第三次作业
请按要求上机实践如下linux基本命令。
cd命令:切换目录
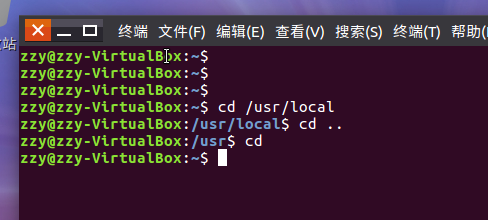
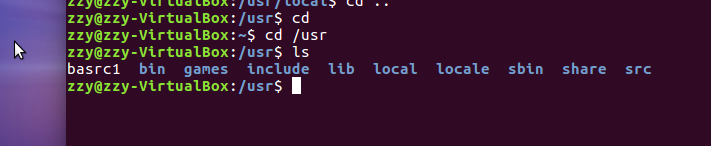
ls命令:查看文件与目录
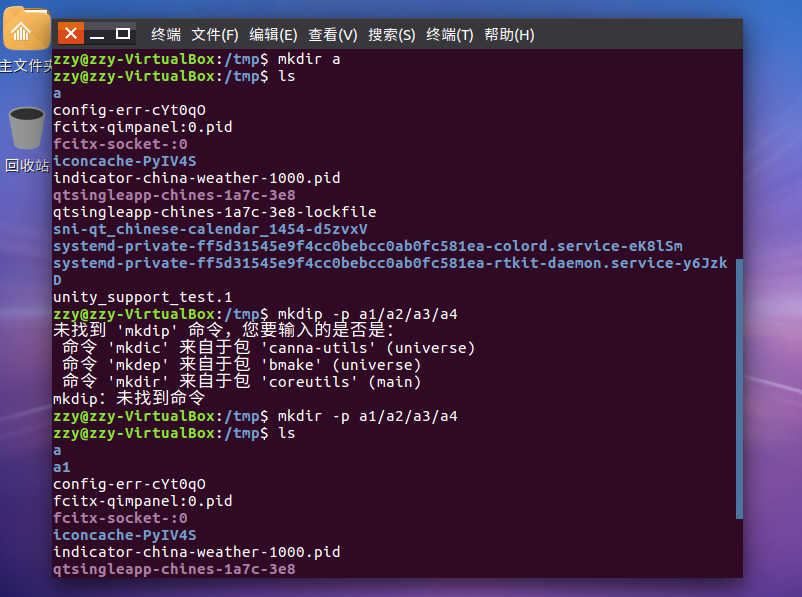
mkdir命令:新建新目录
rmdir命令:删除空的目录

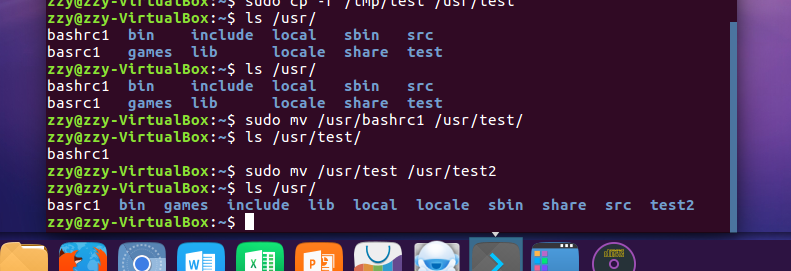
cp命令:复制文件或目录

mv命令:移动文件与目录,或更名
rm命令:移除文件或目录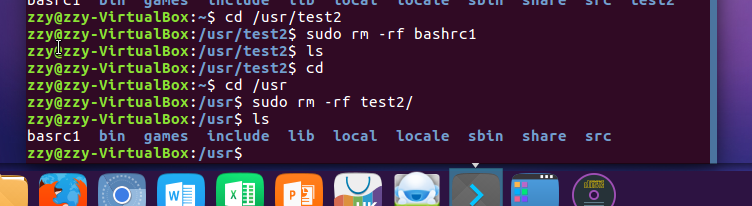
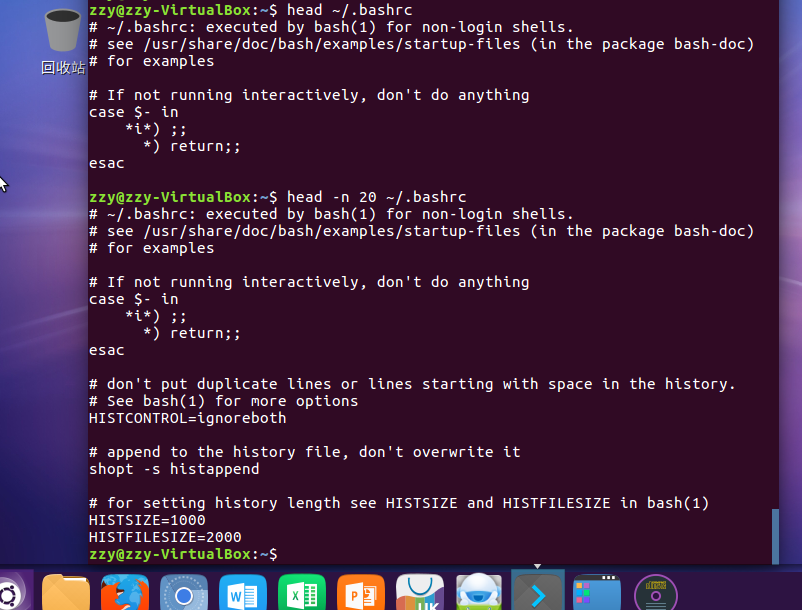
cat命令:查看文件内容
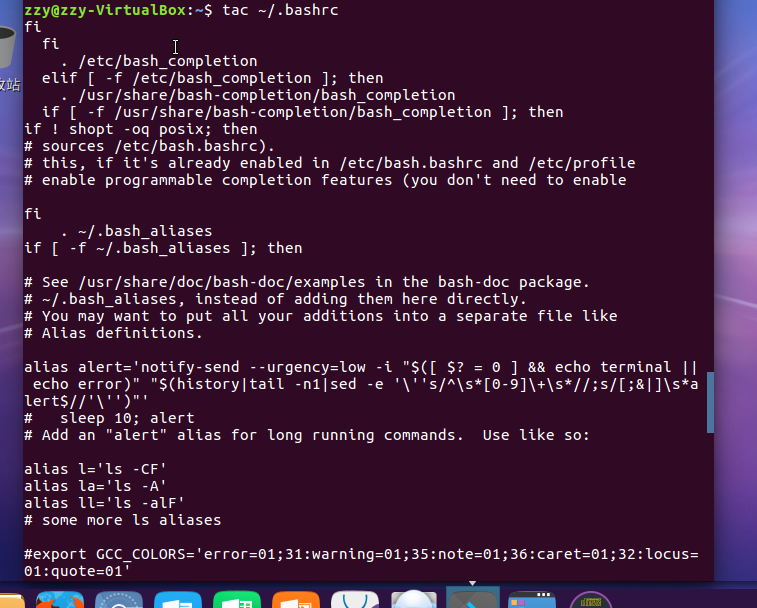
tac命令:反向列示
more命令:一页一页翻动查看
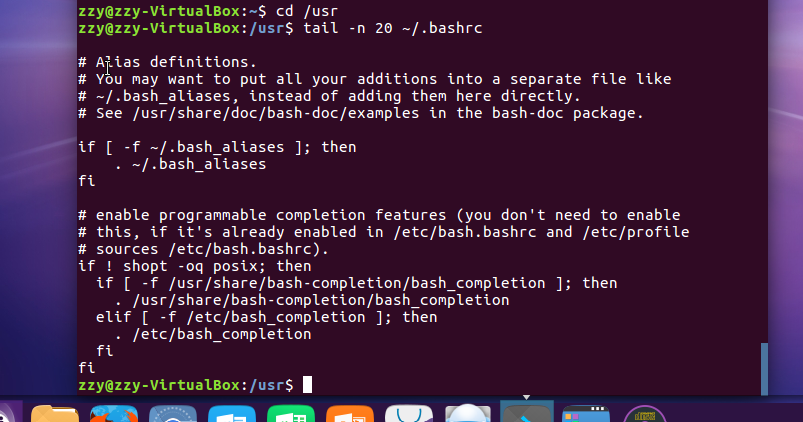
tail命令:取出后面几行
chown命令:修改文件所有者权限

Vim/gedit/文本编辑器
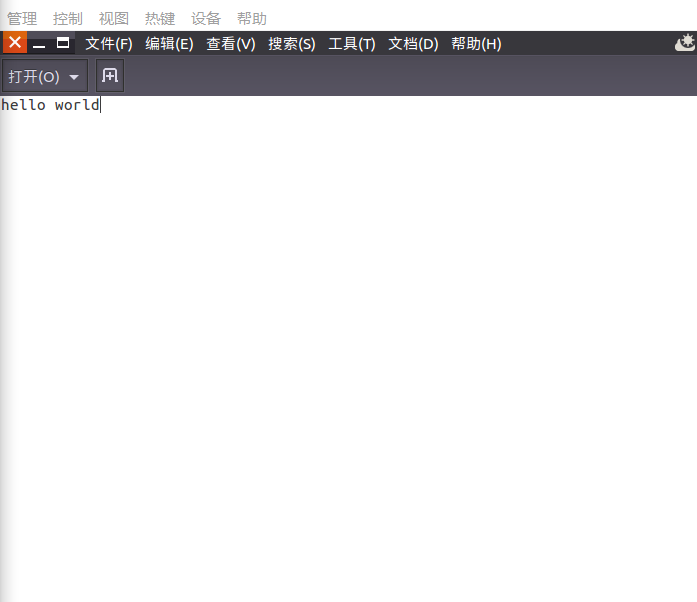

tar命令:压缩命令
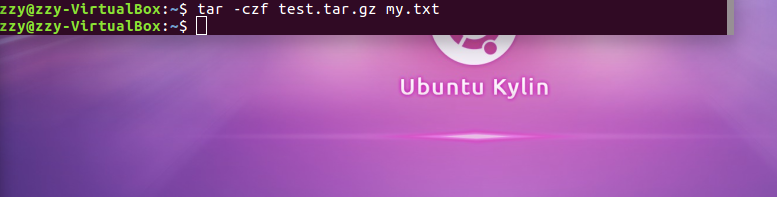

显示库:show databases

进入到库:use 库名
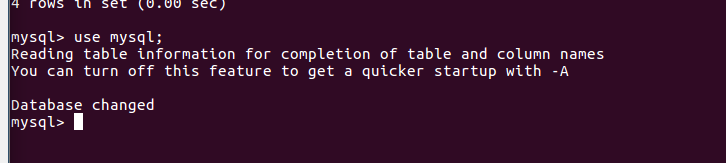
展示库里表格:show tables

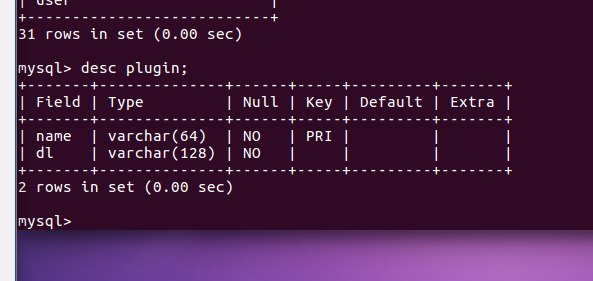
显示某一个表格属性:desc 表格名
显示某一个表格内的具体内容:select *form 表格名

创建一个数据库:create databases sc
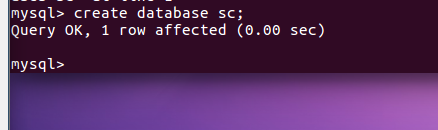
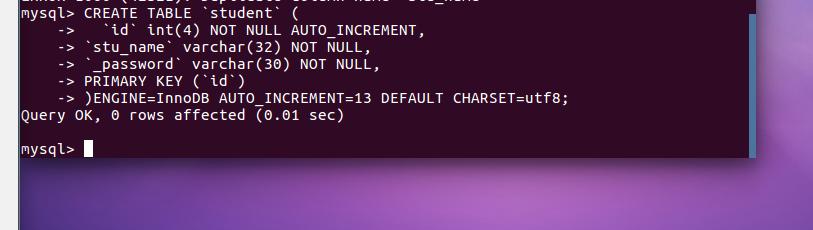
在sc中创建一个表格:create table if not exists student( )
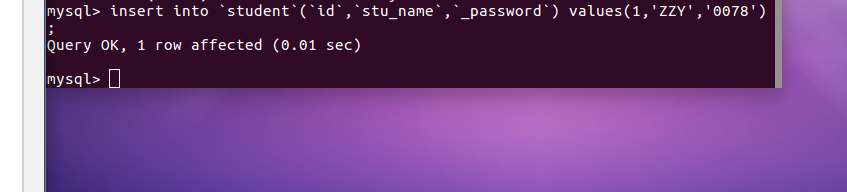
向表格student中插入具体内容:insert into 表格名(名)values(value)
显示表的内容

1.用图文与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop的起源
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
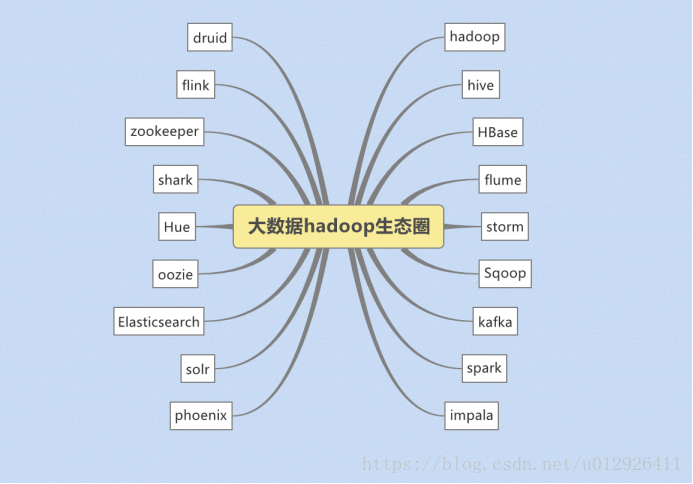
hadoop的历史版本
0.x系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
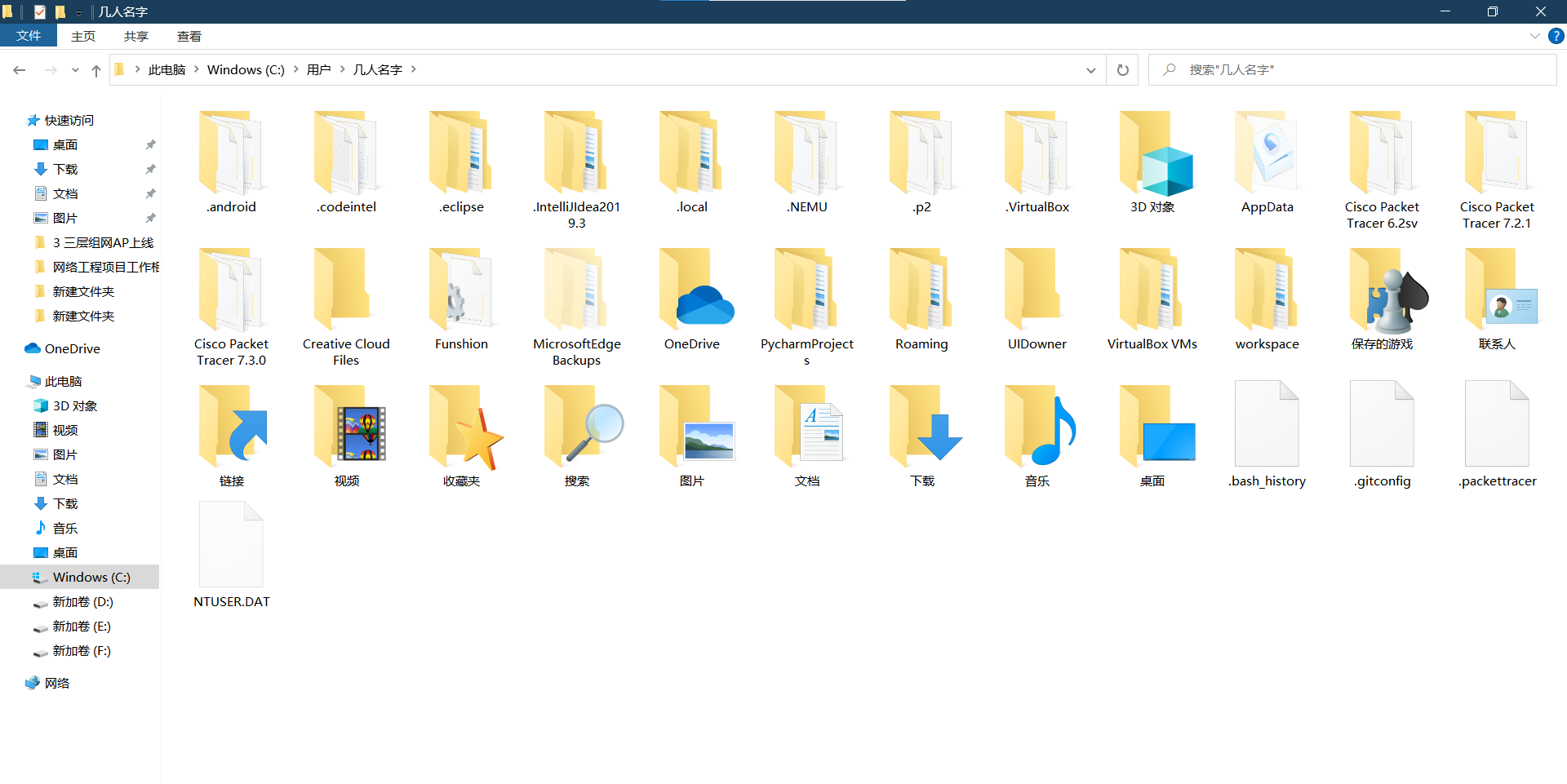
2.对比操作三个文件系统:分别用命令行与窗口方式查看windows,Linux和Hadoop的文件系统的用户主目录。
windows:
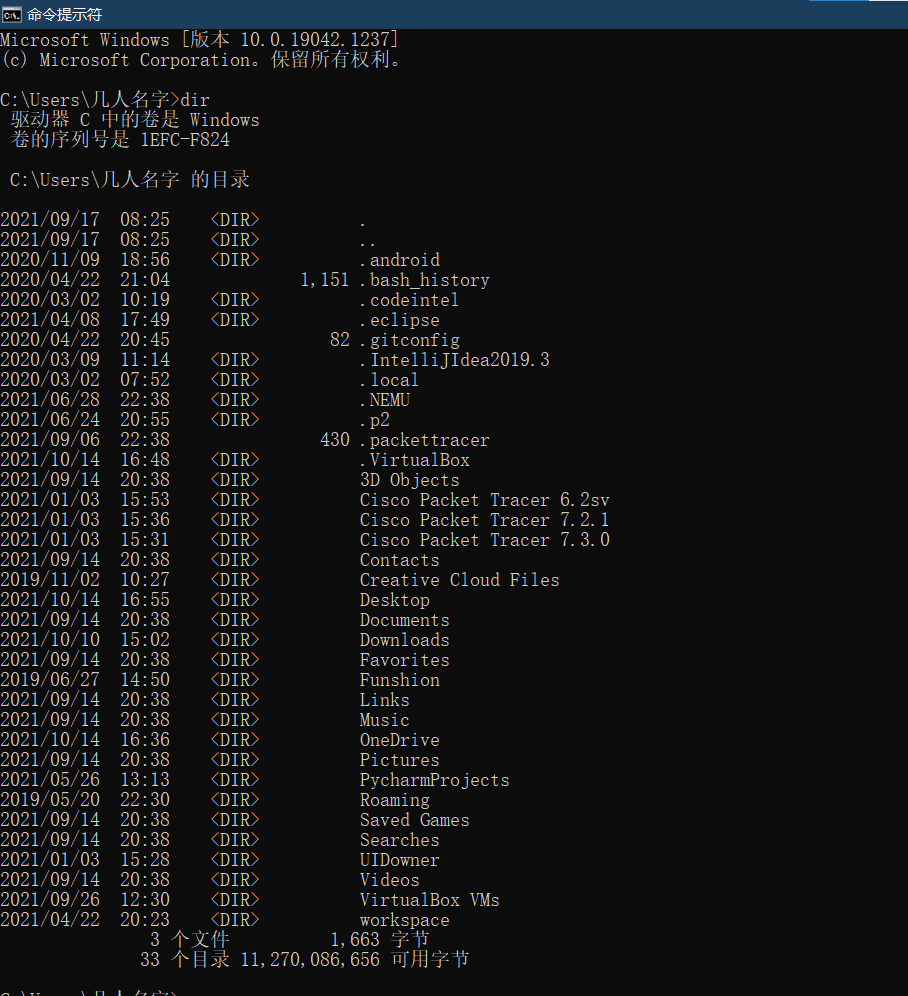
Linux:

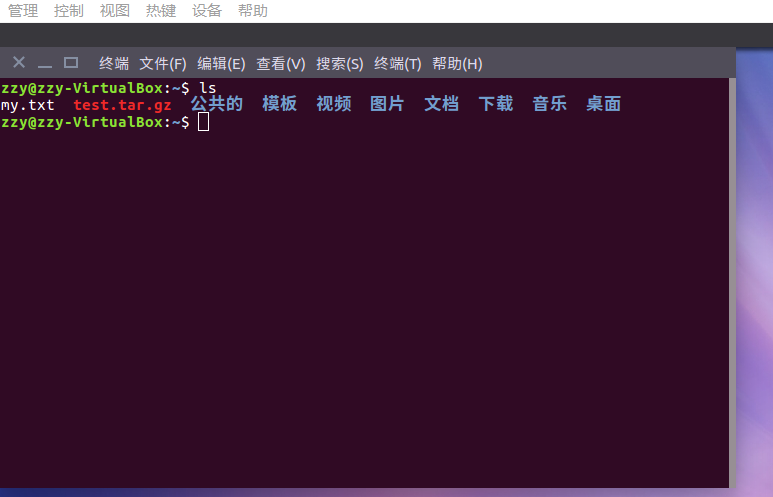
Hadoop:
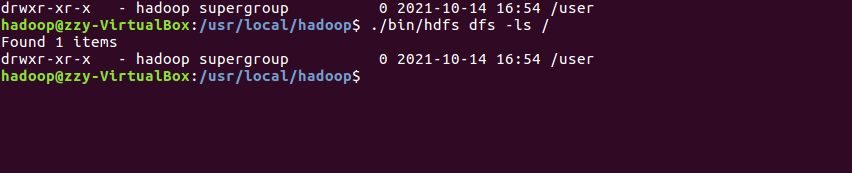
3.一个操作案例:
启动hdfs
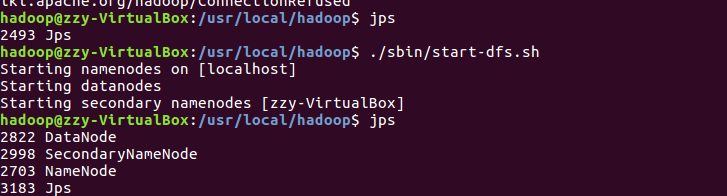
查看与创建hadoop用户目录。

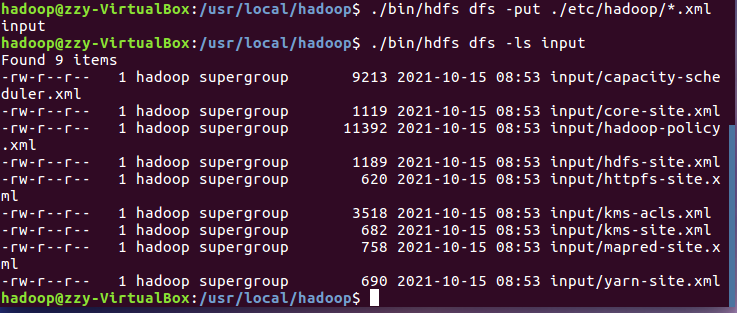
在用户目录下创建与查看input目录。

将hadoop的配置文件上传到hdfs上的input目录下。
运行MapReduce示例作业,输出结果放在output目录下。
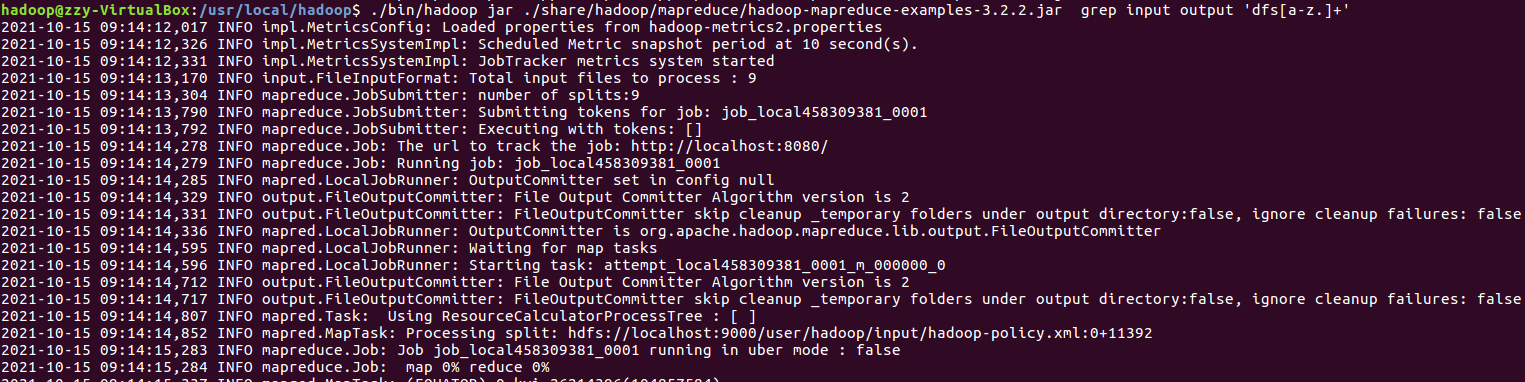
查看output目录下的文件。

查看输出结果
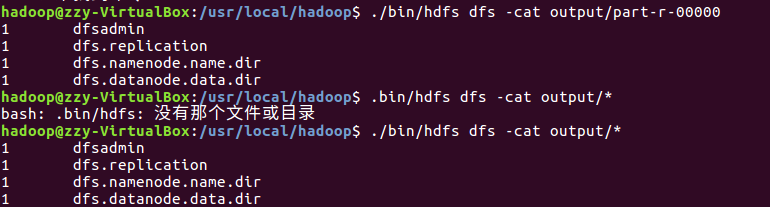
将输出结果文件下载到本地。
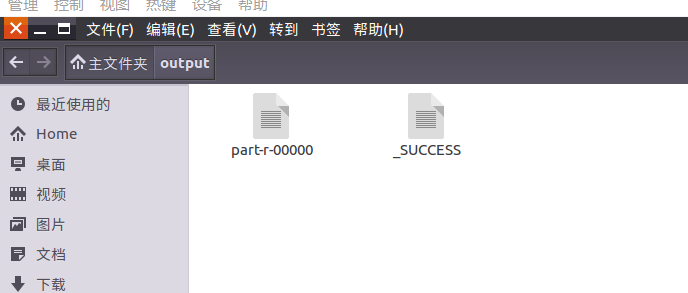
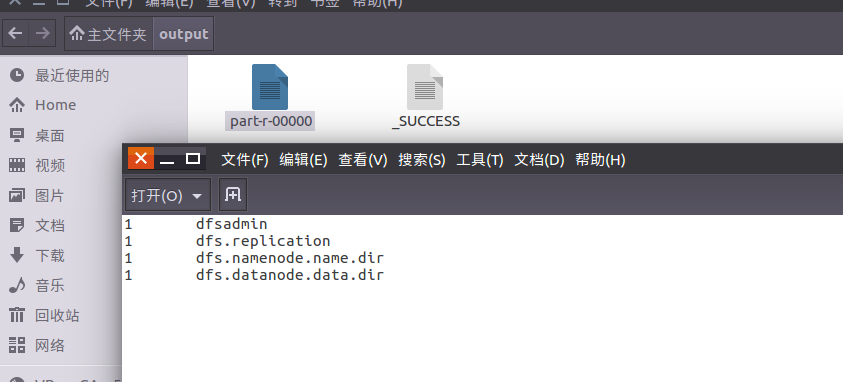
查看下载的本地文件。
停止hdfs


 浙公网安备 33010602011771号
浙公网安备 33010602011771号