JavaScript中的Unicode
什么是CodePoint
代码点是Unicode术语,从U+0到U+10FFFF都是代码点。一个代码点对应一个字符。
ES6新增String.fromCodePoint函数以及String#codePointAt函数(charCodeAt函数的修复版),这就意味着,Web平台下的JavaScript从支持UTF-8开始到现在已经支持UTF-16编码。
JS对32位的代码点的支持度如何呢?
String.fromCodePoint.apply(null, [0x4F60, 0x4E, 0x42]) // "你NB"
"你NB".charCodeAt(0).toString(16).toUpperCase() // "4F60"
'\u{2F804}'.codePointAt(0).toString(16).toUpperCase() // "2F804", charCodeAt则会分为两个字符
注意在汉字中“你”字有两个:'\u{2F804}'和'\u4F60'。
代码点查询:http://www.isthisthingon.org/unicode/index.phtml?glyph=2F804
阮一峰的资料更强大:https://www.ruanyifeng.com/blog/2014/12/unicode.html
String#charAt VS String#charCodeAt VS String#codePointAt
String#charAt(index: number): char
在UTF-8编码的字符串中获取第index个简单UTF-16字符。
虽然汉字在UTF-8编码中常占3个字节,但代码点只占2个字节的汉字等字符可以像单字节的ASCII字符一样被正确识别。不支持4字节的UTF-16字符,会被识别为两个“�”,这符合String#length的计算方式,所以刚好可以获取String#length个字符。
'A\u4F60\u{2F804}'.charAt(0)
"A"
'A\u4F60\u{2F804}'.charAt(1)
"你"
'A\u4F60\u{2F804}'.charAt(2)
"�"
'A\u4F60\u{2F804}'.charAt(3)
"�"
'A\u4F60\u{2F804}'.charAt(4)
""
String#charCodeAt(index: number): number
同charAt一样,不过返回类型是number。4字节的UTF-16字符严格按照UTF-16编码被处理为两个特殊区间的16字节数值。
'A\u4F60\u{2F804}'.charCodeAt(0).toString(16)
"41"
'A\u4F60\u{2F804}'.charCodeAt(1).toString(16)
"4f60"
'A\u4F60\u{2F804}'.charCodeAt(2).toString(16)
"d87e" // U+2F804其二 (应该也是小端)
'A\u4F60\u{2F804}'.charCodeAt(3).toString(16)
"dc04" // U+2F804其一
'A\u4F60\u{2F804}'.charCodeAt(4).toString(16)
"NaN"
String#codePointAt(index: number): number
charCodeAt的4字节支持版本。
'A\u4F60\u{2F804}'.codePointAt(0).toString(16)
"41"
'A\u4F60\u{2F804}'.codePointAt(1).toString(16)
"4f60"
'A\u4F60\u{2F804}'.codePointAt(2).toString(16)
"2f804"
'A\u4F60\u{2F804}'.codePointAt(3).toString(16)
"dc04"
'A\u4F60\u{2F804}'.codePointAt(4)
undefined
String.fromCharCode vS String.fromCodePoint
String.fromCharCode(...code: number[]): string
number最大数值为65535,不支持超过2字节的代码点,需要拆分为两个参数,如0x2F804 => 0xD87E+0xDC04。
即UTF-16编码。
String.fromCharCode(0x41, 0x4F60, 0xD87E, 0xDC04, 0x2F804)
"A你你" // 0x2F804发生了溢出,只被识别为一个错误的单字节字符,而0xD87E_0xDC04则正常被识别。
String.fromCharCode(0x41, 0x4F60, 0xD87E, 0xDC04, 0x2F804).length
5
String.fromCodePoint(...code: number[]): string
fromCharCode的增强版本,number范围从0到0x10FFFF,支持全部代码点。
String.fromCodePoint(0x41, 0x4F60, 0xD87E, 0xDC04, 0x2F804)
"A你你你"
String.fromCodePoint(0x41, 0x4F60, 0xD87E, 0xDC04, 0x2F804).length
6
数学公式
非常荣幸的一点:"�"+"�"==="你"(代码点:U+2F804),这是UTF16能转为UTF8的根本。
String.fromCharCode(0xD87E) + String.fromCharCode(0xDC04) === String.fromCharCode(0xD87E, 0xDC04)
true
String.fromCharCode(0xD87E, 0xDC04) === String.fromCodePoint(0x2F804)
true
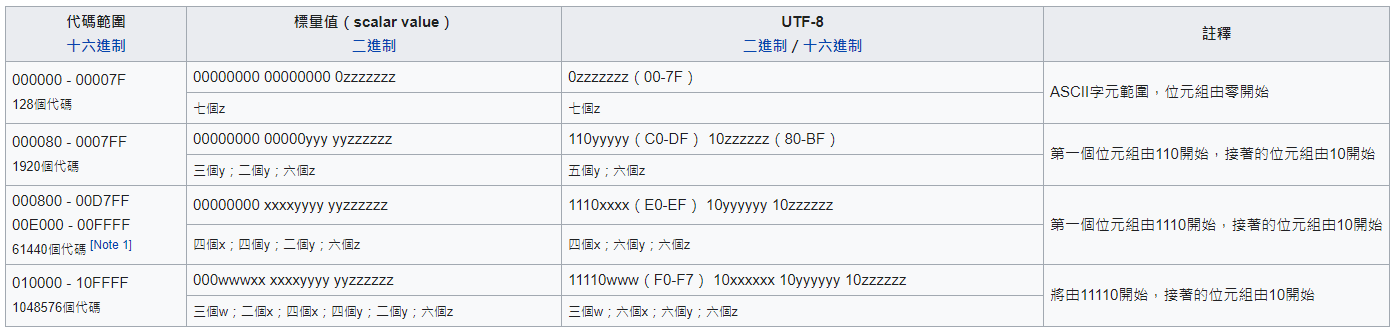
UTF-8
0xxxxxxx
范围U+0000至U+007F,称为基平面,包含ASCII编码中共128个字符。
110xxxxx 10xxxxxx
附加平面,拉丁文等符号。
1110xxxx 10xxxxxx 10xxxxxx
其他基本多文種平面(BMP),大部分汉字的区间。
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
輔助平面。
UTF-16
32768个常用字符全部使用两个字节,其他字符使用四个字节。
对汉字有利、对ASCII不利。
UTF-16 LE与BE之分
LE:小端(little)
BE:大端(big)
Byte Order Mark(BOM)
UTF-16LE的BOM是一个2字节字符:U+FEFF。(小端存储,所以在文件中是FF FE)
UTF-16BE的BOM是一个2字节字符:U+FFFE。
示例:写入UTF16LE文本的同时向文件加入BOM标识。
import * as fs from "fs";
import { UTF8ToUTF16 } from "./web/encode";
let buf: Uint16Array = UTF8ToUTF16('你好\u{2F804}好');
let newBuf = new Uint16Array(buf.length + 1);
for (let i = 0; i < buf.length; i++) {
newBuf[i+1] = buf[i];
}
newBuf[0] = 0xFEFF;
fs.writeFileSync('a.txt', newBuf);
JS中的Unicode
/**
* 获取字符串的二进制表示形式
* @param str
*/
export async function String2BinaryView(str: string): Promise<string[]> {
let blob = new Blob([str]);
let buffer: ArrayBuffer = await blob.arrayBuffer();
let arr = new Uint8Array(buffer); // 按字节读取内存
let view: string[] = Array.prototype.map.call(arr, it => { // ArrayBuffer的map等函数被重写了,只能返回number以修改本身
let bin = it.toString(2) as string;
let zero = 8 - bin.length; // 补零
return `0B${'0'.repeat(zero)}${bin}`;
});
return view;
}
"你NB": [0x4F60, 0x4E, 0x42]
二进制视图: ["0b11100100", "0b10111101", "0b10100000", "0b01001110", "0b01000010"]
汉字"你"代码点为0x4F60: 0100_1111,0110_0000,观察其UTF-8编码:
"xxxx0100", "xx111101", "xx100000" => 0100_1111,0110_0000
汉字"你"的UTF-16编码二进制视图: ["0b01100000", "0b01001111"]
应用
String转UTF-16(LE)编码的Base64字符串
/**
* UTF-8字符串转为以UTF-16(LE)编码存储的Base64编码
*
* MDN解决方案#3 JavaScript的UTF-16 =>二进制字符串=> base64
*
* 存在长度限制(调用栈限制)
* @param sString
*/
export function btoaUTF16(sString: string) {
var aUTF16CodeUnits = new Uint16Array(sString.length); // 注意: js中的字符串length属性严格符合UTF-16,4字节字符占2个长度
Array.prototype.forEach.call(aUTF16CodeUnits, function (el, idx, arr) { arr[idx] = sString.charCodeAt(idx); });
return btoa(String.fromCharCode.apply(null, new Uint8Array(aUTF16CodeUnits.buffer)));
}
export function atobUTF16(sBase64: string) {
var sBinaryString = atob(sBase64), aBinaryView = new Uint8Array(sBinaryString.length);
Array.prototype.forEach.call(aBinaryView, function (el, idx, arr) { arr[idx] = sBinaryString.charCodeAt(idx); });
return String.fromCharCode.apply(null, new Uint16Array(aBinaryView.buffer));
}
优化
/**
* 将UTF-8字符串解码为UTF-16编码,存放到ArrayBuffer中
*
* 用于`btoa()`函数按字节编码二进制字符串
* @param str
*/
export function UTF8ToUTF16(str: string): Uint16Array {
var uint16 = new Uint16Array(str.length); // 并非所有的字符都是2个字节可以搞定,有的字符需要4个字节,此处32位字符的长度是2,正确
// Array.prototype.forEach.call(null, function (el, idx, arr) { arr[idx] = str.charCodeAt(idx); }); // MDN的高级写法
let length = uint16.length; // 'A\u4F60\u{2F804}'.length // 1+1+2=4
for (let i = 0; i < length; i++) {
uint16[i] = str.charCodeAt(i); // 4字节字符需要前后取两次
}
return uint16;
}
/**
* 很明显,有时候JavaScript代码需要快速并轻松处理原始二进制数据。
* 过去,必须通过将原始数据视为字符串并使用该charCodeAt()方法从数据缓冲区读取字节来模拟这种情况。
*
* btoa()不能直接编码UTF-8字符, 可以使用ArrayBuffer转换为BinaryString.
* @param buffer
*/
export function ArrayBuffer2Base64(buffer: ArrayBuffer): string {
var binary = '';
var bytes = new Uint8Array(buffer);
var len = bytes.byteLength;
// 将原始二进制数据按字节转换, 拼接为二进制字符串
for (var i = 0; i < len; i++) {
if (len - i > 70) { // 减少binary拼接次数
binary += String.fromCharCode(bytes[i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i],
bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i],
bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i],
bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i],
bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i],
bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i],
bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i], bytes[++i],
);
} else if (len - i > 5) { // 减少binary拼接次数
binary += String.fromCharCode(bytes[i], bytes[++i], bytes[++i], bytes[++i], bytes[++i]);
} else {
binary += String.fromCharCode(bytes[i]);
}
}
return window.btoa(binary);
}
export function btoaUTF16(sString: string) {
// var aUTF16CodeUnits = new Uint16Array(sString.length);
// Array.prototype.forEach.call(aUTF16CodeUnits, function (el, idx, arr) { arr[idx] = sString.charCodeAt(idx); });
// return btoa(String.fromCharCode.apply(null, new Uint8Array(aUTF16CodeUnits.buffer)));
const uint16: Uint16Array = UTF8ToUTF16(sString);
const buffer: ArrayBuffer = uint16.buffer;
return ArrayBuffer2Base64(buffer);
}
export function atobUTF16(sBase64: string): string {
// var sBinaryString = atob(sBase64), aBinaryView = new Uint8Array(sBinaryString.length);
// Array.prototype.forEach.call(aBinaryView, function (el, idx, arr) { arr[idx] = sBinaryString.charCodeAt(idx); });
// return String.fromCharCode.apply(null, new Uint16Array(aBinaryView.buffer));
/* view: Array(6) 示例:四字节字符'\u{2F804}'的UTF-16+Base64经过atob解码后的binaryStr视图
0: "0B01111110" => 126
1: "0B11000011" => 216(UTF-8)
2: "0B10011000"
3: "0B00000100" => 4
4: "0B11000011" => 220
5: "0B10011100" */
const binaryStr: string = atob(sBase64); // UTF16编码,要转UTF-8
let decodeStr = '';
// btoaUTF16('\u{2F804}') => "ftgE3A==" => atobUTF16('ftgE3A==') => {binaryStr: "~ØÜ", length: 4}
let uint8 = new Uint8Array(binaryStr.length);
for (let i = 0; i < uint8.length; i++) {
uint8[i] = binaryStr.charCodeAt(i);
}
/* uint8: Uint8Array(4)
0: 126 => 01111110
1: 216 => 11011000
2: 4 => 00000100
3: 220 => 11011100 */
let uint16 = new Uint16Array(uint8.buffer);
/* uint16: Uint16Array(2)
0: 55422 => 0B11011000_01111110
1: 56324 => 0B11011100_00000100 */
for (let i = 0; i < uint16.length; i++) {
decodeStr += String.fromCharCode(uint16[i]);
}
return decodeStr;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号