

Redis Sentinel-深入浅出原理和实战
本篇博客会简单的介绍Redis的Sentinel相关的原理,同时也会在最后的文章给出硬核的实战教程,让你在了解原理之后,能够实际上手的体验整个过程。
之前的文章聊到了Redis的主从复制,聊到了其相关的原理和缺点,具体的建议可以看看我之前写的文章Redis的主从复制。
总的来说,为了满足Redis在真正复杂的生产环境的高可用,仅仅是用主从复制是明显不够的。例如,当master节点宕机了之后,进行主从切换的时候,我们需要人工的去做failover。
同时在流量方面,主从架构只能通过增加slave节点来扩展读请求,写能力由于受到master单节点的资源限制是无法进行扩展的。
这也是为什么我们需要引入Sentinel。
Sentinel
功能概览
Sentinel其大致的功能如下图。

Sentinel是Redis高可用的解决方案之一,本身也是分布式的架构,包含了多个Sentinel节点和多个Redis节点。而每个Sentinel节点会对Redis节点和其余的Sentinel节点进行监控。
当其发现某个节点不可达时,如果是master节点就会与其余的Sentinel节点协商。当大多数的Sentinel节点都认为master不可达时,就会选出一个Sentinel节点对master执行故障转移,并通知Redis的调用方相关的变更。
相对于主从下的手动故障转移,Sentinel的故障转移是全自动的,无需人工介入。
Sentinel自身高可用
666,那我怎么知道满足它自身的高可用需要部署多少个Sentinel节点?
因为Sentinel本身也是分布式的,所以也需要部署多实例来保证自身集群的高可用,但是这个数量是有个最低的要求,最低需要3个。
我去,你说3个就3个?我今天偏偏就只部署2个
你别杠...等我说了为什么就必须要3个...
因为哨兵执行故障转移需要大部分的哨兵都同意才行,如果只有两个哨兵实例,正常运作还好,就像这样。
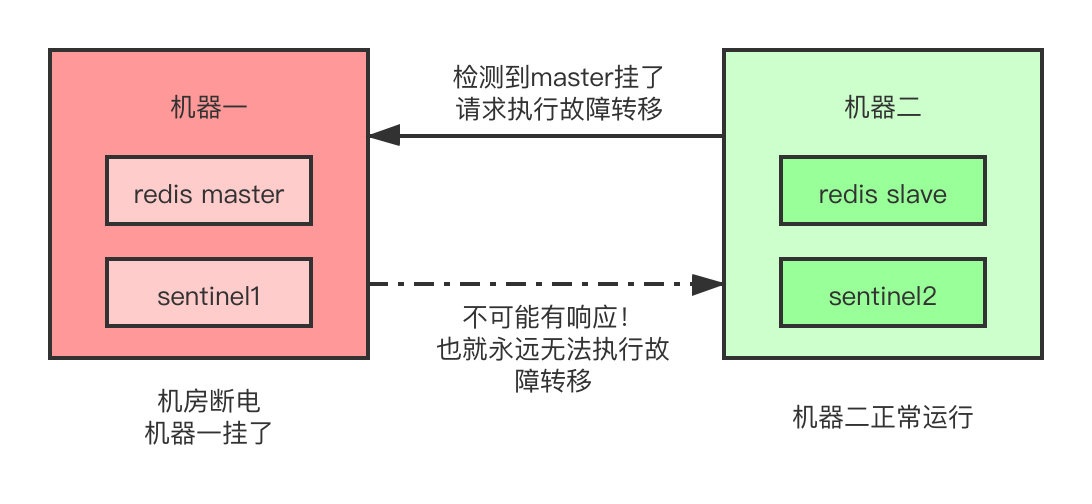
如果哨兵所在的那台机器由于机房断电啊,光纤被挖啊等极端情况整个挂掉了,那么另一台哨兵即使发现了master故障之后想要执行故障转移,但是它无法得到任何其余哨兵节点的同意,此时也永远无法执行故障转移,那Sentinel岂不是成了一个摆设?
所以我们需要至少3个节点,来保证Sentinel集群自身的高可用。当然,这三个Sentinel节点肯定都推荐部署到不同的机器上,如果所有的Sentinel节点都部署到了同一台机器上,那当这台机器挂了,整个Sentinel也就不复存在了。

quorum&majority
大部分?大哥这可是要上生产环境,大部分这个数量未免也太敷衍了,咱就不能专业一点?
前面提到的大部分哨兵同意涉及到两个参数,一个叫quorum,如果Sentinel集群有quorum个哨兵认为master宕机了,就客观的认为master宕机了。另一个叫majority...
等等等等,不是已经有了一个叫什么quorum的吗?为什么还需要这个majority?
你能不能等我把话说完...
quorum刚刚讲过了,其作用是判断master是否处于宕机的状态,仅仅是一个判断作用。而我们在实际的生产中,不是说只判断master宕机就完了, 我们不还得执行故障转移,让集群正常工作吗?
同理,当哨兵集群开始进行故障转移时,如果有majority个哨兵同意进行故障转移,才能够最终选出一个哨兵节点,执行故障转移操作。
主观宕机&客观宕机
你刚刚是不是提到了客观宕机?笑死,难不成还有主观宕机这一说?

Sentinel中认为一个节点挂了有两种类型:
- Subjective Down,简称sdown,主观的认为master宕机
- Objective Down,简称odown,客观的认为master宕机
当一个Sentinel节点与其监控的Redis节点A进行通信时,发现连接不上,此时这个哨兵节点就会主观的认为这个Redis数据A节点sdown了。为什么是主观?我们得先知道什么叫主观
未经分析推算,下结论、决策和行为反应,暂时不能与其他不同看法的对象仔细商讨,称为主观。
简单来说,因为有可能只是当前的Sentinel节点和这个A节点的网络通信有问题,其余的Sentinel节点仍然可以和A正常的通信。
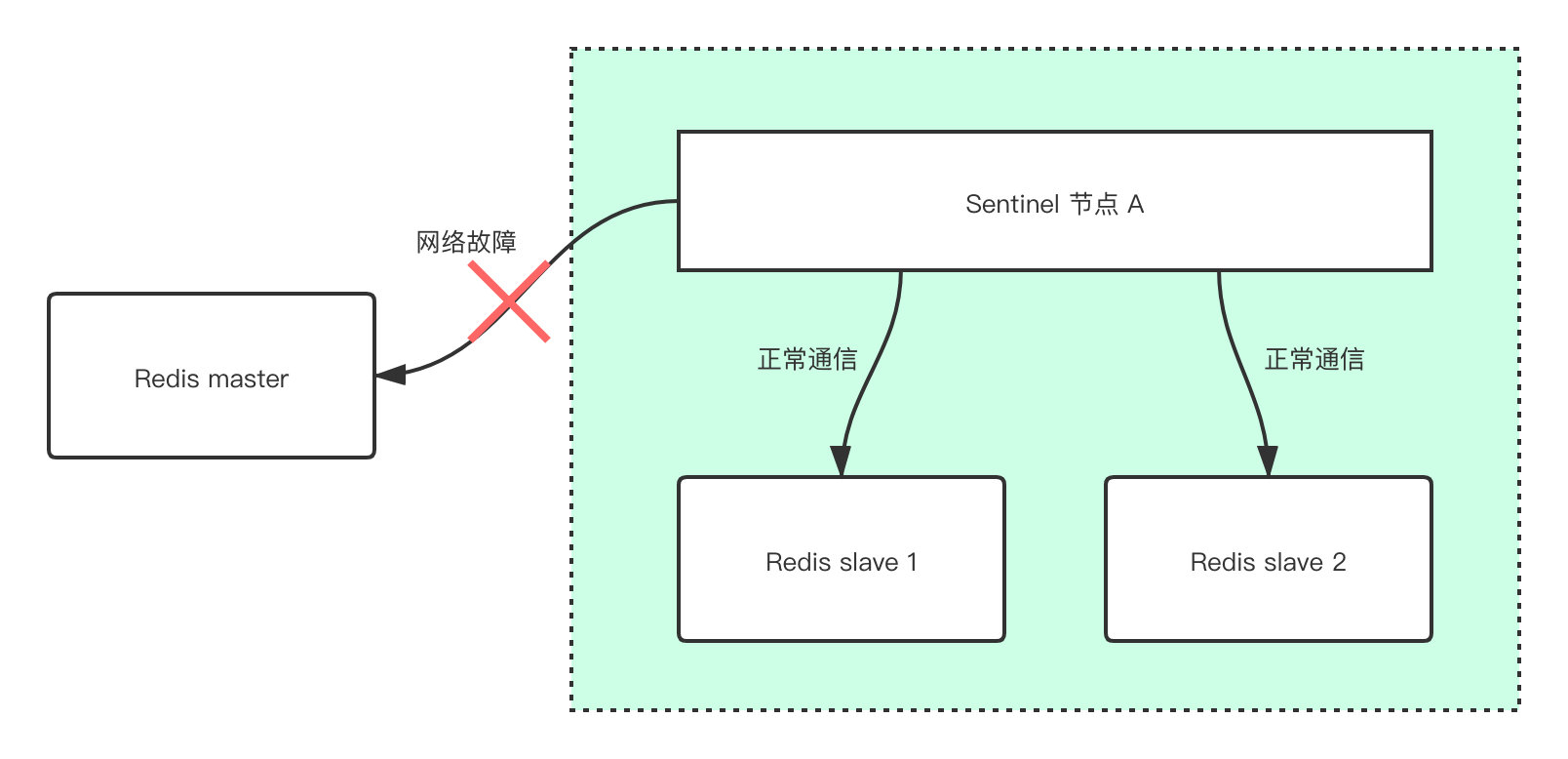
这也是为什么我们需要引入odown,当大于等于了quorum个Sentinel节点认为某个节点宕机了,我们就客观的认为这个节点宕机了。
当Sentinel集群客观的认为master宕机,就会从所有的Sentinel节点中,选出一个Sentinel节点,来最终执行master的故障转移。
那这个故障转移具体要执行些什么操作呢?我们通过一个图来看一下。

通知调用的客户端master发生了变化
通知其余的原slave节点,去复制Sentinel选举出来的新的master节点
如果此时原来的master又重新恢复了,Sentinel也会让其去复制新的master节点。成为一个新的slave节点。
硬核教程
硬核教程旨在用最快速的方法,让你在本地体验Redis主从架构和Sentinel集群的搭建,并体验整个故障转移的过程。
前置要求
- 安装了docker
- 安装了docker-compose
准备compose文件
首先需要准备一个目录,然后分别建立两个子目录。如下。
$ tree .
.
├── redis
│ └── docker-compose.yml
└── sentinel
├── docker-compose.yml
├── sentinel1.conf
├── sentinel2.conf
└── sentinel3.conf
2 directories, 5 files
搭建Redis主从服务器
redis目录下的docker-compose.yml内容如下。
version: '3'
services:
master:
image: redis
container_name: redis-master
ports:
- 6380:6379
slave1:
image: redis
container_name: redis-slave-1
ports:
- 6381:6379
command: redis-server --slaveof redis-master 6379
slave2:
image: redis
container_name: redis-slave-2
ports:
- 6382:6379
command: redis-server --slaveof redis-master 6379
以上的命令,简单解释一下slaveof
就是让两个slave节点去复制container_name为redis-master的节点,这样就组成了一个简单的3个节点的主从架构
然后用命令行进入当前目录,直接敲命令docker-compose up即可,剩下的事情交给docker-compose去做就好,它会把我们所需要的节点全部启动起来。
此时我们还需要拿到刚刚我们启动的master节点的IP,简要步骤如下:
-
通过
docker ps找到对应的master节点的containerID$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9f682c199e9b redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6381->6379/tcp redis-slave-1 2572ab587558 redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6382->6379/tcp redis-slave-2 f70a9d9809bc redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6380->6379/tcp redis-master也就是
f70a9d9809bc。 -
通过
docker inspect f70a9d9809bc,拿到对应容器的IP,在NetworkSettings -> Networks -> IPAddress字段。
然后把这个值给记录下来,此处我的值为172.28.0.3。
搭建Sentinel集群
sentinel目录下的docker-compose.yml内容如下。
version: '3'
services:
sentinel1:
image: redis
container_name: redis-sentinel-1
ports:
- 26379:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/usr/local/etc/redis/sentinel.conf
sentinel2:
image: redis
container_name: redis-sentinel-2
ports:
- 26380:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/usr/local/etc/redis/sentinel.conf
sentinel3:
image: redis
container_name: redis-sentinel-3
ports:
- 26381:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/usr/local/etc/redis/sentinel.conf
networks:
default:
external:
name: redis_default
同样在这里解释一下命令
redis-sentinel 命令让 redis 以 sentinel 的模式启动,本质上就是一个运行在特殊模式的 redis 服务器。
和 redis-server 的区别在于,他们分别载入了不同的命令表,sentinel 中无法执行各种redis中特有的 set get操作。
建立三份一模一样的文件,分别命名为sentinel1.conf、sentinel2.conf和sentinel3.conf。其内容如下:
port 26379
dir "/tmp"
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 172.28.0.3 6379 2
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
可以看到,我们对于sentinel的配置文件中,sentinel monitor mymaster 172.28.0.3 6379 2表示让它去监听名为mymaster的master节点,注意此处的IP一定要是你自己master节点的IP,然后最后面的2就是我们之前提到的quorum。
然后命令行进入名为sentinel的目录下,敲docker-compose up即可。至此,Sentinel集群便启动了起来。
手动模拟master挂掉
然后我们需要手动模拟master挂掉,来验证我们搭建的Sentinel集群是否可以正常的执行故障转移。
命令行进入名为redis的目录下,敲入如下命令。
docker-compose pause master
此时就会将master容器给暂停运行,让我们等待10秒之后,就可以看到sentinel这边输出了如下的日志。
redis-sentinel-2 | 1:X 07 Dec 2020 01:58:05.459 # +sdown master mymaster 172.28.0.3 6379
......
......
......
redis-sentinel-1 | 1:X 07 Dec 2020 01:58:06.932 # +switch-master mymaster 172.28.0.3 6379 172.28.0.2 6379
得得得,你干什么就甩一堆日志文件上来?凑字数?你这样鬼能看懂?
的确,光从日志文件一行一行的看,就算是我自己过两周再来看,也是一脸懵逼。日志文件完整了描述了整个Sentinel集群从开始执行故障转移到最终执行完成的所有细节,但是在这里直接放出来不方便大家的理解。
所以为了让大家能够更加直观的了解这个过程,我简单的把过程抽象了成了一张图,大家看图结合日志,应该能够更容易理解。

里面关键的步骤步骤的相关解释我也一并放入了图片中。
最终的结果就是,master已经从我们最开始的172.28.0.3切换到了172.28.0.2,后者则是原来的slave节点之一。此时我们也可以连接到172.28.0.2这个容器里去,通过命令来看一下其现在的情况。
role:master
connected_slaves:1
slave0:ip=172.28.0.4,port=6379,state=online,offset=18952,lag=0
master_replid:f0bf5d1c843ec3ab005c5ac2b864f7ffdc6a8217
master_replid2:72c43e1f9c05d4b08bea6bf9b2549997587e261c
master_repl_offset:18952
second_repl_offset:16351
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:18952
可以看到,现在的172.28.0.2这个节点的角色已经变成了master,与其相连接的slave节点只有1个,因为现在的原master还没有启动起来,总共存活的只有2个实例。
原master重启启动
接下来我们模拟原master重新启动,来看一下会发什么什么。
还是通过命令行进入到名为redis的本地目录,通过docker-compose unpause master来模拟原master故障恢复之后的上线。同样我们连接到原master的机器上去。
$ docker exec -it f70a9d9809bc1e924a5be0135888067ad3eb16552f9eaf82495e4c956b456cd9 /bin/sh; exit
# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:172.28.0.2
master_port:6379
master_link_status:up
......
master断线重连之后,角色也变成了新的master(也就是172.28.0.2这个节点)的一个slave。
然后我们也可以通过再看一下新master节点的replication情况作证。
# Replication
role:master
connected_slaves:2
slave0:ip=172.28.0.4,port=6379,state=online,offset=179800,lag=0
slave1:ip=172.28.0.3,port=6379,state=online,offset=179800,lag=1
......
原master短线重连之后,其connected_slaves变成了2,且原master172.28.0.3被清晰的标注为了slave1,同样与我们开篇和图中所讲的原理相符合。
好了,以上就是本篇博客的全部内容
欢迎微信关注「SH的全栈笔记」,查看更多相关的文章
往期文章

