
简单了解 TiDB 架构
一、前言
大家如果看过我之前发过的文章就知道,我写过很多篇关于 MySQL 的文章,从我的 Github 汇总仓库 中可以看出来:
可能还不是很全,算是对 MySQL 有一个浅显但较为全面的理解。之前跟朋友聊天也会聊到,基于现有的微服务架构,绝大多数的性能瓶颈都不在服务,因为我们的服务是可以横向扩展的。
在很多的 case 下,这个瓶颈就是「数据库」。例如,我们为了减轻 MySQL 的负担,会引入消息队列来对流量进行削峰;再例如会引入 Redis 来缓存一些不太常变的数据,来减少对 MySQL 的请求。
另一方面,如果业务往 MySQL 中灌入了海量的数据,不做优化的话,会影响 MySQL 的性能。而对于这种情况,就需要进行分库分表,落地起来还是较为麻烦的。
聊着聊着,就聊到了分布式数据库。其对数据的存储方式就类似于 Redis Cluster 这种,不管你给我灌多少的数据,理论上我都能够吞下去。这样一来也不用担心后期数据量大了需要进行分库分表。
刚好,之前闲逛的时候看到了 PingCAP 的 TiDB,正好就来聊一聊。
二、正文
由于是简单了解,所以更多的侧重点在存储
1.TiDB Server
还是从一个黑盒子讲起,在没有了解之前,我们对 TiDB 的认识就是,我们往里面丢数据,TiDB 负责存储数据。并且由于是分布式的,所以理论上只要存储资源够,多大的数据都能够存下。
我们知道,TiDB 支持 MySQL,或者说兼容大多数 MySQL 的语法。那我们就还是拿一个 Insert 语句来当作切入点,探索数据在 TiDB 中到底是如何存储的。
首先要执行语句,必然要先建立连接。
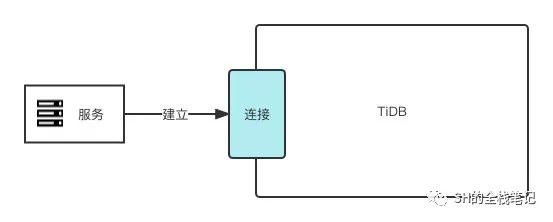
在 MySQL 中,负责处理客户端连接的是 MySQL Server,在 TiDB 中也有同样的角色 —— TiDB Server,虽角色类似,但两者有着很多的不同。
TiDB Server 对外暴露 MySQL 协议,负责 SQL 的解析、优化,并最终生成分布式执行计划,MySQL 的 Server 层也会涉及到 SQL 的解析、优化,但与 MySQL 最大的不同在于,TiDB Server 是无状态的。
而 MySQL Server 由于和底层存储引擎的耦合部署在同一个节点,并且在内存中缓存了页的数据,是有状态的。
这里其实可以简单的把两者理解为,TiDB 是无状态的可横向扩展的服务。而 MySQL 则是在内存中缓存了业务数据、无法横向扩展的单体服务。
而由于 TiDB Server 的无状态特性,在生产中可以启动多个实例,并通过负载均衡的策略来对外提供统一服务。
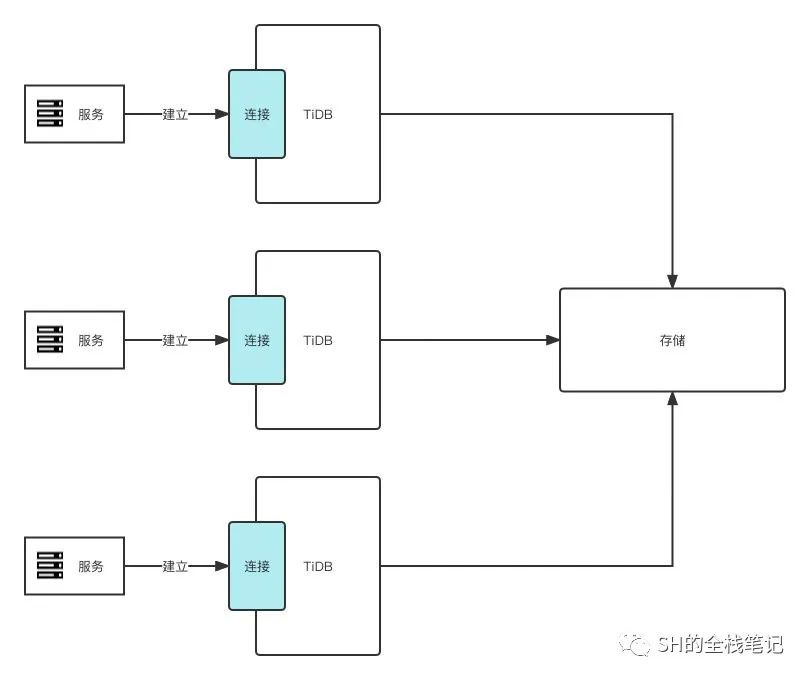
实际情况下,TiDB 的存储节点是单独、分布式部署的,这里只是为了方便理解 TiDB Server 的横向扩展特性,不用纠结,后面会聊到存储
总结下来,TiDB Server 只干一件事:负责解析 SQL,将实际的数据操作转发给存储节点。
2.TiKV
我们知道,对于 MySQL,其存储引擎(绝大多数情况)是 InnoDB,其存储采用的数据结构是 B+ 树,最终以 .ibd 文件的形式存储在磁盘上。那 TiDB 呢?
TiDB 的存储是由 TiKV 来负责的,这是一个分布式、支持事务的 KV 存储引擎。说到底,它就是个 KV 存储引擎。
用大白话说,这就是个巨大的、有序的 Map。但说到 KV 存储,很多人可能会联想到 Redis,数据大多数时候是放在内存,就算是 Redis,也会有像 RDB 和 AOF 这样的持久化方式。那 TiKV 作为一个分布式的数据库,也不例外。它采用 RocksDB 引擎来实现持久化,具体的数据落地由其全权负责。
RocksDB 是由 Facebook 开源的、用 C++ 实现的单机 KV 存储引擎。
3.索引数据
直接拿官网的例子给大家看看,话说 TiDB 中有这样的一张表:
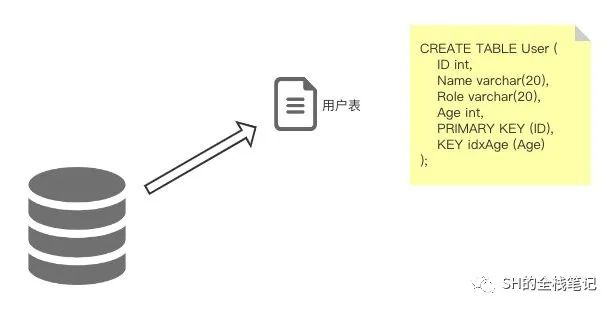
然后表里有三行数据:

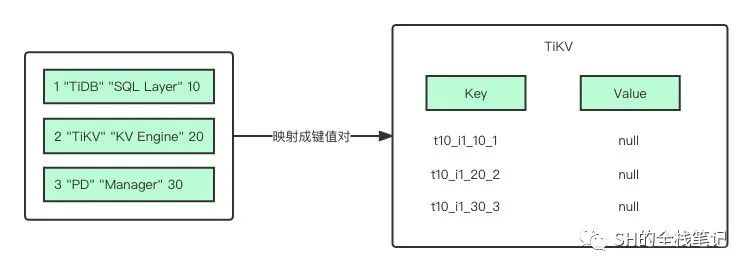
这三行数据,每一行都会被映射成为一个键值对:

其中,Key 中的 t10 代表 ID 为 10 的表,r1 代表 RowID 为 1 的行,由于我们建表时制定了主键,所以 RowID 就为主键的值。Value 就是该行除了主键之外的其他字段的值,上图表示的就是主键索引。
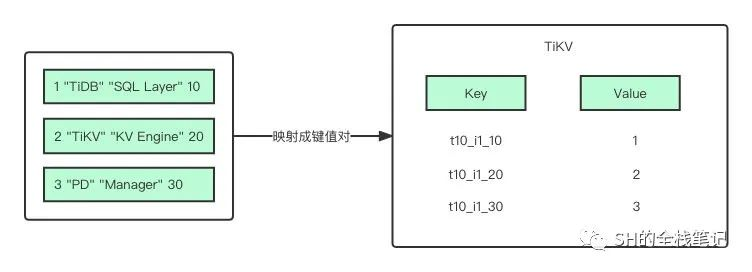
那如果是非聚簇索引(二级索引)呢?就比如索引 idxAge,建表语句里对 Age 这一列建立了二级索引:
i1 代表 ID 为 1 的索引,即当前这个二级索引,10、20、30 则是索引列 Age 的值,最后的 1、2、3 则是对应的行的主键 ID。从建索引的语句部分可以看出来,idxAge 是个普通的二级索引,不是唯一索引。所以索引中允许存在多个 Age 为 30 的列。
但如果我们是唯一索引呢?
只拿表 ID、索引 ID 和索引值来组成 Key,这样一来如果再次插入 Age 为 30 的数据,TiKV 就会发现该 Key 已经存在了,就能做到唯一键检测。
4.存储细节
知道了列数据是如何映射成 Map 的,我们就可以继续了解存储相关的细节了。

从图中,我们可以看出个问题:如果某个 TiKV 节点挂了,那么该节点上的所有数据是不是都没了?
当然不是的,TiDB 可以是一款金融级高可用的分布式关系型数据库,怎么可能会让这种事发生。
TiKV 在存储数据时,会将同一份数据想办法存储到多个 TiKV 节点上,并且使用 Raft 协议来保证同一份数据在多个 TiKV 节点上的数据一致性。
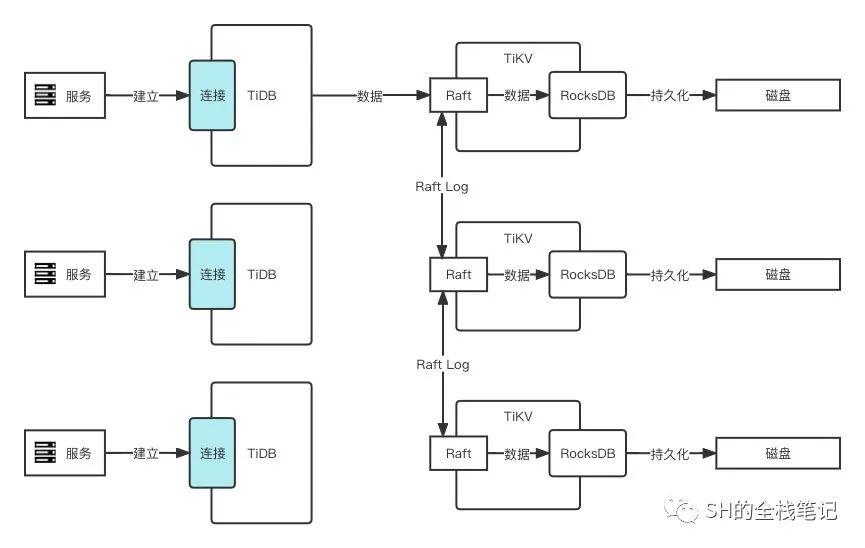
上图为了方便理解,进行了简化。实际上一个 TiKV 中有存在 2 个 RocksDB。一个用于存储 Raft Log,通常叫 RaftDB,而另一个用于存储用户数据,通常叫 KVDB。
简单来说,就是会选择其中一份数据作为 Leader 对外提供读、写服务,其余的作为 Follower 仅仅只同步 Leader 的数据。当 Leader 挂掉之后,可以自动的进行故障转移,从 Follower 中重新选举新的 Leader 出来。
看到这,是不是觉得跟 Kafka 有那么点神似了。Kafka 中一个 Topic 是逻辑概念,实际上会分成多个 Partition,分散到多个 Broker 上,并且会选举一个 Leader Partition 对外提供服务,当 Leader Partition 出现故障时,会从 Follower Partiiton 中重新再选举一个 Leader 出来。
那么,Kafka 中选举、提供服务的单位是 Partition,TiDB 中的是什么呢?
5.Region
答案是 Region。刚刚讲过,TiKV 可以理解为一个巨大的 Map,而 Map 中某一段连续的 Key 就是一个 Region。不同的 Region 会保存在不同的 TiKV 上。
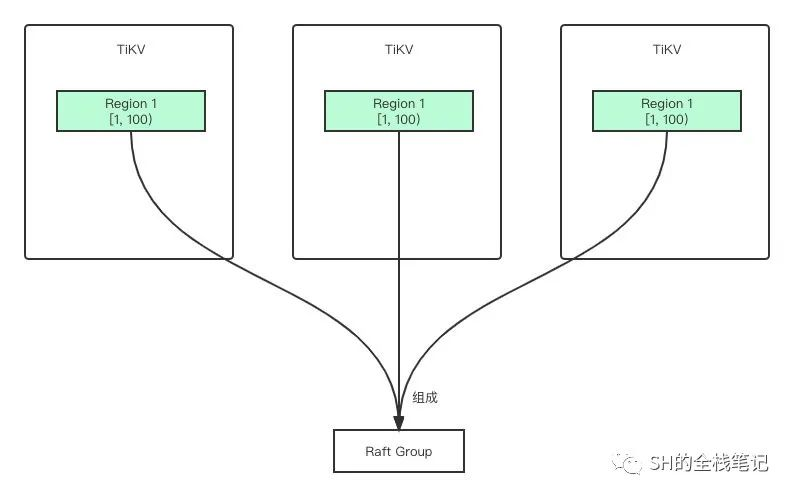
一个 Region 有多个副本,每个副本也叫 Replica,多个 Replica 组成了一个 Raft Group。按照上面介绍的逻辑,某个 Replica 会被选作 Leader,其余 Replica 作为 Follower。
并且,在数据写入时,TiDB 会尽量保证 Region 不会超过一定的大小,目前这个值是 96M。当然,还是可能会超过这个大小限制。
每个 Region 都可以用 [startKey, endKey) 这样一个左闭右开的区间来表示。
但不可能让它无限增长是吧?所以 TiDB 做了一个最大值的限制,当 Region 的大小超过144M(默认) 后,TiKV 会将其分裂成两个或更多个 Region,以保证数据在各个 Region 中的均匀分布;同理,当某个 Region 由于短时间删除了大量的数据之后,会变的比其他 Region 小很多,TiKV 会将比较小的两个相邻的 Region 合并。
大致的存储机制、高可用机制上面已经简单介绍了。
但其实上面还遗留一了比较大的问题。大家可以结合上面的图思考,一条查询语句过来,TiDB Server 解析了之后,它是怎么知道自己要找的数据在哪个 Region 里?这个 Region 又在哪个 TiKV 上?
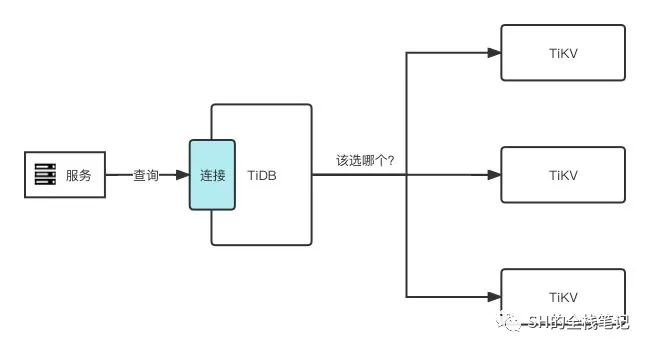
难道要遍历所有的 TiKV 节点?用脚想想都不可能这么完。刚刚讲到多副本,除了要知道提供读、写服务的 Leader Replica 所在的 TiKV,还需要知道其余的 Follower Replica 都分别在哪个实例等等。
6.PD
这就需要引入 PD 了,有了 PD 「存储相关的细节」那幅图就会变成这样:

PD 是个啥?其全名叫 Placement Driver,用于管理整个集群的元数据,你可以把它当成是整个集群的控制节点也行。PD 集群本身也支持高可用,至少由 3 个节点组成。举个对等的例子应该就好理解了,你可以把 PD 大概理解成 Zookeeper,或者 RocketMQ 里的 NameServer。Zookeeper 不必多说,NameServer 是负责管理整个 RocketMQ 集群的元数据的组件。
担心大家杠,所以特意把大概两个字加粗了。因为 PD 不仅仅负责元数据管理,还担任根据数据分布状态进行合理调度的工作。
这个根据数据状态进行调度,具体是指啥呢?
7.调度
举个例子,假设每个 Raft Group 需要始终保持 3 个副本,那么当某个 Raft Group 的 Replica 由于网络、机器实例等原因不可用了,Replica 数量下降到了 1 个,此时 PD 检测到了就会进行调度,选择适当的机器补充 Replica;Replica 补充完后,掉线的又恢复了就会导致 Raft Group 数量多于预期,此时 PD 会合理的删除掉多余的副本。
一句话概括上面描述的特性:PD 会让任何时候集群内的 Raft Group 副本数量保持预期值。
这个可以参考 Kubernetes 里的 Replica Set 概念,我理解是很类似的。
或者,当 TiDB 集群进行存储扩容,向存储集群新增 TiKV 节点时,PD 会将其他 TiKV 节点上的 Region 迁移到新增的节点上来。
或者,Leader Replica 挂了,PD 会从 Raft Group 的 Replica 中选举出一个新的 Leader。
再比如,热点 Region 的情况,并不是所有的 Region 都会被频繁的访问到,PD 就需要对这些热点 Region 进行负载均衡的调度。
总结一下 PD 的调度行为会发现,就 3 个操作:
- 增加一个 Replica
- 删除一个 Replica
- 将 Leader 角色在一个 Raft Group 的不同副本之间迁移
了解完了调度的操作,我们再整体的理解一下调度的需求,这点 TiDB 的官网有很好的总结,我把它们整理成脑图供大家参考:
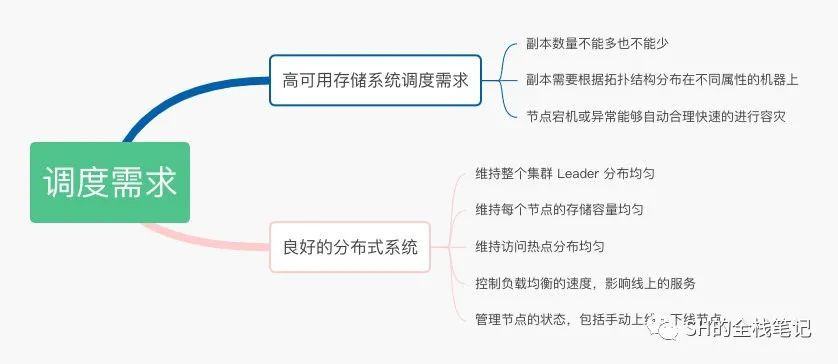
大多数点都还好,只是可能会对「控制负载均衡的速度」有点问题。因为 TiDB 集群在进行负载均衡时,会进行 Region 的迁移,可以理解为跟 Redis 的 Rehash 比较耗时是类似的问题,可能会影响线上的服务。
8.心跳
PD 而要做到调度这些决策,必然需要掌控整个集群的相关数据,比如现在有多少个 TiKV?多少个 Raft Group?每个 Raft Group 的 Leader 在哪里等等,这些其实都是通过心跳机制来收集的。
在 NameServer 中,所有的 RocketMQ Broker 都会将自己注册到 NameServer 中,并且定时发送心跳,Broker 中保存的相关数据也会随心跳一起发送到 NameServer 中,以此来更新集群的元数据。
PD 和 TiKV 也是类似的操作,TiKV 中有两个组件会和 PD 交互,分别是:
- Raft Group 的 Leader Replica
- TiKV 节点本身
PD 通过心跳来收集数据,更新维护整个集群的元数据,并且在心跳返回时,将对应的「调度指令」返回。
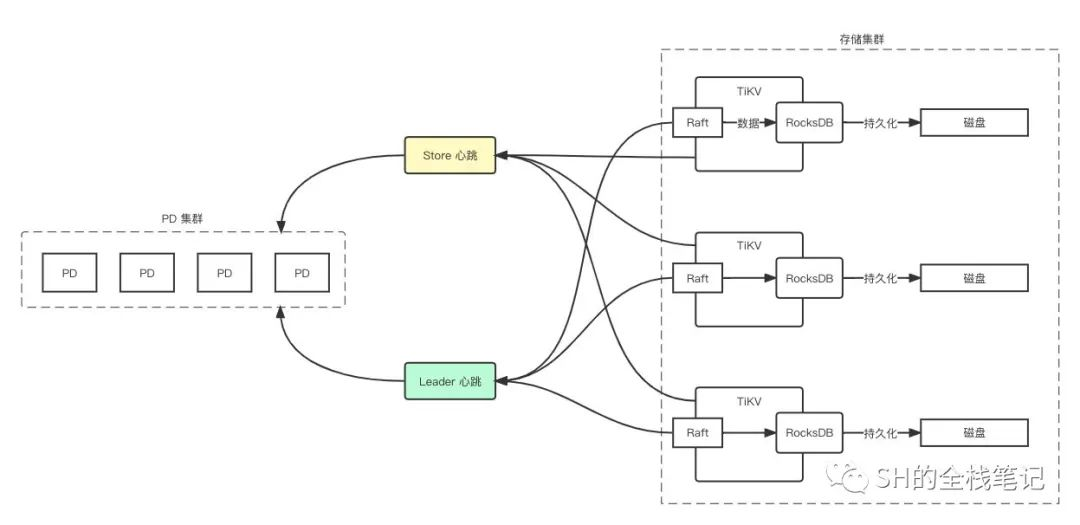
值得注意的是,上图中每个 TiKV 中 Raft 只连了一条线,实际上一个 TiKV 节点上可能会有多个 Raft Group 的 Leader
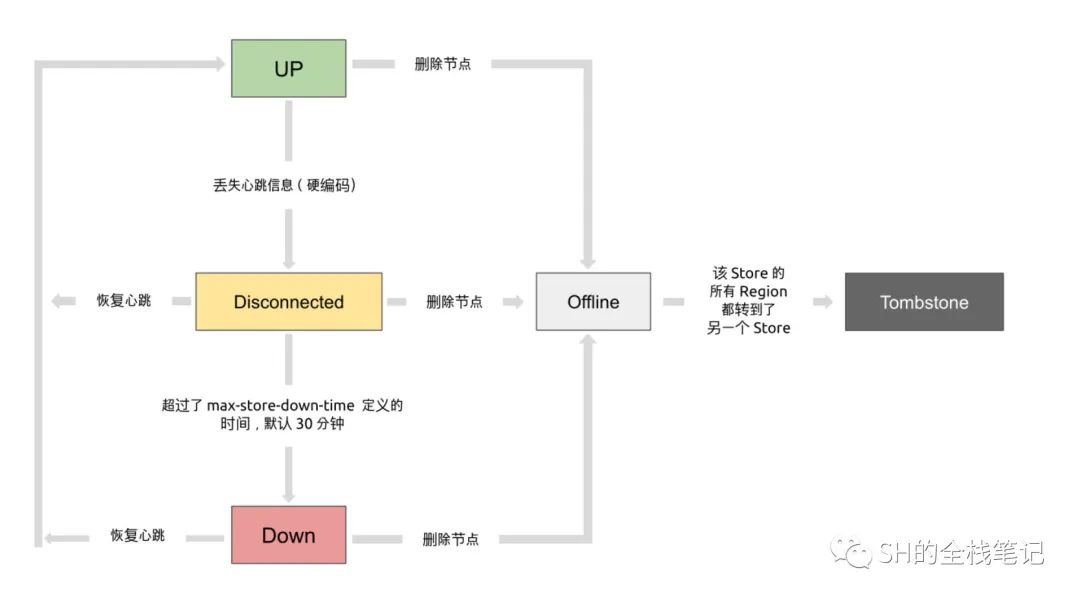
Store(即 TiKV 节点本身)心跳会带上当前节点存储的相关数据,例如磁盘的使用状况、Region 的数量等等。通过上报的数据,PD 会维护、更新 TiKV 的状态,PD 用 5 种状态来标识 TiKV 的存储,分别是:
- Up:这个懂的都懂,不懂的解释了也不懂(手动 doge)
- Disconnect:超过 20 秒没有心跳,就会变成该状态
- Down:Disconnect 了
max-store-down-time的值之后,就会变成 Down,默认 30 分钟。此时 PD 会在其他 Up 的 TiKV 上补足 Down 掉的节点上的 Region - Offline:通过 PD Control 进行手动下线操作,该 Store 会变为 Offline 状态。PD 会将该节点上所有的 Region 搬迁到其他 Store 上去。当所有的 Region 迁移完成后,就会变成 Tomstone 状态
- Tombstone:表示已经凉透了,可以安全的清理掉了。
其官网的图已经画的很好了,就不再重新画了,以下状态机来源于 TiDB 官网:
Raft Leader 则更多的是上报当前某个 Region 的状态,比如当前 Leader 的位置、Followers Region 的数量、掉线 Follower 的个数、读写速度等,这样 TiDB Server 层在解析的时候才知道对应的 Leader Region 的位置。
欢迎微信搜索关注【SH的全栈笔记】,如果你觉得这篇文章对你有帮助,还麻烦点个赞,关个注,分个享,留个言。

