<!--author--Kang-->
顺序表中,只要单单存放数据元素,而链表中,不仅要存放数据元素,还要存放下一个数据元素在内存中的位置。因此,存放数据元素的域称为数据域,存放后继位置的域为指针域,两者组成一个模块,称为结点,链表就是由n个节点组成的。链表具有以下几个特点:
1)将数据封装成结点,由结点组成的线性表;
2)通过结点的指针域将结点连接到一起;
3)结点的内存空间不一定时连续的,但逻辑上是连续的;
4)有一个头指针指向第一个数据元素;
5)链表是线性表的一种,是线性表的链式存储结构的实现。
其中,链表中每个结点只有一个指针域指向后继结点,这种链表称为单链表或线性链表
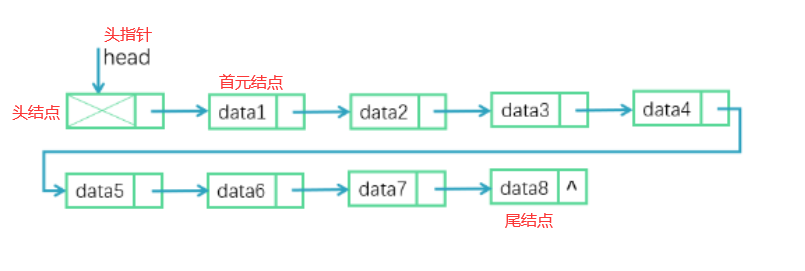
头结点:为了处理方便,会在链表的第一个元素前增加一个头结点,该结点的数据域中不存储线性表的数据元素,其作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理。
尾结点:最后一个结点的指针域为空指针
首元结点:链表中存储第一个数据元素的结点。如上图中data1结点。
头指针:通常用head名称定义,指向链表中第一个结点的指针,有头结点时指向头结点,若链表设计时不设头结点,则指向首元结点。
通过单链表的头指针可以完成单链表的所有操作,而单链表的结点有两个必须的属性:
1)数据元素信息:节点中的数据元素基本信息;
2)指针域:结点之间通过指针进行逻辑关联。用来存储下一个结点的地址。
由此可定义出线性表的链式存储的结构体类型:
注意这里的定义,按照前面的分析,实际上只需要有LINK_NODE类型定义就行了,我们可以通过定义LINK_NODE *head 来定义一个头指针,但为了提高程序的可读性,在用typedef定义单链表时起了两个别名,分别为LINK_NODE和LINK_LIST,而实际上LINK_LIST就是struct link_node * ,因此在定义单链表时可以定义为:
或者
当然,这里的list其实就是头指针head;
该步骤主要是为了完成头结点的创建以及相关指针的置空(下一结点)
1、先通过malloc给头结点分配空间
2、判断内存是否分配失败,失败返回0
3、头结点的next指针置空:(*L)->next = NULL;
4、操作结束,返回1
计算单链表中有效数据结点的个数(不包含头结点)
1、定义变量length,用来统计有效结点个数;
2、定义tmp指针指向首元结点,首元结点为头结点的下一结点:LINK_NODE *tmp = L->next;
3、通过while循环计算有效结点个数,循环条件:tmp指针为非空结点:tmp!=NULL
4、循环体内为length自增,tmp指针指向下一结点
5、返回长度length
1、先定义一个指针指向首元结点
2、通过while循环实现遍历,循环条件为 tmp!=NULL,即链表为非空或tmp指针没有超出链表范围
3、打印数据域中tmp->data;
4、将tmp指针指向下一结点,实现循环,当tmp指向尾结点时,即tmp->next==NULL,在下一个循环开始时跳出循环
1、定义一个p_insert指针指向头结点,用来存储待插入结点的前一个结点
2、判断插入位置 i 是否合理:即1< i < get_length(L) +1 (这里长度+1是将新结点插在末尾)
3、通过for循环移动p_insert指针,将p_insert指针指向插入位置 i 的前一个结点
4、创建新结点p_new,并给新结点分配空间。这里可以添加一个判断,如果空间分配失败,则返回0
5、给新结点的数据域赋值:p_new->data = e;
6、将第 i -1个结点所在地址(即 p_insert->next)赋值给新结点的next指针:p_new->next = p_ins->next;
7、将新结点的地址赋值给前一结点的next指针:p_insert->next = p_new;
1、判断删除位置是否合理,不合理则返回0 :1<i<get_length(L)
2、定义一个指针指向头结点,用来存储删除位置的前一个结点的地址:LINK_NODE *p_prev = L;
3、定义待删除结点的指针:LINK_NODE *p_del;
4、移动p_prev 指针,将指针指向删除节点 i 的前一个结点所在位置
5、通过待删除结点的前一结点 p_prev 给待删除结点 p_del 赋值地址
6、跳过删除结点,将待删除结点的下一结点指针地址p_del->next赋值给前一个结点的下一结点指针p_prev->next
7、释放待删除结点的空间:free(p_del),返回1,表示操作完成
两种方法,方法一:先创建一个新的结点,再将新结点覆盖到需要需要修改的结点上,最后删除旧结点;方法二:先找到要修改的结点,再直接修改该结点
1、创建p_find指针指向起始节点
2、通过循环变脸查找,循环条件为p_find!=NULL;
3、判断,如果当前指针指向结点的数据域与查找目标一致,返回当前结点的地址
4、p_find指针向后移一位,保证循环
5、跳出循环,返回NULL,说明未查找到数据
至此,单链表的增删改查结束。下面为调试的源码:
#include <stdio.h>
#include <malloc.h>
typedef int ElementType;//链表中元素的类型,根据实际情况而定,这里以int为例
//单链表结构体定义:
typedef struct link_node {
ElementType data;//结点的数据域
struct link_node* next;//结点的指针域
}LINK_NODE,*LINK_LIST;//这里LINK_LIST和 next 类型一致,都是struct link_node*类型
/*(LINK_LIST本身就是指针,因此定义头指针时可以直接这样 LINK_LIST head;)
也可以这样定义:LINK_NODE * head;
*/
//单链表的初始化操作:
//主要时为了完成头结点的创建以及相关指针的置空
int init_list(LINK_LIST *L){//在函数内部去修改函数外部数据时要用指针
*L = (LINK_NODE *)malloc(sizeof(LINK_NODE));//分配头结点空间
if (*L ==NULL)//如果内存分配失败
{
return 0;
}
(*L)->next = NULL;//头结点的next置为空
return 1;
}
//获取单链表长度:计算单链表中有效数据结点个数(不包含头结点)
int get_length(LINK_LIST L) {//这里不需要修改链表,直接用形参操作
int length = 0;
LINK_NODE *tmp = L->next;//从首元结点开始,而非头结点
while (tmp!=NULL)
{
length++;
tmp = tmp->next;//指针指向下一个结点
}
return length;
}
//单链表的遍历操作
void show(LINK_LIST L) {
LINK_NODE *tmp = L->next;//从首元结点开始,而非头结点
while (tmp != NULL)
{
printf("%d", tmp->data);//注意输出数据类型,这里以int为例
if (tmp->next!=NULL)
{
printf(",");
}
else {
printf("\n");//对最后一个结点数据输出后不加逗号处理
}
tmp = tmp->next;//将指针指向下一个结点
}
}
//单链表的插入操作
int insert(LINK_LIST L,int i,ElementType e) {
LINK_NODE *p_ins = L;//先定义一个指针指向头结点
//
if (i<1||i>get_length(L)+1)
{
return 0;
}
for (int j = 0; j < i-1; j++)//循环中可能会使得指针指向空,则意味着插入位置将会超过链表长度+1,使得操作失败,
{
p_ins = p_ins->next;//将p_ins指向要插入结点的前一个结点
}
LINK_NODE *p_new = (LINK_NODE *)malloc(sizeof(LINK_NODE));
if (p_new ==NULL)//分配空间失败,返回0
{
return 0;
}
p_new->data = e;//给数据域赋值
p_new->next = p_ins->next;//将新结点的next指向插入位置的原结点
p_ins->next = p_new;//将新结点链接到插入位置上
return 1;
}
//单链表的删除操作
int delt(LINK_LIST L,int i) {
if (i<1||i>get_length(L))
{
printf("操作失败,删除位置不存在!");
return 0;//删除失败
}
LINK_NODE *p_prev = L;//previous 定义 前一个结点
LINK_NODE *p_del;//定义待删除结点指针
for (int j = 0; j < i-1; j++)//移动i-1次,将prev指针指向要删除结点 i 的前一个结点;
{
p_prev = p_prev->next;
}
p_del = p_prev->next;//通过待删除结点的前一结点给待删除结点赋值地址
p_prev->next = p_del->next;//跳过删除结点,将待删除结点的指针域赋值给前一结点的指针域
free(p_del);//释放待删除结点的空间
return 1;
}
//单链表的修改操作
/*一:先删除,再插入
1、先新建一个新结点
2、给新结点赋值
3、删除要修改的结点
4、将新结点插入到删除结点的位置上
二:
1、找到要修改的结点
2、直接修改该结点
*/
int updata(LINK_LIST L,int i,ElementType e) {
if (i<1||i>get_length(L))//判断是否空表或位置是否合理
{
printf("操作失败,该位置不存在!");
return 0;
}
LINK_NODE *p_mod = L;//modify 定义指针指向头结点。也可以指向首元结点,但要注意下面循环次数会发生变化
for (int j = 0; j < i;j++) {//因为头指针指向头结点,所以移动i次。若指向首元结点,则移动i-1次,条件改为j<i-1
p_mod = p_mod->next;//将指针指向需要修改的位置
}
p_mod->data = e;//直接修改目标结点的数据域
return 1;
}
//单链表的查找操作
LINK_NODE *search(LINK_NODE *p_from,ElementType e) {//返回一个结点的指针
LINK_NODE *p_find = p_from;//指向起始结点
while (p_find!=NULL)//当前指向结点为有效结点
{
if(p_find->data==e){//当前指针指向结点的数据域与查找目标一致
//printf("已查找到目标数据!该数据地址为:0x%p\n",p_find);
return p_find;
}
p_find = p_find->next;//指针后移
}
printf("未找到该数据!\n");
return NULL;
}
int main() {
LINK_LIST list = NULL;//list为指针
//创建单链表
init_list(&list);
//调用插入函数
//int rlt = insert(list,2,1);//rlt:0 第一个位置没有元素,不能插入到第二个位置,
insert(list,1,1);
insert(list, 2, 2);
insert(list, 3, 3);
insert(list, 1, 4);
insert(list, 3, 5);
insert(list, 2, 99);
insert(list, 3, 99);
show(list);
//调用删除函数
int rlt1 = delt(list,6);
printf("rlt = %d\n",rlt1);
show(list);
int rlt2 = delt(list, 4);
printf("rlt2 = %d\n", rlt2);
show(list);
//调用修改函数
int rlt3 = updata(list,0,100);
printf("rlt3 = %d\n",rlt3);
int rlt4 = updata(list, 5, 100);
printf("rlt4 = %d\n", rlt4);
updata(list,1,99);
show(list);
updata(list, 2, 100);
show(list);
//调用查询函数
LINK_NODE *p_rlt1 = search(list, 88);
LINK_NODE *p_rlt2 = search(list,100);
LINK_NODE *p_rlt3 = list;
int index = 0;
while (1)//循环查找所有重复数据
{
p_rlt3 = search(p_rlt3->next,99);//从上一个找到的结点开始查询
if (p_rlt3==NULL)
{
break;
}
index++;
printf("已查找到第%d个数据的地址为0x%p\n",index,p_rlt3);
}
index = 0;
return 0;
}
__EOF__



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律