark SQL
数据挖掘与机器学习: TensorFlow、Mahout、MLlib
