
高可用架构模式——CAP
一、高可用架构模式——CAP
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。
对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
一致性(Consistency):A read is guaranteed to return the most recent write for a given client/对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
可用性(Availability):A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout)/非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
分区容忍性(Partition Tolerance):The system will continue to function when network partitions occur/当出现网络分区后,系统能够继续“履行职责”。
虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证 C,系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A 冲突了,因为 A 要求返回 no error 和 no timeout。
因此,分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
二、FMEA
FMEA(Failure mode and effects analysis,故障模式与影响分析)
在架构设计领域,FMEA 的具体分析方法是:
- 给出初始的架构设计图。
- 假设架构中某个部件发生故障。
- 分析此故障对系统功能造成的影响。
- 根据分析结果,判断架构是否需要进行优化。
常见的 FMEA 分析表格包含下面部分。
1.功能点
注意这里的“功能点”指的是从用户角度来看的,而不是从系统各个模块功能点划分来看的。
2.故障模式
3.故障影响
常见的影响有:功能点偶尔不可用、功能点完全不可用、部分用户功能点不可用、功能点响应缓慢、功能点出错等
4.严重程度
严重程度指站在业务的角度故障的影响程度,一般分为“致命 / 高 / 中 / 低 / 无”五个档次。
严重程度 = 功能点重要程度 × 故障影响范围 × 功能点受损程度。
5.故障原因
6.故障概率
指某个具体故障原因发生的概率。一般分为“高 / 中 / 低”三档即可。
7.风险程度
8.已有措施
9.规避措施
10.解决措施
三、高可用存储架构:双机架构
对任何一个高可用存储方案,我们需要从以下几个方面去进行思考和分析:
- 数据如何复制?
- 各个节点的职责是什么?
- 如何应对复制延迟?
- 如何应对复制中断?
主备复制
内部的后台管理系统使用主备复制架构的情况会比较多。
主从复制
一般情况下,写少读多的业务使用主从复制的存储架构比较多。
双机切换
在主备切换和主从切换两种方案的基础上增加“切换”功能,即系统自动决定主机角色,并完成角色切换。
主主复制
主主复制架构对数据的设计有严格的要求,一般适合于那些临时性、可丢失、可覆盖的数据场景(主主架构因其固有的双向复杂性,很少在实际中使用)。
常见的主备切换架构有三种形式:互连式、中介式和模拟式。
中介式的缺点:中介宕机,系统进入双备状态,写操作不可用。
开源方案已经有比较成熟的中介式解决方案,例如 ZooKeeper 和 Keepalived。
ZooKeeper 本身已经实现了高可用集群架构,因此已经帮我们解决了中介本身的可靠性问题,
在工程实践中推荐基于 ZooKeeper 搭建中介式切换架构。
模拟式指主备机之间并不传递任何状态数据,而是备机模拟成一个客户端,向主机发起模拟的读写操作,根据读写操作的响应情况来判断主机的状态
四、高可用存储架构:集群和分区
数据集中集群架构中,客户端只能将数据写到主机;
数据分散集群架构中,客户端可以向任意服务器中读写数据。
正是因为这个关键的差异,决定了两种集群的应用场景不同。一般来说,数据集中集群适合数据量不大,集群机器数量不多的场景。
例如,ZooKeeper 集群,一般推荐 5 台机器左右,数据量是单台服务器就能够支撑;而数据分散集群,由于其良好的可伸缩性,适合业务数据量巨大、集群机器数量庞大的业务场景。例如,Hadoop 集群、HBase 集群,大规模的集群可以达到上百台甚至上千台服务器。
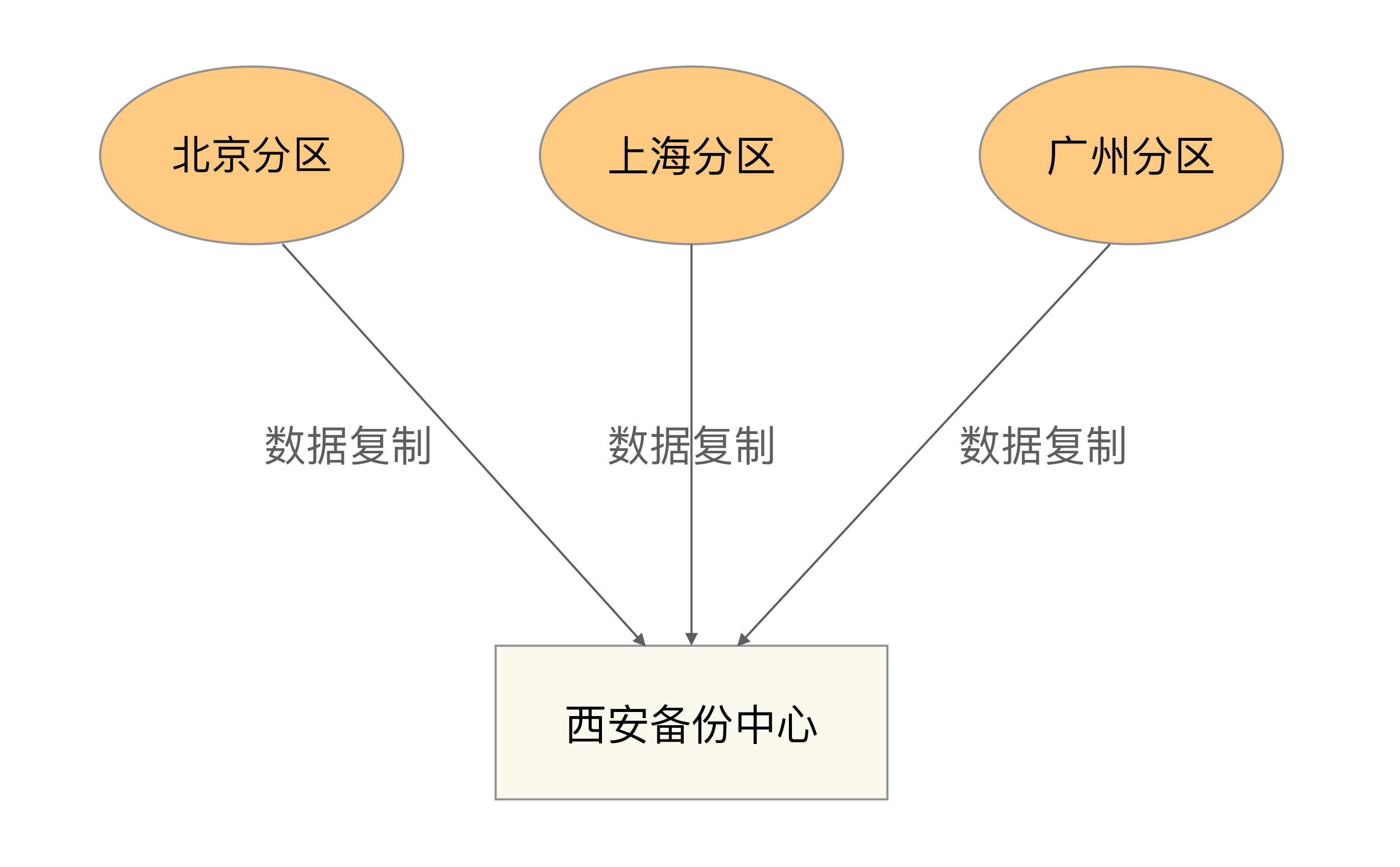
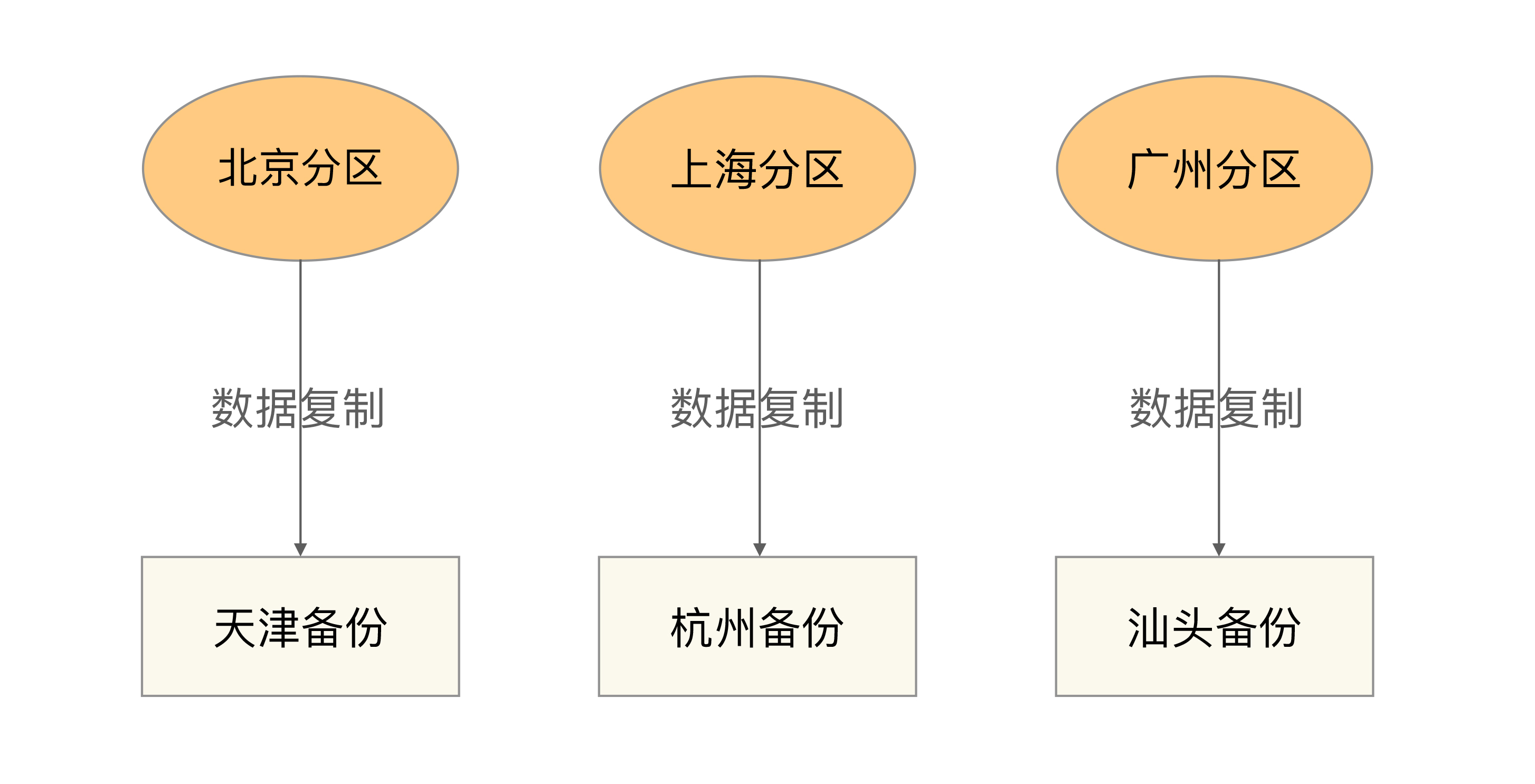
数据分区指将数据按照一定的规则进行分区,不同分区分布在不同的地理位置上,每个分区存储一部分数据,通过这种方式来规避地理级别的故障所造成的巨大影响。
常见的分区复制规则有三种:集中式、互备式和独立式。
集中式备份指存在一个总的备份中心,所有的分区都将数据备份到备份中心。
互备式备份指每个分区备份另外一个分区的数据。
独立式备份指每个分区自己有独立的备份中心。

五、高可用计算架构
主备架构又可以细分为冷备架构和温备架构。
计算高可用架构从形式上和存储高可用架构看上去几乎一样,它们的复杂度不一样。
存储高可用是有状态的,计算高可用一般解决的都是无状态问题,有状态就存在着如何保存状态、同步状态的问题了。
六、高可用业务的保障:异地多活架构
根据地理位置上的距离来划分,异地多活架构可以分为同城异区、跨城异地、跨国异地。
异地多活设计的理念可以总结为一句话:采用多种手段,保证绝大部分用户的核心业务异地多活!
