keepalived + haproxy部署高可用k8s master
转载于:https://www.kubernetes.org.cn/6964.html
关键问题
根据K8s官方文档将HA拓扑分为两种,Stacked etcd topology(堆叠ETCD)和External etcd topology(外部ETCD)。 https://kubernetes.cn/docs/setup/production-environment/tools/kubeadm/ha-topology/#external-etcd-topology
堆叠ETCD: 每个master节点上运行一个apiserver和etcd, etcd只与本节点apiserver通信。
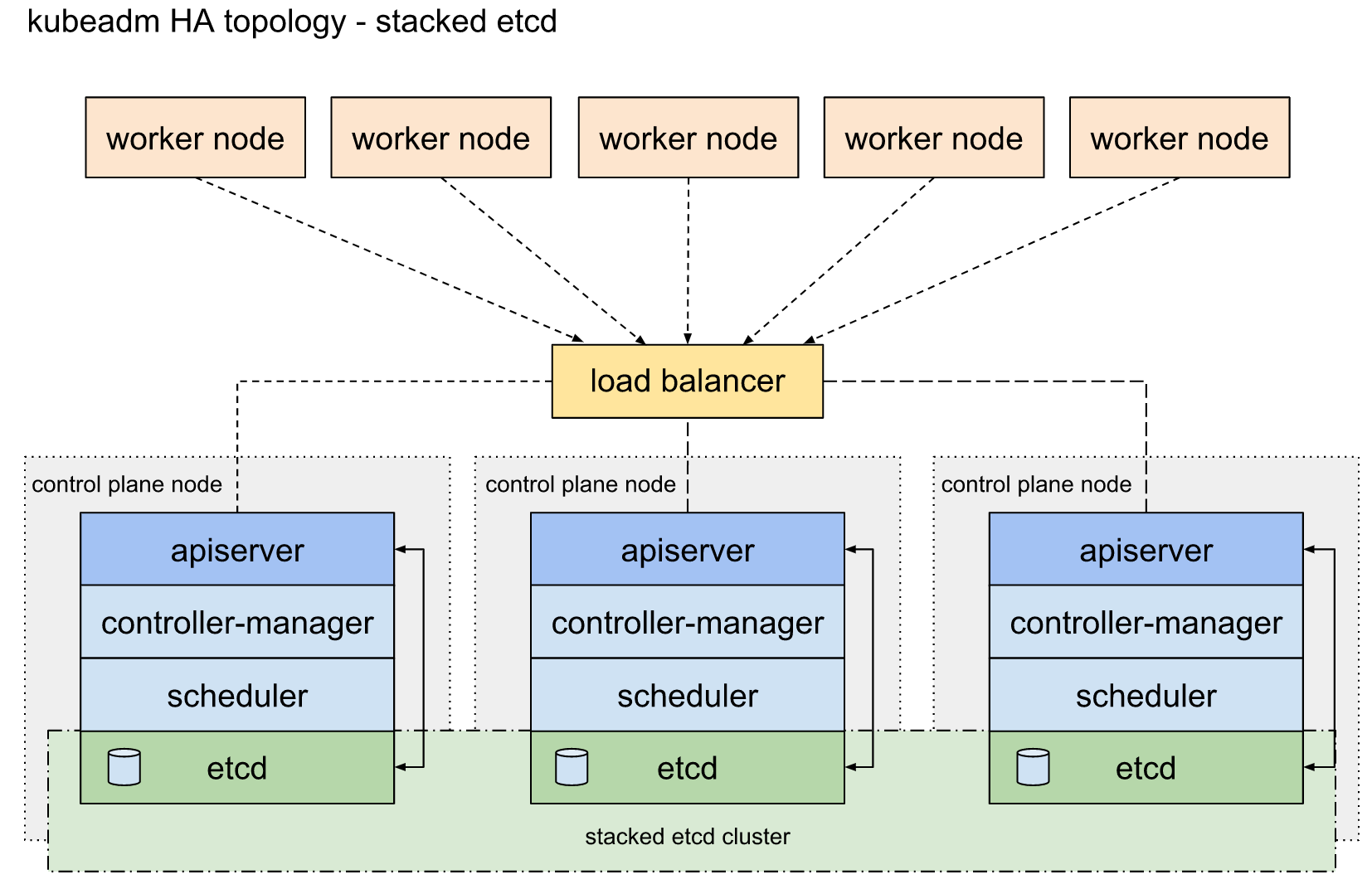
外部ETCD: etcd集群运行在单独的主机上,每个etcd都与apiserver节点通信。
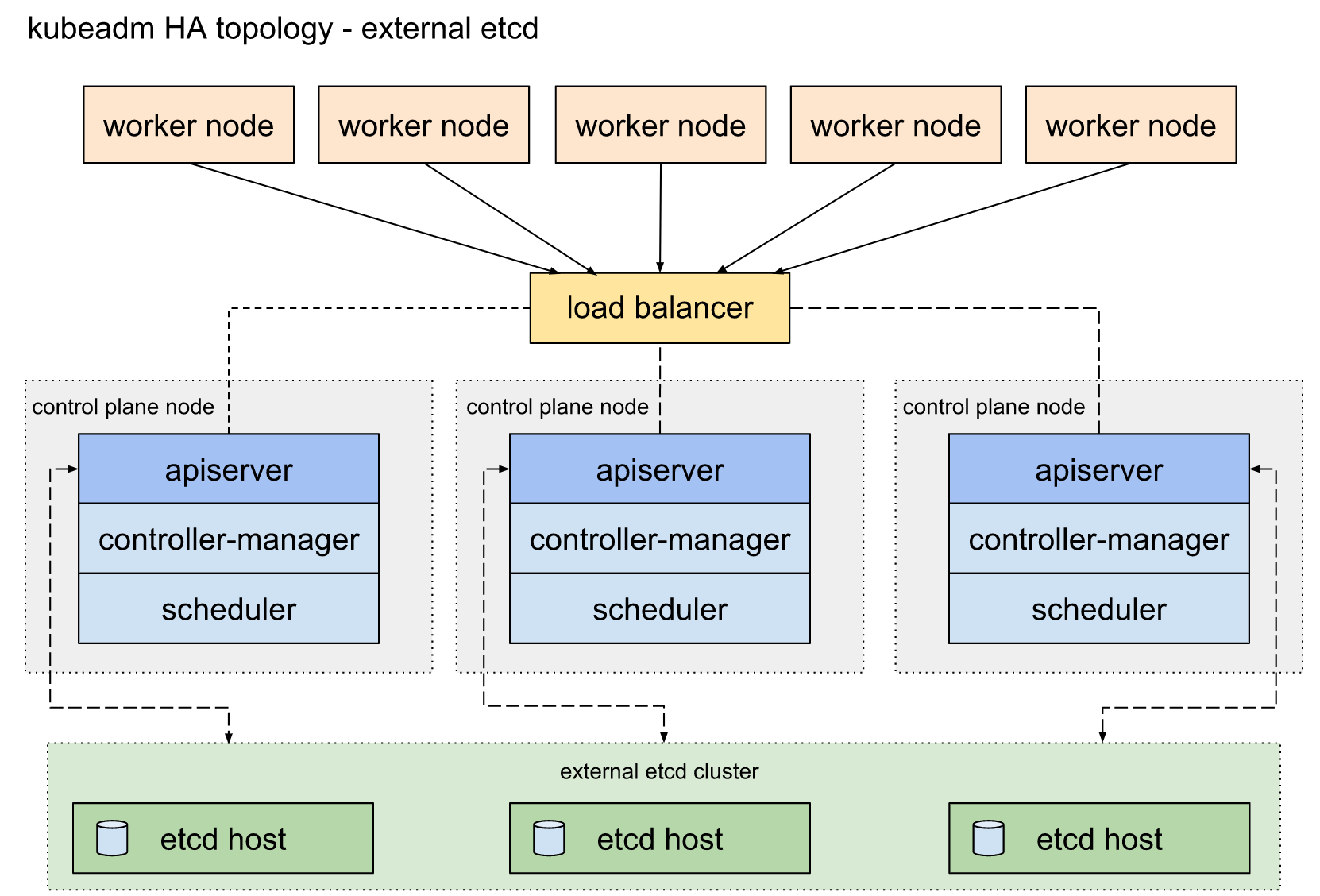
官方文档主要是解决了高可用场景下apiserver与etcd集群的关系, 三master节点防止单点故障。但是集群对外访问接口不可能将三个apiserver都暴露出去,一个挂掉时还是不能自动切换到其他节点。官方文档只提到了一句“使用负载均衡器将apiserver暴露给工作程序节点”,而这恰恰是生产环境中需要解决的重点问题。
Notes: 此处的负载均衡器并不是kube-proxy,此处的Load Balancer是针对apiserver的。
部署架构
以下是我们在生产环境所用的部署架构:
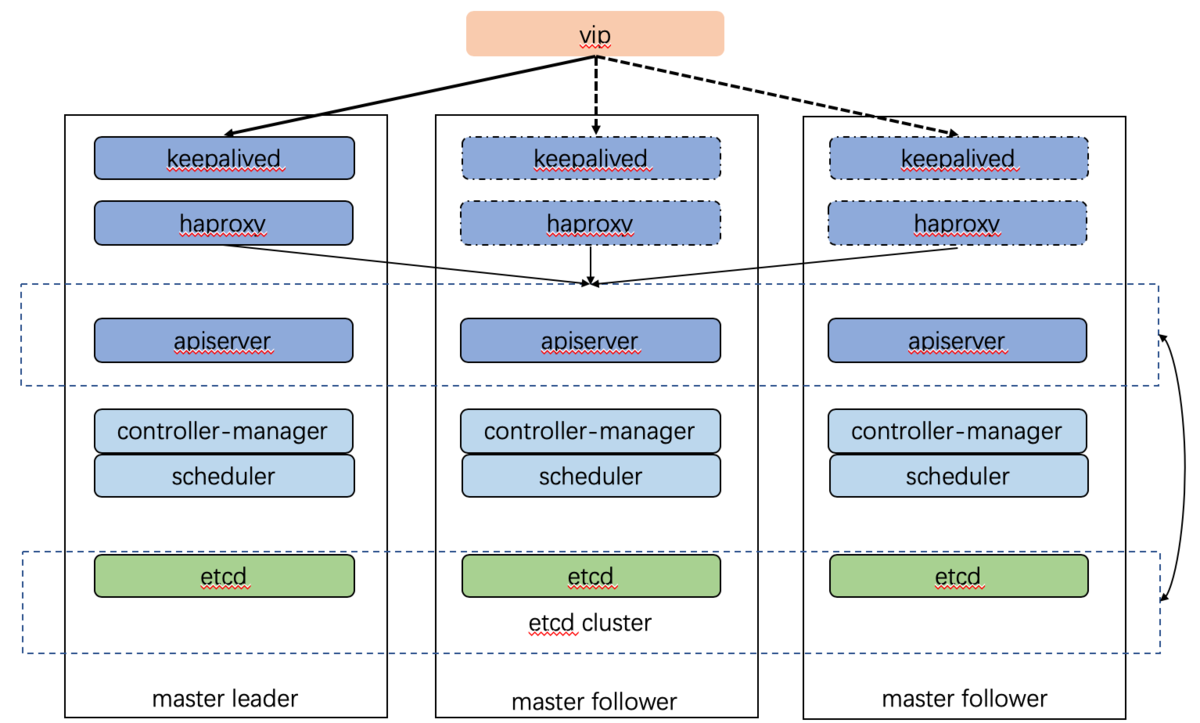
- 由外部负载均衡器提供一个vip,流量负载到keepalived master节点上。
- 当keepalived节点出现故障, vip自动漂到其他可用节点。
- haproxy负责将流量负载到apiserver节点。
- 三个apiserver会同时工作。注意k8s中controller-manager和scheduler只会有一个工作,其余处于backup状态。我猜测apiserver主要是读写数据库,数据一致性的问题由数据库保证,此外apiserver是k8s中最繁忙的组件,多个同时工作也有利于减轻压力。而controller-manager和scheduler主要处理执行逻辑,多个大脑同时运作可能会引发混乱。
下面以一个实验验证高可用性。准备三台机器以及一个vip(阿里云,openstack等都有提供)。
haproxy
haproxy提供高可用性,负载均衡,基于TCP和HTTP的代理,支持数以万记的并发连接。https://github.com/haproxy/haproxy
haproxy可安装在主机上,也可使用docker容器实现。文本采用第一种。
安装haproxy
yum install -y haproxy
创建配置文件/etc/haproxy/haproxy.cfg,重要配置以中文注释标出:
#--------------------------------------------------------------------- # Example configuration for a possible web application. See the # full configuration options online. # # https://www.haproxy.org/download/2.1/doc/configuration.txt # https://cbonte.github.io/haproxy-dconv/2.1/configuration.html # #--------------------------------------------------------------------- #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # # 1) configure syslog to accept network log events. This is done # by adding the '-r' option to the SYSLOGD_OPTIONS in # /etc/sysconfig/syslog # # 2) configure local2 events to go to the /var/log/haproxy.log # file. A line like the following can be added to # /etc/sysconfig/syslog # # local2.* /var/log/haproxy.log # log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 #--------------------------------------------------------------------- # main frontend which proxys to the backends #--------------------------------------------------------------------- frontend kubernetes-apiserver mode tcp bind *:9443 ## 监听9443端口 # bind *:443 ssl # To be completed .... default_backend kubernetes-apiserver #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend kubernetes-apiserver mode tcp # 模式tcp balance roundrobin # 采用轮询的负载算法 # k8s-apiservers backend # 配置apiserver,端口6443 server master-192.168.130.130 192.168.130.130:6443 check server master-192.168.130.131 192.168.130.131:6443 check server master-192.168.130.132 192.168.130.132:6443 check
分别在三个节点启动haproxy
[root@ST-K8S-01 ~]# systemctl restart haproxy && systemctl status haproxy
[root@ST-K8S-01 ~]# systemctl enable haproxy
如果采用第二种容器化方式部署,可以使用如下命令启动:
另外配置文件中修改 stats socket /var/lib/haproxy/stats 为 stats socket /usr/local/etc/haproxy/stats 。
docker run -d --name=haproxy --net=host --restart=always -v /etc/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro 10.2.55.8:5000/library/haproxy:2.4-dev
keepalived
keepalived是以VRRP(虚拟路由冗余协议)协议为基础, 包括一个master和多个backup。 master劫持vip对外提供服务。master发送组播,backup节点收不到vrrp包时认为master宕机,此时选出剩余优先级最高的节点作为新的master, 劫持vip。keepalived是保证高可用的重要组件。
keepalived可安装在主机上,也可使用docker容器实现。文本采用第一种。(https://github.com/osixia/docker-keepalived)
安装keepalived
yum install -y keepalived
配置keepalived.conf, 重要部分以中文注释标出:
global_defs {
script_user root
enable_script_security
}
vrrp_script chk_haproxy {
script "/bin/bash -c 'if [[ $(netstat -nlp | grep 9443) ]]; then exit 0; else systemctl stop keepalived;fi'" # haproxy 检测
interval 2 # 每2秒执行一次检测
weight -2 # 权重变化
}
vrrp_instance VI_1 {
interface ens33 ###宿主机网卡名
state BACKUP
virtual_router_id 51 # id设为相同,表示是同一个虚拟路由组
priority 100 #初始权重
nopreempt #不抢占
unicast_peer {
}
virtual_ipaddress {
192.168.130.133 # vip
}
authentication {
auth_type PASS
auth_pass password
}
track_script {
chk_haproxy
}
}
- vrrp_script用于检测haproxy是否正常。如果本机的haproxy挂掉,即使keepalived劫持vip,也无法将流量负载到apiserver。
- 我所查阅的网络教程全部为检测进程, 类似
killall -0 haproxy。这种方式用在主机部署上可以,但容器部署时,在keepalived容器中无法知道另一个容器haproxy的活跃情况,因此我在此处通过检测端口号来判断haproxy的健康状况。 - weight可正可负。为正时检测成功+weight,相当与节点检测失败时本身priority不变,但其他检测成功节点priority增加。为负时检测失败本身priority减少。
- 另外很多文章中没有强调nopreempt参数,意为不可抢占,此时master节点失败后,backup节点也不能接管vip,因此我将此配置删去。
分别在三台节点启动keepalived:
[root@ST-K8S-01 data]# systemctl start keepalived && systemctl status keepalived
[root@ST-K8S-01 ~]# systemctl enable keepalived
如果采用第二种容器化方式部署,可以使用如下命令启动:
docker run --cap-add=NET_ADMIN --cap-add=NET_BROADCAST --cap-add=NET_RAW --net=host --name=keepalived --volume /etc/keepalived/keepalived.conf:/usr/local/etc/keepalived/keepalived.conf -d 10.2.55.8:5000/library/keepalived:2.0.20 --copy-service
查看keepalived master容器日志:
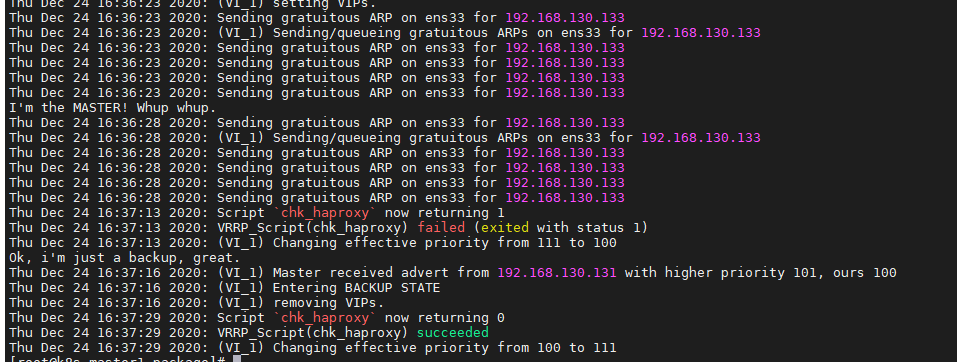
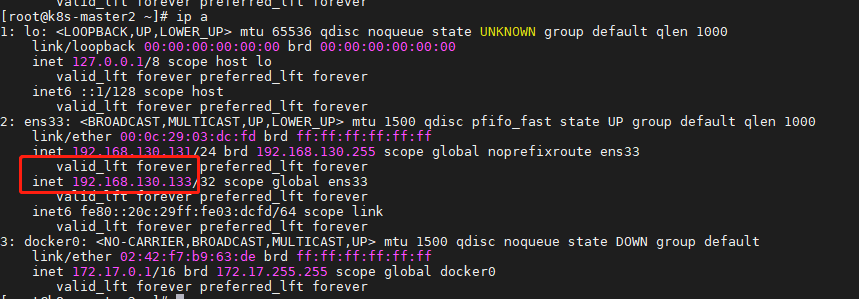
查看master vip:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号