一致性hash算法
1.哈希算法
哈希(Hash)也称为散列,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,这个输出值就是散列值。
例如:数据库中分表操作,选取某个列的值进行hash运算,然后根据Hash的结果分配到不同的表中
以id为例,我们的数据库表中的数据亮一天预计数据量可以达到300万,长远的估计该表需要设计成分表的形式存储。
我们以订单ID为例,分为10个表路路由算法可以简单地⽤用 id % 10的值来表示数据所属的数据库表编号。
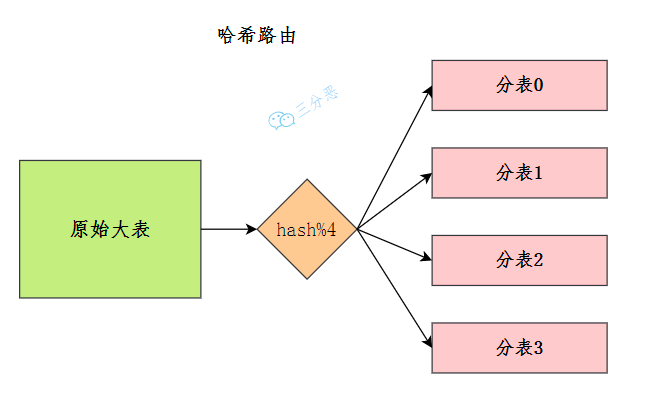
Hash路由设计难点是初始表数量的选取,但是若是需要新增子表,那么hash%Mod也会随之发生变化,因此需要重新分配所有数据,这种影响会存在问题,优点的分布比较均匀分布到表中,缺点是扩充新数据重新排布。
2.一致性哈希算法
一致性哈希算法很好的解决了扩容和缩容的时候,发生过多数据迁移的问题。
一致性哈希是对2^32取模运算,是一个固定的值。
哈希环的范围是0-2^32-1.
一致性hash需要两步运算:
a.对存储结点hash运算,比如以IP地址进行hash
b.对数据进行存储或访问,对数据进行hash
因此存储节点和数据都在同一hash环上。
映射的结果是沿着顺时针的方向找到第一个节点。
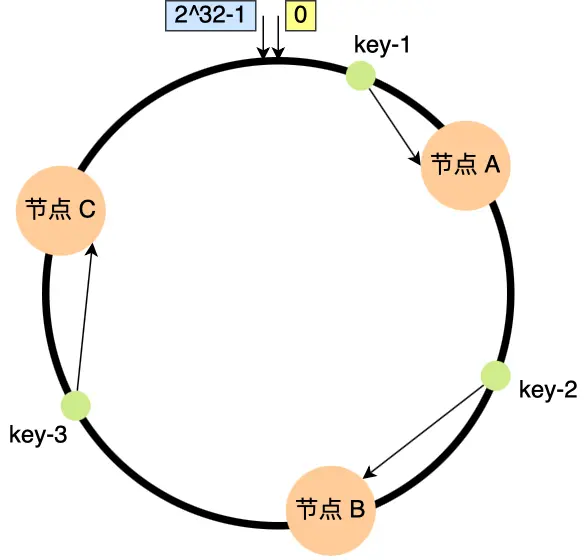
当需要对指定 key 的值进行读写的时候,要通过下面 2 步进行寻址:
- 首先,对 key 进行哈希计算,确定此 key 在环上的位置;
- 然后,从这个位置沿着顺时针方向走,遇到的第一节点就是存储 key 的节点。
在一致哈希算法中,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
但是一致性哈希算法并不保证节点能够在哈希环上分布均匀,这样就会带来一个问题,会有大量的请求集中在一个节点上。
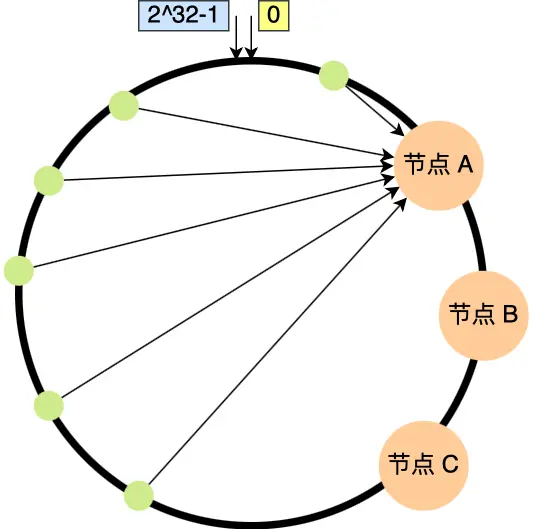
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
引入虚拟节点后,可以会提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
有了虚拟节点后,还可以为硬件配置更好的节点增加权重,比如对权重更高的节点增加更多的虚拟机节点即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号