Spark文档阅读之一:Spark Overview
版本:2.4.5
1. spark的几种执行方式
1)交互式shell:bin/spark-shell
bin/spark-shell --master <MasterURL> 可配置不同的执行器
例如:
bin/spark-shell --master local # 本地单worker执行 bin/spark-shell --master local[K] # 本地K个worker执行,K为"*"(星号)时表示本机CPU核数 bin/spark-shell --master local[K, F] # spark.task.maxFailures = F,单个task失败F次后job失败,即task可以重试最多F-1次 bin/spark-shell --master spark://HOST:PORT # 连接已有的standalone cluster,standalone模式就是手动部署一个测试用的集群,包含master和slave,可以为单机环境(standalone模式使用说明:https://spark.apache.org/docs/latest/spark-standalone.html)(standalone有client模式和cluster模式。client模式中driver和提交任务的client在一个进程中;而cluster模式中driver在cluster的一个worker中执行,client提交任务后就结束退出了,另外cluster模式还以配置为任务非0退出后立即重跑。) bin/spark-shell --master spark://host1:port1,host2:port2 # 连接已有的基于ZK的standalone master(有多个master,其中一个是leader,挂了以后其他master恢复状态并上位) bin/spark-shell --master mesos://host:port # 连接已有的Mesos cluster(没细看) bin/spark-shell --master yarn # 连接一个Yarn集群,可以配置 --deploy-mode client/cluster (yarn的地址从hadoop配置中读取,不需要在命令中指定) bin/spark-shell --master k8s://host:port # 连接一个kubernetes集群(目前不支持client模式)
2)python: bin/pyspark & bin/spark-submit xx.py
3)R:bin/sparkR & bin/spark-submit xx.R
2. 任务的提交
spark-submit可以将任务提交到一个集群上,并且有统一的接口支持所有cluster manager(standalone、mesos、yarn、kubernetes)。
打包任务所有的依赖到一个jar包中,或者使用--py-files参数提交.py、.zip、.egg文件(多个文件需打包为一个.zip)
bin/spark-submit \ --class <main-class> \ # 任务入口 --master <master-url> \ # 支持多种cluster manager --deploy-mode <deploy-mode> \ # cluster / client,默认为client --conf <key>=<value> \ ... # other options,如--supervise(非0退出立即重启), --verbose(打印debug信息), --jars xx.jar(上传更多的依赖,逗号分隔,不支持目录展开) <application-jar> \ # main-class来自这个jar包,必须是所有节点都可见的路径,hdfs://或file:// [application-arguments] # 入口函数的参数 bin/spark-submit \ --master <master-url> \ <application-python> \ [application-arguments]
* 关于cluster / client模式:
如果任务提交机和worker执行机在同一个物理位置,可以用client模式;如果不再同一个位置,可以用cluster模式,让driver和worker一起执行,减少网络延迟。另外python没有standalone cluster模式。
* 很多配置可以放在spark-defaults.conf中,就不用在spark-submit中重复配置了
3. cluster模式
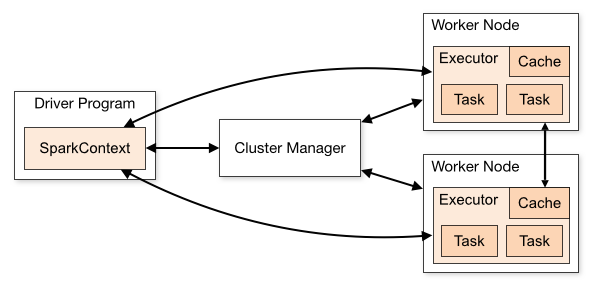
spark任务在集群上作为一个独立的资源集合运行,由driver的SparkContext对象进行管理。为了在集群上运行,SparkContext连接cluster manager让它来分配任务资源。一旦连接,spark从集群节点获取executors,用来进行计算和存储数据。之后,spark发送任务代码(jar或python)到executors中。最后,SparkContext发送tasks到executors执行。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号