[Python学习笔记]文件的读取写入
文件与文件路径
路径合成 os.path.join()
在Windows上,路径中以倒斜杠作为文件夹之间的分隔符,Linux或OS X中则是正斜杠。如果想要程序正确运行于所有操作系统上,就必须要处理这种情况。os.path.join()方法可以正确的根据不同的操作系统来合成路径,它的用法如下:
>>> import os
>>> os.path.join("Program", "QQ", "Pet")
'Program\\QQ\\Pet' # 在windows下返回的结果
'Program/QQ/Pet' # 在Linux或OS X下返回的结果
>>> myFiles = ["accounts.txt", "details.csv", "invite.docx"]
>>> for filename in myFiles:
... print(os.path.join("C:\\Users\\Dereen", filename))
C:\Users\Dereen\accounts.txt
C:\Users\Dereen\details.csv
C:\Users\Dereen\invite.docx
查看并改变当前工作目录
使用os.getcwd()来获取当前工作目录,使用os.chdir()来改变当前工作目录。这么做的意义是所有没有从根文件夹开始的文件名或路径,都假定在当前工作目录下。如果当前工作目录错误容易引发各种该问题,或者不想用当前工作目录作为根目录,而是想用别的目录作为根目录。
>>> os.getcwd()
'F:\\Learn\\Automate-the-Boring-Stuff-with-Python-Solutions'
>>> os.chdir("C:\\Windows\\system32")
>>> os.getcwd()
'C:\\Windows\\system32'
绝对路径与相对路径
- “绝对路径”:总是从根文件夹开始;
- “相对路径”:它相对于程序的当前工作目录。
例如:C:\Program Files\QQ\music
假如当前工作目录为C:\Program Files,则对music文件夹来说,其相对路径为:.\QQ\music,绝对路径为:C:\Program Files\QQ\music。
创建新文件夹 os.makedirs()
>>> os.makedirs(".\\color\\green")
上面这个命令会直接在当前文件夹下创建新文件夹color并在其下创建新文件夹green
绝对路径与相对路径互转
- 相对路径转绝对路径:
os.path.abspath(path)将返回参数的绝对路径的字符串。 - 绝对路径转相对路径:
os.path.relpath(path, start)将返回从start路径到path路径的相对路径的字符串。(如果没有提供start,就是用当前工作目录作为开始路径) - 判断一个路径是否为绝对路径:
os.isabs(path)如果是就返回True,不是就返回False。
例子:
>>> os.path.abspath(".")
'F:\\Learn\\Automate-the-Boring-Stuff-with-Python-Solutions'
>>> os.path.relpath("C:\\Windows", "C:\\Hello\Kitty\S")
'..\\..\\..\\Windows'
>>> os.path.isabs(".")
False
目录名称和基本名称(路径分割)
os.path.dirname(path)返回path参数中最后一个斜杠之前的所有内容;os.path.basename(path)返回path参数中最后一个斜杠之后的所有内容。os.path.split(path)返回一个元组,同时包含2者。
例子:
>>> path = "C:\\Windows\\system32\\tasks\\calc.exe"
>>> os.path.dirname(path)
'C:\\Windows\\system32\\tasks'
>>> os.path.basename(path)
'calc.exe'
>>> os.path.split(path)
('C:\\Windows\\system32\\tasks', 'calc.exe')
如果想要路径进行进一步的分割,就要调用字符串中的split()方法。并向其传入os.path.sep参数。(os.path.sep在不同的操作系统下,值也不同,在windows下值为"\"),例子:
>>> path.split(os.path.sep)
['C:', 'Windows', 'system32', 'tasks', 'calc.exe']
查看文件大小和文件夹内容
使用os.path.getsize(filepath)来查看单个文件的大小,注意不能查看文件夹的大小。使用os.listdir(path)来查看该目录下的所有文件及文件夹。二者组合使用可以计算文件夹的大小。例如:
>>> os.path.getsize("C:\\Windows\\System32\\calc.exe")
27648
>>> os.listdir("C:\\Windows\\System32")
['0409', '@AppHelpToast.png', '@AudioToastIcon.png', '@BackgroundAccessToastIcon.png', '@bitlockertoastimage.png', '@edptoastimage.png', '@EnrollmentToastIcon.png',
--snip--
'xwreg.dll', 'xwtpdui.dll', 'xwtpw32.dll', 'zh-CN', 'zh-HANS', 'zh-TW', 'zipcontainer.dll', 'zipfldr.dll', 'ztrace_maps.dll']
>>> totalSize = 0
>>> for file in os.listdir("C:\\Windows\\System32"):
... totalSize += os.path.getsize(os.path.join("C:\\Windows\\System32", file))
...
>>> print(totalSize)
2249563697
检查路径有效性
使用os.path.exists(path)检查path所指的文件或文件夹是否存在;os.path.isdir()检查参数path传入的值是否为一个文件夹;os.path.isfile()检查参数path传入的值是否为一个文件。例如;
>>> os.path.exists(r"C:\Windows")
True
>>> os.path.isdir(r"C:\Windows")
True
>>> os.path.isfile(r"C:\Windows")
False
文件读写过程
在开始前先介绍一下文件的分类:
- 纯文本文件:只包含基本文本字符,不包含字体、大小、颜色和其他信息。例如:.txt文件、.md文件和.py文件;
- 二进制文件:所有其他文件类型,例如.pdf文件、.docx文件等;使用纯文本文件编辑器打开一个二进制文件就会显示乱码,如图:
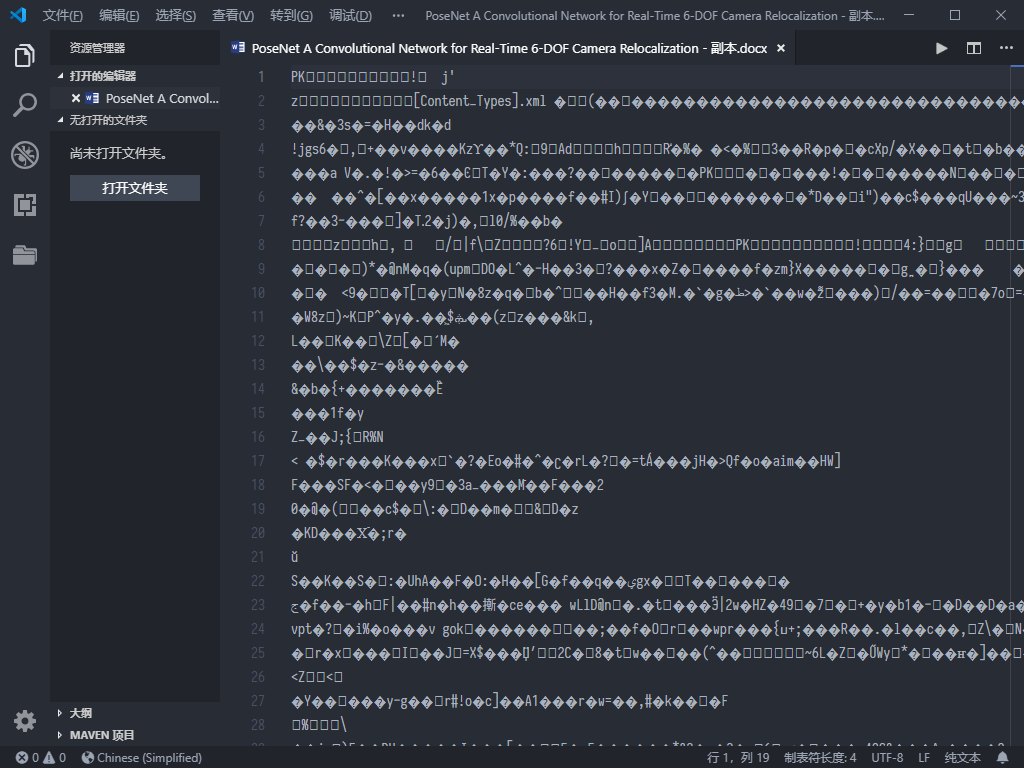
在Python中,读写文件有3个步骤:
- 调用
open()函数,返回一个File对象; - 调用File对象的
read()或write()方法; - 调用File对象的
close()方法,关闭该文件。
打开文件
使用open()函数打开文件,在打开文件时可同时传入参数(默认为‘r’,只读模式)。该函数会返回一个对象,该对象包含文档内容以及名称、打开模式以及文档编码模式。例如:
>>> content = open("README.md", "w")
>>> content
<_io.TextIOWrapper name='README.md' mode='w' encoding='UTF-8'>
| 传递参数 | 含义 |
|---|---|
| r | 只读模式打开,即只能读取文件内容不能写入 |
| w | 可以写入内容,但是会清除原文档所有内容 |
| x | 用于创建并写新文档 |
| a | 用于在文档尾部进行扩展(不会清除原文档内容) |
读取文件内容
在上一步中,我们使用open()函数打开文件并返回了一个文件对象,这里,我们可以使用read()或readlines()方法读取这个文件对象中的内容。其中,前者将文件中的所有内容读取为一个大字符串,后者按行读取文件,每行为一个字符串并最终形成一个列表。
>>> contentFile = open("hello.txt")
>>> contentFile.readlines()
['How are you?\n', "I'm fine, thanks, and you?\n", "I'm fine, too."]
>>> contentFile.read()
''
>>> contentFile.seek(0)
0
>>> contentFile.read()
"How are you?\nI'm fine, thanks, and you?\nI'm fine, too."
上面的代码中,由于先使用了readlines()方法,所以在使用read()方法时,文件指针已经到了第四行,而第四行是没有内容的,所以read()方法返回的值为空。为了解决这个问题我们使用seed()方法,将文件指针重新指向第1行。然后在执行接下来的read()操作就可以了。
写入文件
使用write()方法向文件中写入新内容。当以只读模式打开时,不能写入新内容。以w模式打开文件写入时会覆盖掉文件中所有原内容,以a模式打开文件写入时会在文件尾部插入新内容。
当打开的文件不存在时,w和a模式都会新建一个文件并写入内容。在读取或写入后,要调用close()方法,然后才能再次打开该文件。
>>> contentFile.close()
>>> contentFile = open("hello.txt", "a")
>>> contentFile.write("Thank you!")
10
>>> contentFile.close()
>>> contentFile = open("hello.txt")
>>> contentFile.read()
"How are you?\nI'm fine, thanks, and you?\nI'm fine, too.Thank you!"
用shelve模块保存变量
利用shelve模块,可以将Python程序中的变量保存到二进制的shelf文件中。这样,程序就可以从硬盘中恢复变量的数据。shelve模块相当于让我们在程序中增加“保存”和“打开”功能。例如,运行一个程序,并输入了一些配置设置,就可以将这些设置保存到一个shelf文件,然后让程序下一次运行时加载它们。
>>> import shelve
>>> shelfFile = shelve.open("mydata")
>>> cats = ["Libai", "Dufu", 'Zhupi', 'Zhongfen']
>>> shelfFile['cats'] = cats
>>> shelfFile.close()
这个程序会在当前目录下生成三个文件:mydata.bak、mydata.dat和mydata.dir。
>>> shelfFile = shelve.open('mydata')
>>> type(shelfFile)
<class 'shelve.DbfilenameShelf'>
>>> shelfFile['cats']
['Libai', 'Dufu', 'Zhupi', 'Zhongfen']
>>> shelfFile.close()
上面的代码检查了shelfFile中的内容,像字典一样,shelf值有keys()和values()方法,返回shelf中键和值的类似列表的值。要想使用它们,我们还要把它们转化为列表类型:
>>> shelfFile = shelve.open('mydata')
>>> list(shelfFile.keys())
['cats']
>>> list(shelfFile.values())
[['Libai', 'Dufu', 'Zhupi', 'Zhongfen']]
>>> list(shelfFile.values())[0]
['Libai', 'Dufu', 'Zhupi', 'Zhongfen']
>>> shelfFile.close()
使用pprint.pformat()函数保存变量
pprint()是一种将列表、字典或元组以更漂亮、规范的格式输出的一个方法。我们可以利用pprint.pformat()函数将变量写入.py文件。该文件将成为一个模块,方便我们下次进行使用。而且与shelve模块中的方法不同的事,.py文件能够方便的使用一些常见的记事本文件打开查看。例子:
>>> import pprint
>>> cats = [{'name': 'Libai', 'color': 'White'}, {'name': 'Zhupi', 'color': 'Orange'}]
>>> pprint.pformat(cats)
"[{'color': 'White', 'name': 'Libai'}, {'color': 'Orange', 'name': 'Zhupi'}]"
>>> file = open('myCats.py', 'w')
>>> file.write('cats = ' + pprint.pformat(cats) + '\n')
83
>>> file.close()
>>> import myCats
>>> myCats.cats
[{'color': 'White', 'name': 'Libai'}, {'color': 'Orange', 'name': 'Zhupi'}]
>>> myCats.cats[0]
{'color': 'White', 'name': 'Libai'}
>>> myCats.cats[0]['name']
'Libai'
值得注意的是,对于大多数的应用,我们还是利用shelve模块来保存数据。只有基本数据类型,例如整型、浮点型、字符串、列表和字典等,可以用这个方法当做简单文本写入文件。
小项目一(随机测验试卷生成)
假如一位老师要考察班上35名同学对于美国50个州首府的了解情况,他打算用选择题的形式来考察。但是为了防止有人作弊,他打算将题目的顺序打乱且每道题目的选项中除了正确的那个,其他的都是从其他49个州的首府中随机抽取的,那么下面的代码会很有用:
# randomQuizGenerator.py - Create quizzes with questions and answers in random order, along with the answer key.
import random
# The quiz data. Key are states and values are their capitals.
capitals = {
'Alabama': 'Montgomery',
'Alaska': 'Juneau',
'Arizona': 'Phoenix',
'Arkansas': 'Little Rock',
'California': 'Sacramento',
'Colorado': 'Denver',
'Connecticut': 'Hartford',
'Delaware': 'Dover',
'Florida': 'Tallahassee',
'Georgia': 'Atlanta',
'Hawaii': 'Honolulu',
'Idaho': 'Boise',
'Illinois': 'Springfield',
'Indiana': 'Indianapolis',
'Iowa': 'Des Monies',
'Kansas': 'Topeka',
'Kentucky': 'Frankfort',
'Louisiana': 'Baton Rouge',
'Maine': 'Augusta',
'Maryland': 'Annapolis',
'Massachusetts': 'Boston',
'Michigan': 'Lansing',
'Minnesota': 'Saint Paul',
'Mississippi': 'Jackson',
'Missouri': 'Jefferson City',
'Montana': 'Helena',
'Nebraska': 'Lincoln',
'Nevada': 'Carson City',
'New Hampshire': 'Concord',
'New Jersey': 'Trenton',
'New Mexico': 'Santa Fe',
'New York': 'Albany',
'North Carolina': 'Raleigh',
'North Dakota': 'Bismarck',
'Ohio': 'Columbus',
'Oklahoma': 'Oklahoma City',
'Oregon': 'Salem',
'Pennsylvania': 'Harrisburg',
'Rhode Island': 'Providence',
'South Carolina': 'Columbia',
'South Dakota': 'Pierre',
'Tennessee': 'Nashville',
'Texas': 'Austin',
'Utah': 'Salt Lake City',
'Vermont': 'Montpelier',
'Virginia': 'Richmond',
'Washington': 'Olympia',
'West Virginia': 'Charleston',
'Wisconsin': 'Madison',
'Wyoming': 'Cheyenne'
}
# Generate 35 quiz files.
for quizNum in range(35):
# Create the quiz and answer key files.
quizFile = open('capitalsquiz%s.txt' % (quizNum + 1), 'w')
answerKeyFile = open('capitalsquiz_answers%s.txt' % (quizNum + 1), 'w')
# Write out the header for the quiz.
quizFile.write('Name:\n\nDate:\n\nPeriod:\n\n')
quizFile.write((' ' * 20) + 'State Capitals Quiz (Form %s)' % (quizNum + 1))
quizFile.write('\n\n')
# Shuffle the order of the states.
states = list(capitals.keys())
random.shuffle(states)
# Loop through all 50 states, making a question for each.
for questionNum in range(50):
# Get right and wrong answers.
correctAnswer = capitals[states[questionNum]]
wrongAnswers = list(capitals.values())
del wrongAnswers[wrongAnswers.index(correctAnswer)]
wrongAnswers = random.sample(wrongAnswers, 3)
answerOptions = wrongAnswers + [correctAnswer]
random.shuffle(answerOptions)
# Write the question and the answer options to the quiz file.
quizFile.write('%s. What is the capital of %s?\n' % (questionNum + 1, states[questionNum]))
for i in range(4):
quizFile.write('%s. %s\n' % ('ABCD' [i], answerOptions[i]))
quizFile.write('\n')
# Write the answer key to a file.
answerKeyFile.write('%s. %s\n' % (questionNum + 1, 'ABCD' [answerOptions.index(correctAnswer)]))
quizFile.close()
answerKeyFile.close()
小项目二(多重剪贴板)
这个代码实现了一个简单的功能,即将剪贴板中的内容以关键字的方式保存,而且可以以关键字的方式提取,相当于一个暂存(多重)剪贴板。
# mab.pyw - Saves and loads pieces of text to the clipboard.
# Usage: py.exe mcb.pyw save <keyword> - Saves clipboard to keyword.
# py.exe mcb.pyw <keyword> - Loads keyword to clipboard.
# py.exe mcb.pyw list - Loads all keywords to clipboard.
import shelve
import pyperclip
import sys
mcbShelf = shelve.open('mcb')
# Save clipboard content.
if len(sys.argv) == 3 and sys.argv[1].lower() == 'save':
mcbShelf[sys.argv[2]] = pyperclip.paste()
elif len(sys.argv) == 2:
# List keywords and load content.
if sys.argv[1].lower() == 'list':
pyperclip.copy(str(list(mcbShelf.keys())))
elif sys.argv[1] in mcbShelf:
pyperclip.copy(mcbShelf[sys.argv[1]])
mcbShelf.close()
[Python学习笔记]系列是我在学习《Python编程快速上手——让繁琐工作自动化(Automate The Boring Stuff With Python)》这本书时的学习笔记。通过自己再手敲一遍概念和代码,方便自己记忆和日后查阅。如果对你有帮助,那就更好了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号