
使用Python管理数据库
这篇文章的主题是如何使用Python语言管理数据库,简化日常运维中频繁的、重复度高的任务,为DBA们腾出更多时间来完成更重要的工作。文章本身只提供一种思路,写的不是很全面,主要起个抛砖引玉的作用。希望能通过此篇文章激发起大家学习python的兴趣。
关于Python
Python作为目前最流行的编程语言之一, 在人工智能、统计分析等领域都有着非常广泛的应用。这两年借助人工智能,流行程度甚至一度超越了java等老牌语言。Python的语法相当直观、简洁、易懂,没有过于复杂的结构,让你能够专注于具体功能的实现,而无需在语法或结构上面下太多功夫。所以Python的学习曲线还是较为平缓的,尤其入门阶段(有编程基础的同学估计花几个小时看一遍语法结构就能使用了;没基础的同学大概花个一周时间也就差不多了)。入门推荐《Python编程:从入门到实践》这本书,让你能够快速上手。
Why Python
说了这么多,好像跟咱DBA没啥关系。其实不然, 上面说了,Python拥有非常强大的库,这其中也包含了能够与数据库进行交互的模块,利用这些模块,DBA们也可以很轻松的使用Python管理数据库。
初识cx_Oracle
cx_Oracle是python下能够跟Oracle数据库进行交互的模块。通过cx_Oracle,我们可以连接到数据库,完成一些日常运维工作。
1.Python 安装
大部分的Linux系统默认就已经安装了Python,可以使用命令查看具体版本号:
dev@dev-VirtualBox:~$ python3 --version Python 3.5.2
2.使用pip下载安装cx_oracle模块
pip 是负责下载、安装Python包的程序。
dev@dev-VirtualBox:~/PycharmProjects/Oracle/venv/bin$ pip3 install cx_Oracle Collecting cx_Oracle Downloading cx_Oracle-6.1-cp35-cp35m-manylinux1_x86_64.whl (527kB) 100% |████████████████████████████████| 532kB 25kB/s Installing collected packages: cx-Oracle Successfully installed cx-Oracle-6.1
3.使用cx_Oracle 模块连接数据库
安装完成后,就可以使用了。
# 导入cx_Oracle import cx_Oracle # 建立数据库连接 db_connection = cx_Oracle.connect('sys', 'oracle', 'test', cx_Oracle.SYSDBA) # 查看数据库版本 print(db_connection.version) #关闭游标 db_cursor.close()
进一步使用cx_Oracle
1.简单查询
import cx_Oracle # 建立连接 db_connection = cx_Oracle.connect('sys', 'oracle', 'test', cx_Oracle.SYSDBA) # 使用游标访问数据 db_cursor = db_connection.cursor() db_cursor.execute(""" select employee_id, first_name, last_name from hr.employees where employee_id > :eid""", eid = 200) # 获取所有数据 print(db_cursor.fetchall()) # 关闭游标 db_cursor.close()
# 执行结果 [(201, 'Michael', 'Hartstein'), (202, 'Pat', 'Fay'), (203, 'Susan', 'Mavris'), (204, 'Hermann', 'Baer'), (205, 'Shelley', 'Higgins'), (206, 'William', 'Gietz')]
fetchall()以列表形式返回所有行(每行的数据存储在元组中),所以也可使用循环遍历访问。例如访问第一行中的值:
for element in db_cursor.fetchall()[0]: print(element)
# 执行结果 201 Michael Hartstein
2.使用函数封装连接
大家可能发现了,每次在对数据库操作前都要先建立连接,都要先输入一大串代码,有点重复。确实是这样,但是如果使用函数对连接方式进行封装,你可能就能体会到使用编程语言的好处了,以后在需要使用的时候直接调用函数就行了。
# 创建连接函数 def conn_cursor(conn_dict): # 使用字典储存连接信息 connection = cx_Oracle.connect(conn_dict['username'], conn_dict['passwd'], conn_dict['tns_name'], mode=conn_dict['mode']) # 返回游标 return connection.cursor()
# 使用hr用户连接并查询dept表 conn_hr = { 'username': 'hr', 'passwd': 'oracle', 'tns_name': 'test', 'mode': 0 } cur_hr = conn_cursor(conn_hr) cur_hr.execute( "select * from employees where rownum < 10" ) # 获取第一行数据 print(cur_hr.fetchone())
# 执行结果 (198, Donald, OConnell, DOCONNEL, 650.507.9833, 21-JUN-07, SH_CLERK, 2600, 124, 50)
3.封装常用sql脚本
数据库中特定语句的格式基本都是相同的,根据上面的例子,我们可以把常用的sql脚本通过形参+字符串的方式组合成语句,封装到函数中,例如:


# 创建用户 def create_user(ora_cursor, user, password, default_tbs, profile='default'): ora_cursor.execute( "create user " + user + " identified by " + password + ' default tablespace ' + default_tbs + " profile " + profile ) print("user " + user + " created succesfully!") ora_cursor.close()
# 修改密码 def alter_user_passwd(ora_cursor, user, password): ora_cursor.execute( "alter user " + user + " identified by " + password ) print("user " + user + "'s password altered successfully!") ora_cursor.close()
# 创建表空间(默认autoextend off) def create_tbs(ora_cursor, tbs_name, data_file, size, extend='autoextend off'): ora_cursor.execute( "create tablespace " + tbs_name + " datafile '" + data_file + "' size " + str(size) + " G " + extend ) print("Tablespace " + tbs_name + " created successfully!") ora_cursor.close()
# 添加数据文件(默认autoextend off) def extend_tbs(ora_cursor, tbs_name, data_file, size, extend='autoextend off'): ora_cursor.execute( "alter tablespace " + tbs_name + " add datafile '" + data_file + "' size " + str(size) + " G " + extend ) print("Tablespace " + tbs_name + " extended " + str(size) + "G successfully!") ora_cursor.close()
# kill 用户会话 def kill_session(ora_cursor, username): ora_cursor.execute( "select spid from v$process a, v$session b where a.addr = b.paddr and b.username = '" + username + "'" ) result = ora_cursor.fetchall() if len(result) != 0: for spid_tpl in result: for spid in spid_tpl: os.system("kill -9 " + str(spid)) print("process have been killed!") else: print("User " + username + " has not connected yet...") ora_cursor.close()
4.包的调用
定义这么多的函数,不可能放到一个文件中,不然后期很难维护。我们可以根据函数的功能,将这些函数选择性的进行分类,放到不同的文件中(如管理用户的函数放到users.py,管理表空间的放到tbs.py等)。这里我先暂时将这些函数都放到ora_func.py文件中,然后在my_workbench.py中进行调用。
ora_func.py:
import cx_Oracle import os # 以下是具体定义的函数 # 创建用户 def create_user(ora_cursor, user, password, default_tbs, profile='default'): ora_cursor.execute( "create user " + user + " identified by " + password + ' default tablespace ' + default_tbs + " profile " + profile ) print("user " + user + " created succesfully!") ora_cursor.close() … …
from ora_func import * # 创建monitor用户(指定test表空间,profile使用默认default) create_user(cur_sys, 'monitor', 'oracle', 'test')
执行my_workbench.py并在数据库中查看实际创建情况:user monitor created succesfully!
SQL> select username, default_tablespace, profile from dba_users where username='MONITOR'; USERNAME DEFAULT_TABLESPACE PROFILE ------------------------------ ------------------------------ ------------------------------ MONITOR TEST DEFAULT
以后只要先在ora_func.py中编写函数,然后在my_workbench.py中添加、编辑需要调用的函数即可。
5.收集会话数
除了将日常脚本固化到函数中外,Python还可以用来收集一些数据库性能数据。比如最简单的,收集一段时间内的数据库会话总数,并绘制成曲线:
import time import cx_Oracle import matplotlib.pyplot as plt import numpy as np import operator def session_count(ora_cursor, dict): ora_cursor.execute( "select count(*) from v$session" ) date = time.strftime('%X', time.localtime()) dict[date] = int(cur_ora.fetchall()[0][0]) # print(cur_ora.fetchall()[0]) cur_ora.close() # 取当前时间 today_str = time.strftime('%Y-%m-%d', time.localtime()) conn_info = { 'username': 'test', 'passwd': 'oracle', 'tns_name': 'test', 'mode': 0 } count_dict = {} while True: # 取当前时间,与之前时间作比较,如果是当天数据,则记录到count_dict中,否则就进行统计 after_str = time.strftime('%Y-%m-%d', time.localtime()) if today_str == after_str: cur_ora = conn_cursor(conn_info) session_count(cur_ora, count_dict) print(count_dict) # 每隔一小时执行一次 time.sleep(3600) else: # 对字典按照时间进行排序,并转换为元组列表 sortedDict = sorted(count_dict.items(), key=operator.itemgetter(0), reverse=False) # 将时间、会话数量分别放到两个列表中 x = [s[0] for s in sortedDict] y = [s[1] for s in sortedDict] # 根据会话数量绘图 plt.plot(range(len(y)), y) # 设置标题和刻度值 plt.title("Total session count") plt.xlabel("Time") plt.ylabel("session count") ax = plt.gca() ax.set_xticks(np.linspace(0, 24, 24)) ax.set_xticklabels(x) plt.xticks(rotation=30, size=8) plt.show()

这是使用Python的pyplot绘制的图,如果想生成Excel类型的图表,也可以使用xlsxwriter模块实现。
6.AWR报告分析
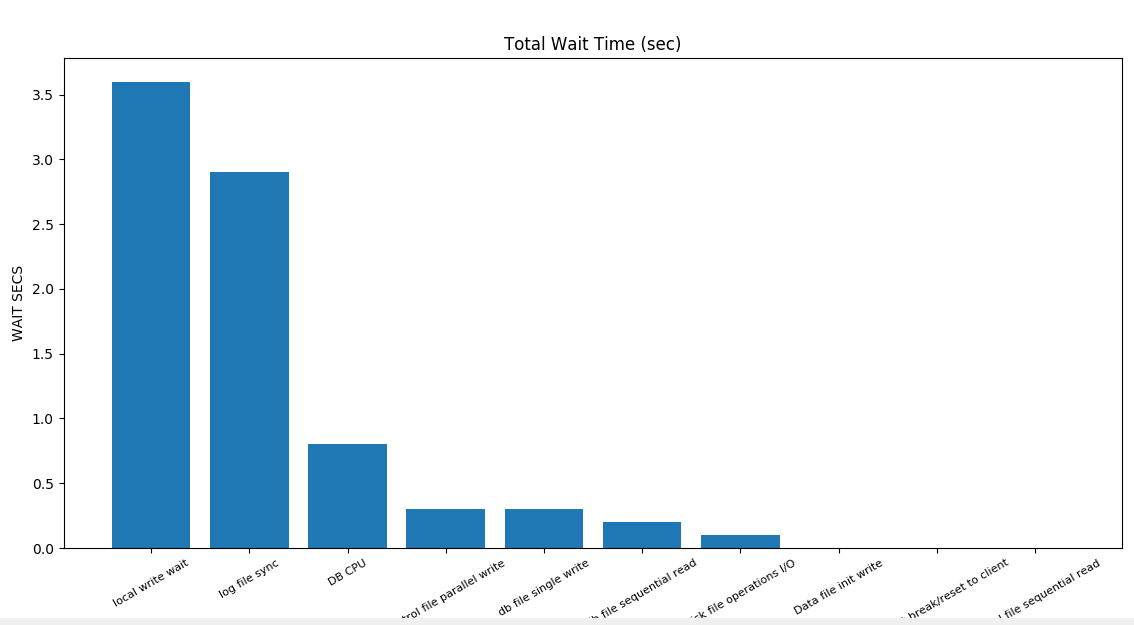
我们经常使用的AWR报告实际上是一个HTML文件,可以使用python的爬虫技术爬取我们关心的数据。下面以一个AWR报告为例,分析其中top events的"Total Wait Time (sec)"列的数据, 并生成图表展示。
from bs4 import BeautifulSoup import matplotlib.pyplot as plt def get_top_events(awr_html): with open(awr_html) as fileobj: bsobj = BeautifulSoup(fileobj, "html.parser") # 获取目标table的<tr> tab_tr = bsobj.find('table', {'summary': "This table displays top 10 wait events by total wait time"}).findAll('tr') # 获取列名 tab_col = [i.get_text() for i in tab_tr[0]] # 获取每行的值 list_row = [] for tr in tab_tr[1:]: td = tr.findAll('td') row = [item.get_text() for item in td] list_row.append(row) # 将Event名称与各项指标值放到字典中 result_dict = {} n = 0 while n < len(list_row): result_dict[list_row[n][0]] = list_row[n][1:] n += 1 return result_dict html = '/PycharmProjects/Oracle/awrrpt_1_12_14.html' result = get_top_events(html) # 生成柱状图并设置标签 x = [x for x in result.keys()] y = [float(result[a][1]) for a in x] plt.bar(range(len(y)), y, tick_label=x) plt.title("Total Wait Time (sec)") plt.xticks(rotation=30, size=8) plt.xlabel("EVENTS") plt.ylabel("WAIT SECS") plt.show()
对AWR报告的生成脚本awrrpt.sql进行分析,可以发现它只是生成了一些变量,并传递给其他脚本继续执行(主要有awrrpti.sql, awrinput.sql等)。生成AWR报告的核心语句就在awrrpti.sql中:
set termout on; spool &report_name; -- call the table function to generate the report select output from table(dbms_workload_repository.&fn_name( :dbid, :inst_num, :bid, :eid, :rpt_options )); spool off;
可以根据实际需要,整理出无界面交互的AWR脚本,定期生成AWR报告,并使用Python分析并保存数据,供日后做性能优化时使用。
关于人工智能
之前传得很火的关于OtterTune即将淘汰DBA的事情,感觉有点夸张了,毕竟现在的人工智能还不能完全胜任DBA的全部工作,还处在为人所用的阶段。简单的说,OtterTune实际上是综合了机器学习中的监督学习和无监督学习,选择一些对性能影响较为关键的参数,并导入在其他数据库收集好的session数据(可以理解为经验数据),对数据库进行调优。机器学习的优势在于能够基于海量数据,对某种现象/行为进行预测(监督学习),或者将数据划分为多个类别(无监督学习)等等。我觉得与其担忧被替代,不如利用这种优势,将自己多年的经验与人工智能相结合。当人工智能正式在数据库领域发展落地时,也能有所建树。
最后
作为一名IT从业人员,多学习几门技术我觉得不仅可以在方案上有多种选择,也可以拓宽我们的视野,让我们在这个更新换代的速度越来越快的行业里待得更久。而且现在越来越多跨专业、跨领域的技术在发展,搞不好哪天又会像人工智能、区块链一样火爆起来。保持一颗年轻、充满好奇的心,可以让我们具备较高的职场竞争力,被机器替代的概率更小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号