深度学习 - 反向传播算法
理解反向传播
要理解反向传播,先来看看正向传播。下面是一个神经网络的一般结构图:
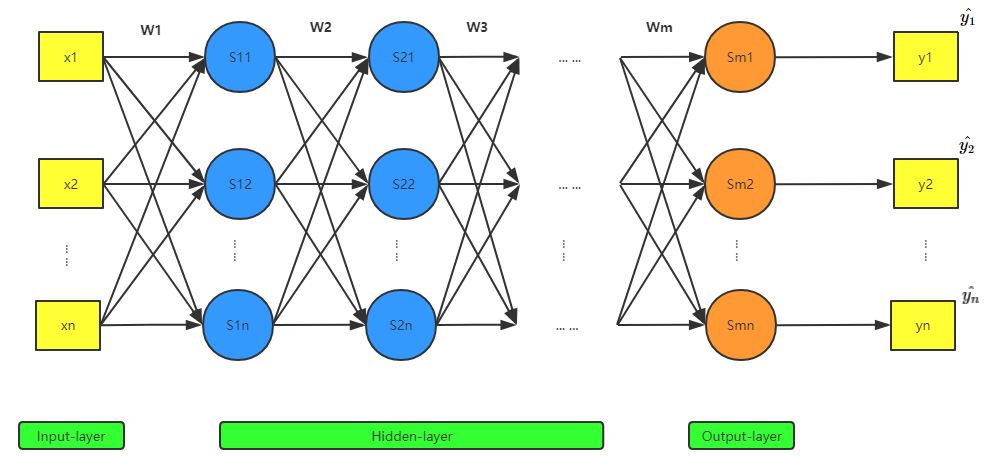
其中,\(x\) 表示输入样本,\(\bm{w}\) 表示未知参数(图中未标出偏置 \(b\)), \(S\) 表示激活函数,\(y\) 表示预测值,\(\hat{y}\) 表示真实值。
显然,通过从样本 \(x\) 的输入,以及一连串激活函数的运算,最终可以得到预测值 \(y\),从而可以计算损失函数的大小。如果误差不达标(或者未达到迭代次数),我们就需要使用梯度下降的方法,先初始化出一组 \(w\),再沿梯度相反的方向对 \(w\) 进行不断迭代,求出最优的一组参数。对任意一个参数 \(w_j\) 来说,都可以通过梯度下降法进行求解:
\(\begin{equation*}
w_j = w_j - \frac{\partial{L(\bm{w})}}{\partial{w_j}}
\end{equation*}\)
这个式子的关键是求梯度 \(\frac{\partial{L(\bm{w})}}{\partial{w_j}}\)。梯度在这里的含义是对 \(w_j\) 做一个微小的改变 \(\Delta{w_j}\),会导致损失函数产生 \(\Delta{L(\bm{w})}\) 的变化。观察整个网络传输的过程可以发现,\(\Delta{w_j}\) 并不直接作用于最终的输出 \(\bm{y}\),而是先改变当前层神经元的输入 \(z_j\),再改变当前层神经元的输出 \(a_j\),而 \(a_j\) 又会作为下一层各神经元的输入。所以这种影响是间接的、传导性的:

一个参数就会引起后续所有神经元输出的变化,这是一种链式传导效应。所以如果要求梯度 \(\frac{\partial{L(\bm{w})}}{\partial{w_j}}\) ,就需要考虑后续这些被影响到的神经元,而要计算这些值的变化,则需要完成正向计算,然后才能计算出梯度,从而对参数进行更新。因为每一层的信息都依赖后面各层已经计算出的信息,看上去就像从反方向再传递一遍:
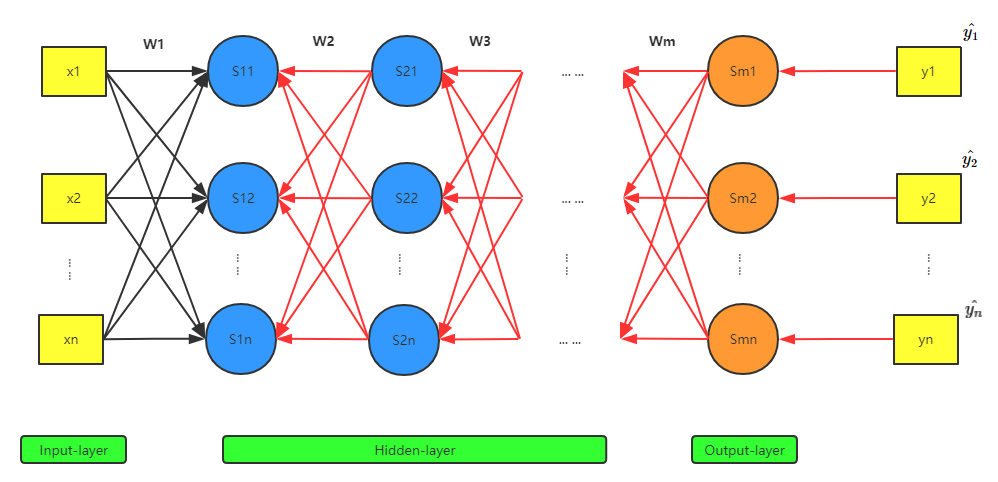
下面是以一个参数为例,表示参数的更新过程:
误差的定义
上面说了,一个任意的参数 \(w_j\) 是通过依次改变神经元输入 \(z_j\),神经元输出 \(a_j\),从而最终影响到 \(\bm{y}\) 的。所以如果以神经元为单位,就可以说是由于神经元输入 \(z_j\) 的改变导致了 \(\bm{y}\) 的变化,最终导致损失函数 \(L(\bm{w})\) 的变化。所以一个神经元输入的改变对整个网络的损失函数产生的误差就可以表示为: \(\delta_j = \frac{\partial{L(\bm{w})}}{\partial{z_j}}\) 。
那么如何表示上图中的链式传导效应呢?巧了,导数中的链式法则正好可以描述这一现象:

所以有:
\(\frac{\partial{L(\bm{w})}}{\partial{w_j}} = \frac{\partial{z_j}}{\partial{w_j}} \frac{\partial{L(\bm{w})}}{\partial{z_j}} = \frac{\partial{z_j}}{\partial{w_j}}\delta_j \\\)
\(\delta_j = \frac{\partial{L(\bm{w})}}{\partial{z_j}} = \frac{\partial{a_j}}{\partial{z_j}} \frac{\partial{L(\bm{w})}}{\partial{a_j}}\)
误差的传导过程
1.打通传导链路
目前这个链式传导好像卡在了 \(w_j\) 参数所在的这一层,无法继续向下一层传导,因为我们没有显式的定义神经网络的层数。所以在这里我们需要新增关于层数的参数 \(l\):
\(w^{l}_{jk}\) 表示第 \(l-1\) 层的第 \(k\) 个神经元到第 \(l\) 层的第 \(j\) 个神经元的参数 \(w\);
\(b^{l}_j\) 表示第 \(l\) 层的第 \(j\) 个神经元的参数 \(b\);
\(z^l_j\) 表示第 \(l\) 层的第 \(j\) 个神经元的输入;
\(a^l_j\) 表示第 \(l\) 层的第 \(j\) 个神经元的输出;
\(\delta^l_j\) 表示第 \(l\) 层的第 \(j\) 个神经元的误差。

有了 \(l\),我们便可以使用 \(l\) 层的输出 \(a^l_j\),定义 \(l+1\) 层的输入 \(z^{l+1}_k\) 了(假设 \(l\) 层 有 \(j\) 个神经元,\(l+1\) 层有 \(k\) 个神经元):
\(z^{l+1}_k = \sum_{j}w^{l+1}_{kj}{a^l_j} + b^{l+1}_k\)
由此,我们也可以让第 \(l\) 层第 \(j\) 个神经元产生的误差 \(\delta^l_j\) 向 \(l+1\) 层的所有神经元(共 \(k\) 个)进行传播:
\(\delta^l_j = \frac{\partial{L(\bm{w})}}{\partial{z^l_j}} = \sum_{k}\frac{\partial{z^{l+1}_k}}{\partial{z^l_j}} \frac{\partial{L(\bm{w})}}{\partial{z^{l+1}_k}}\)
注意到,\(\frac{\partial{L(\bm{w})}}{\partial{z^{l+1}_k}} = \delta^{l+1}_k\),\(\frac{\partial{z^{l+1}_k}}{\partial{z^l_j}} = \frac{\partial{\sum_{J}w^{l+1}_{kj}{a^l_j} + b^{l+1}_k}}{\partial{z^l_j}}\)
因为 \(a^l_j = \sigma(z^l_j)\),其中 \(\sigma(z^l_j)\) 是激活函数,所以 \(\frac{\partial{z^{l+1}_k}}{\partial{z^l_j}} = w^{l+1}_{kj}{\sigma'(z^l_j)}\) (仅当 \(J = j\) 时有微分)
所以 \(\delta^l_j = \sum_{k}w^{l+1}_{kj}{\sigma'(z^l_j)}\delta^{l+1}_k\)
写成向量形式:
\(\bm{\delta}^l = (\bm{w}^{l+1})^T \bm{\delta}^{l+1} \circ {\sigma'(\bm{z}^l)} \quad \quad \quad (1)\)
其中 \(\bm{w}^{l+1}\) 为 \(k \times j\) 阶向量,\(\bm{\delta}^{l+1}\) 为 \(k \times 1\) 阶向量,\(\bm{w}^{l+1}\) 转置后与 \(\bm{\delta}^{l+1}\) 相乘,得到 $ j \times 1$ 的向量,而 \({\sigma'(\bm{z}^l)}\) 的维度也是 $ j \times 1$,所以需要使用 Hadamard 乘积进行计算,即两个维度相同的向量对应位置的数相乘。
这个式子还有一个含义,就是可以通过 \(l+1\) 层的误差,求出 \(l\) 层的误差。所以这个式子是整个反向传播能够实现的关键。如果知道了最后一层(即输出层)的误差,就可以使用这个式子求出前面所有层的误差。那么我们就来看看最后一层的误差如何求出。
2.输出层的误差
由于输出层的结果就是预测值,所以有:
\(\delta^l_j = \frac{\partial{L}}{\partial{z^l_j}} = \frac{\partial{L}}{\partial{a^l_j}}\frac{\partial{a^l_j}}{\partial{z^l_j}}\)
其中,\(\frac{\partial{L}}{\partial{a^l_j}} = \nabla_{a_j}L ;\quad \frac{\partial{a^l_j}}{\partial{z^l_j}} = \frac{\partial{\sigma(z^l_j)}}{\partial{z^l_j}} = \sigma'(z^l_j)\)
写成向量形式:
\(\bm{\delta}^l = \nabla_{\bm{a}^l}L \circ \sigma'(\bm{z}^l) \quad \quad \quad \quad \quad \quad (2)\)
\(\nabla_{a^l}L\) 与损失函数的形式相关,如果使用均方误差作为损失函数,则:
\(\nabla_{a}L = \frac{\partial{\frac{1}{2}(a^l - y)^2}}{\partial{a^l}} = (a^l - y)\)
3.通过误差求梯度
我们再回到最初的式子:
\(\frac{\partial{L(\bm{w})}}{\partial{w^l_{jk}}} = \frac{\partial{z^l_j}}{\partial{w^l_{jk}}} \frac{\partial{L(\bm{w})}}{\partial{z^l_j}} = \frac{\partial{z^l_j}}{\partial{w^l_{jk}}}\delta^l_j \\\)
其中 \(\delta^l_j\) 可通过反向传播求出,而 \(\frac{\partial{z^l_j}}{\partial{w^l_{jk}}} = \frac{\partial{w^l_{jk}a^{l-1}_k + b^l_j}}{\partial{w^l_{jk}}} = a^{l-1}_k\)
所以:
\(\frac{\partial{L(\bm{w})}}{\partial{w^l_{jk}}} = a^{l-1}_k \delta^l_j \quad \quad \quad \quad \quad \quad \quad (3)\)
同理可得:
\(\frac{\partial{L(\bm{w})}}{\partial{b^l_{j}}} = \delta^l_j \quad \quad \quad \quad \quad \quad \quad \quad \quad (4)\)
至此,我们就求出了参数 \(w\) 和 \(b\) 的梯度,从而可以通过对整个网络的不断迭代,优化初始模型。
具体计算过程
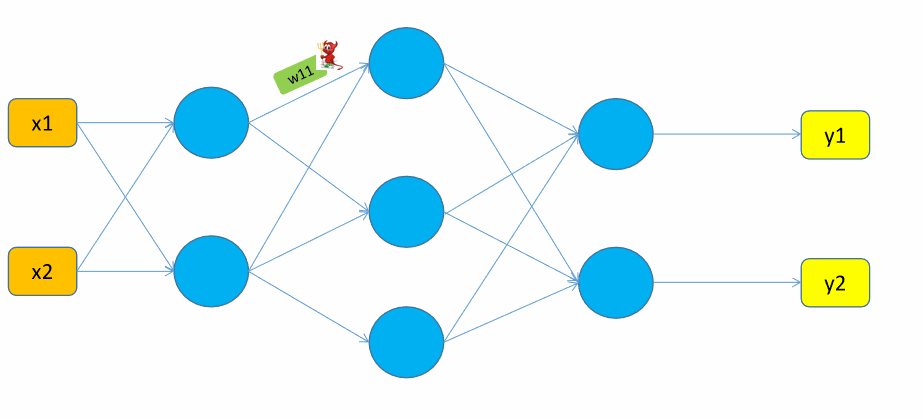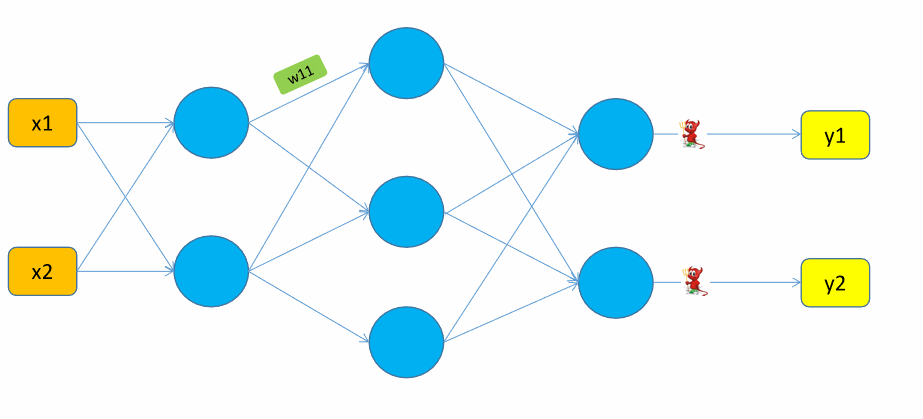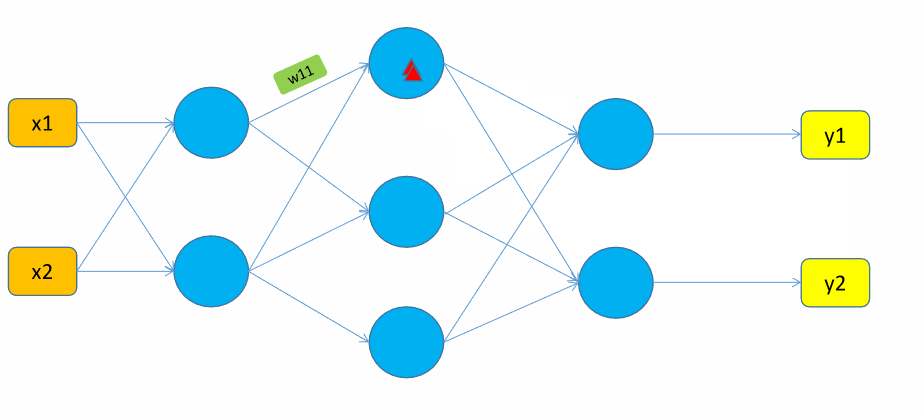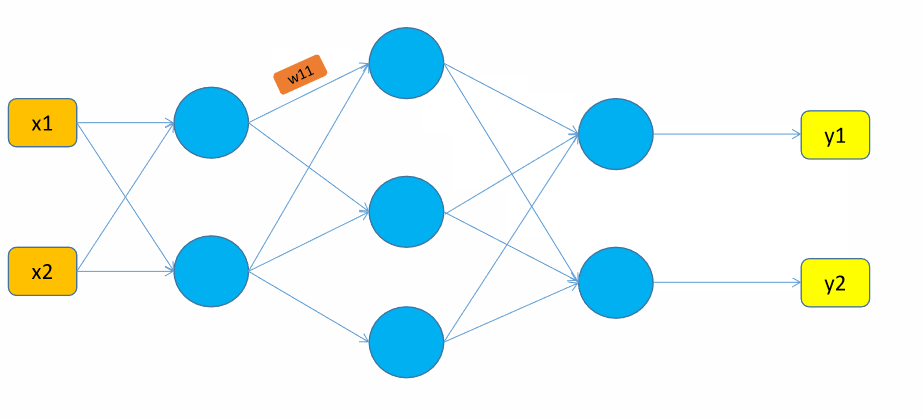
下面以一个只有两个神经元、一个隐藏层的简单神经网络为例,阐述一下整个过程。

其中,\(z_{11}\) 为激活函数 \(S_{11}\) 的输入,\(a_{11}\) 为 \(S_{11}\) 的输出,则有:
\(\begin{equation*}
z_{11} = w_{11}x_1 + w_{12}x_2 + b_{11}
\end{equation*}\)
\(\begin{equation*}
a_{11} = \frac{1}{1 + e^{-z_{11}}}
\end{equation*} \quad \quad \quad \quad \quad \quad \quad (\mbox{使用 } Sigmoid \mbox{ 函数作为激活函数})\)
\(z_{12}, z_{21}, z_{22}, a_{12}, a_{21}, a_{22}\)可同理得到。
1.正向计算
我们先观察一下参数\(w_{11}\)在整个正向计算过程中的轨迹:
(1)\(w_{11}\)组成了神经元 \(S_{11}\) 的输入 \(z_{11}\);
(2)\(S_{11}\) 神经元经过计算后输出 \(a_{11}\);
(3)\(a_{11}\) 又作为输入,组成了 \(z_{21}, z_{22}\),并参与到神经元 \(S_{21}, S_{22}\) 的计算中,得到 \(a_{21}, a_{21}\),即预测值 \(y_{1}、y_{2}\)(\(S_{2n}\) 为输出层)。
所以可以这么理解,\(w_{11}\)只与这些值有关,而与网络中的其他值无关。由此可以得到如下关系:
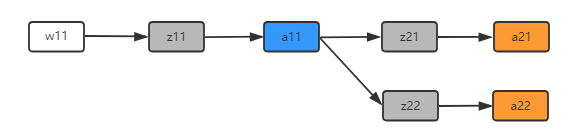
根据这个关系,我们可以便可以得到 \(\frac{\partial{L(\bm{\theta})}}{\partial{w_{11}}}\):
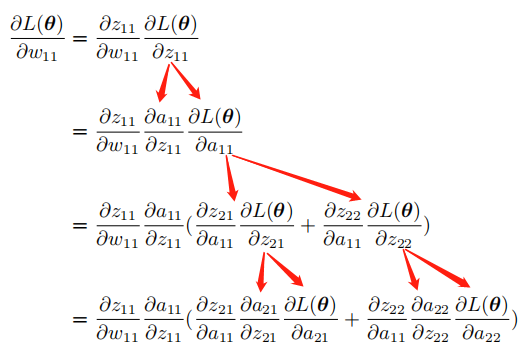
我们再对公式中的各项依次求解:
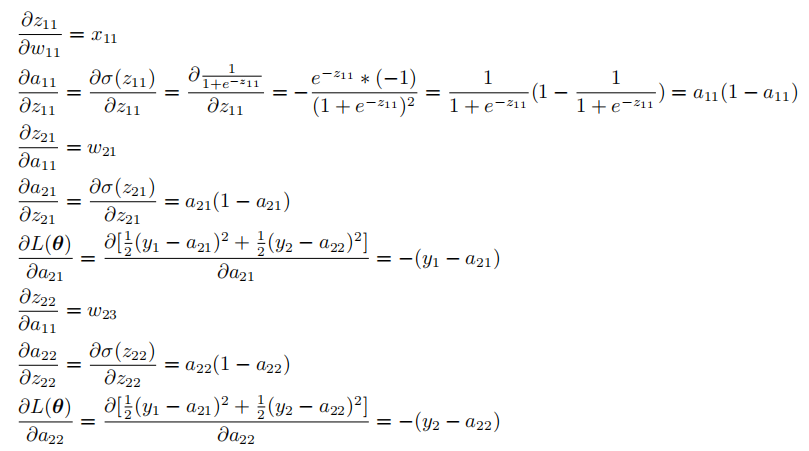
只要我们随机初始化一组\(w\),就能得到这些项的值。
2.反向更新参数
有了上面那些通过正向计算得到的值,其实只要从下到上这么反向计算,就能得到我们要求的偏导数:

至此,我们就能够对\(w_{11}\)进行更新了:
\(w_{11} = w_{11} - \eta\frac{\partial{L(\bm{\theta})}}{\partial{w_{11}}}\)
下面再带入具体值,手算一下更新的过程。
手算神经网络
1.正向计算
(1)初始化\(\bm{w}\)
为了能够更好地了解这一过程,我们可以直接带入真实值进行计算,从而可以避免掺杂过多的符号。下面是一个初始化好的神经网络:

(2)计算输入与输出值
\(\begin{equation*} z_{11} = 0.15\times0.05 + 0.2\times0.1 +0.35 = 0.3775 \end{equation*}\)
\(\begin{equation*} a_{11} = \frac{1}{1 + e^{-0.3775}} = 0.5933 \end{equation*}\)
\(\begin{equation*} z_{12} = 0.25\times0.05 + 0.3\times0.1 +0.35= 0.3925 \end{equation*}\)
\(\begin{equation*} a_{12} = \frac{1}{1 + e^{0.3925}} = 0.5969 \end{equation*}\)
\(\begin{equation*} z_{21} = 0.4\times0.5933 + 0.45\times0.5969 +0.6 = 1.1059 \end{equation*}\)
\(\begin{equation*} z_{22} = 0.55\times0.5933 + 0.5\times0.5969 +0.6 = 1.2248 \end{equation*}\)
\(\begin{equation*} a_{21} = \frac{1}{1 + e^{-1.1059}} = 0.7514 \end{equation*}\)
\(\begin{equation*} a_{22} = \frac{1}{1 + e^{-1.2248}} = 0.7729 \end{equation*}\)
由此我们得到了预测值 \((0.7514, 0.7729)\) ,这与真实值 \((0.01, 0.99)\) 相差的非常多,所以需要进行反向更新。
2.反向更新参数
根据公式进行计算:
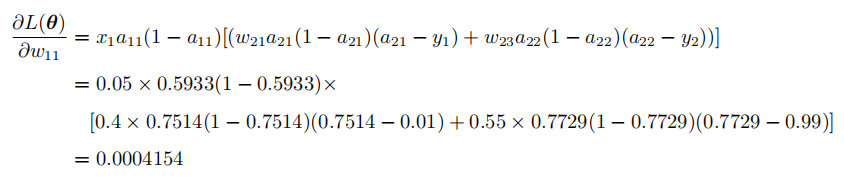
通过这样的计算,便可以成功更新神经网络中的每个参数了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号