
-系列目录-
大数据(三)大数据技术栈发展史
前两章,我们分析了大数据相关的概念和发展史,本节我们就讲一讲具体的大数据领域的常见技术栈发展史。对主流技术栈有一个初步的认知。
一、总览
大数据技术栈非常多估计大大小小多达上百种。但发展史、技术体系仍有迹可循。我们从数据采集、清洗、应用3大步骤来看,在每个步骤内部按照时序标识主流技术栈时间点。以此期望能给大家一个初步的映像。三大步骤如下:
- 数据采集:从数据源进行数据同步,大致分为:主动查询DB数据批量(离线)同步、基于DB log数据变更(实时)同步2大类。
- 数据清洗:标准的ETL数据清洗,大致分为:离线计算(批处理)、实时计算(流处理)2大类。
- 数据应用:OLAP在线数据分析、报表、数据大屏、大数据查询服务API。
分步骤整体技术栈如下图所示:

二、技术栈
2.1 数据集采
如上图,数据采集可以归纳为两大类:离线查询同步、实时变更同步。如下图所示:
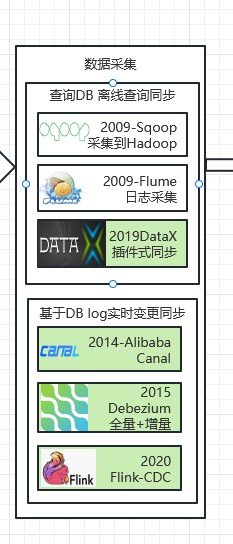
2.1.1 离线同步
离线同步常见技术栈有:Sqoop、Flume、DataX。
2.1.1.1 Sqoop-2009
2.1.1.2 Flume-2009
1)介绍
Apache Flume 是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具。也是Apache顶级项目。
2)同步原理

flume采集流模式进行数据实时采集。适用于日志文件实时采集,特定文件传输场景使用。
2.1.1.3 DataX-2019
1)介绍
DataX是阿里开源的,异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
2)同步原理

为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
数据库日志同步。适用于在异构数据库/文件系统之间高速交换数据,是主流的离线同步工具,推荐使用。
2.1.2 实时同步
2.1.2.1 Canal-2014
1)介绍
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。2014年,由Alibaba开源。
github:https://github.com/alibaba/canal,阿里巴巴 MySQL binlog 增量订阅&消费组件。
2)同步原理
数据库增量日志解析。仅适用于Mysql数据同步,适用场景局限性过大,无法作为通用技术栈。
2.1.2.2 Debezium-2015
1)介绍
RedHat(红帽公司) 开源的Debezium是一个将多种数据源实时变更数据捕获,形成数据流输出的开源工具。 它是一种CDC(Change Data Capture)工具,工作原理类似大家所熟知的 Canal, DataBus, Maxwell 等,是通过抽取数据库日志来获取变更的。
2)同步原理

Debezium的工作原理是利用数据库日志来捕获数据库更改事件,深度结合Kafka实现。
2.1.2.3 FlinkCDC-2020
1)介绍
FlinkCDC是Apache Flink的一组源连接器,使用更改数据捕获(CDC)从不同的数据库摄取更改。项目诞生于2020年,底层也是封装的Debezium。
github: https://github.com/ververica/flink-cdc-connectors
2)同步原理
同Debezium。
2.1.3 总结
常见开源CDC方案比较如下:

如上图,如果需要做全量+增量同步,FlinkCDC是一个不错的选择。(支持的下游生态更丰富、操作更简单Flink SQL)
2.2 数据清洗
数据清洗阶段是大数据的核心能力阶段,主要包含计算(离线计算、实时计算)+存储(分布式存储),下面我们就从这两个方面来看有哪些主流技术栈。

如上图所示,Google在2003-2006之间发布了3篇始祖级论文:2003分布式文件系统GFS、2004分布式计算框架MapReduce、2006NoSQL数据库系统BigTable。之后在2006年发布了大数据平台Hadoop,自此这只黄色的可爱小象,驰骋在大数据领域,所向披靡。
2.2.1 计算-离线计算(批计算)

离线计算领域Hadoop的MapReduce是始祖,有2个衍生技术栈:Pig和Hive。最后一个Spark相对Hadoop MapReduce性能上有极大提升。
2.2.1.1 Hadoop MapReduce-2006
1)介绍
Hadoop MapReduce是一个软件框架,可以轻松地编写应用程序,以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)。
2)原理
MapReduce 作业通常将输入数据集拆分为独立的块,这些任务由地图任务以完全并行的方式进行处理。框架对地图的输出进行排序,然后将其输入到reduce任务。2.2.1.2 Pig-2007
1)介绍
为了简化MapReduce开发的流程,Yahoo工程师发明了Pig,后捐给了Apache。只需编写Pig Latin脚本语言,系统自动转化成mapreduce执行。pig不是主流技术栈,不建议使用。
2)原理

Apache PIG提供一套高级语言平台,用于对结构化与非结构化数据集进行操作与分析。这种语言被称为Pig Latin,其属于一种脚本形式,可直接立足于PIG shell执行或者通过Pig Server进行触发。用户所创建的脚本会在初始阶段由Pig Latin处理引擎进行语义有效性解析,而后被转换为包含整体执行初始逻辑的定向非循环图(简称DAG)。
2.2.1.3 Hive-2007
1)介绍
Hive起源于FaceBook,是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
2)原理

如上图所示,Hive基本原理就是转换HQL语言为MapReduce任务来执行。hive 并非为联机事务处理而设计,hive 并不提供实时的查询和基于行级的数据更新操作。hive的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
2.2.1.4 Spark-2010
1)介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。简单来说,Spark是一个快速,通用,可扩展的分布式计算引擎。这里把Spark划归离线计算,是把Spark Streaming排除在外的。Spark是离线计算(批处理)领域的主流技术栈。
2)原理

如上图所示,Spark有三个主要特性:RDD的编程模型更简单,DAG切分的多阶段计算过程更快速,使用内存存储中间计算结果更高效。这三个特性使得Spark相对Hadoop MapReduce可以有更快的执行速度,以及更简单的编程实现。这里具体的细节原理就不展开细讲。
2.2.2 计算-实时计算(流计算)

流式计算领域,有3个典型技术栈:Storm、Spark Streaming、Flink,其中Spark Streaming是“微批拟流”,不能算是真流。两种流式处理说明如下:
1)Native Streaming原生流:指每个传入的记录一到达就会被处理,而不必等待其他记录。

2)Micro-batching微批拟流: 这意味着每隔几秒就会将传入记录一起批处理,然后在一个小批量中处理,延迟几秒钟。

2.2.2.1 Storm-2011
1)介绍
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm最早于2011年诞生于Twitter,2013年进入Apache社区进行孵化, 2014年9月,晋级成为Apache顶级项目。早期Storm用于实时计算,Hadoop用于离线计算。现阶段已不推荐使用。
2)原理
在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology),它的结构和Mapreduce任务类似,通过自定定义Spout(数据输入处理模块)和Bolt(输出处理模块)逻辑,以及自定义Bolt之间的拓扑依赖关系,完成整个实时事件流的处理逻辑搭建。Topology(拓扑)是一个是由 Spouts 和 Bolts 通过 Stream 连接起来的有向无环图。Topology将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。Topology拓扑结构如下图所示:

Storm采用主从架构。nimbus是集群的Master,负责集群管理、任务分配等。supervisor是Slave,是真正完成计算的地方,每个supervisor启动多个worker进程,每个worker上运行多个task,而task就是spout或者bolt。supervisor和nimbus通过ZooKeeper完成任务分配、心跳检测等操作。如下图所示:

2.2.2.2 Spark Streaming-2013
1)介绍
Spark是Hadoop的批处理(MapReduce)实际继承者。为了应对流式处理场景,2013年Spark 2.0推出了Spark Streaming。但由于不是原生流处理技术栈,存在时延,加之高级功能不如Flink,已不是主流技术栈。
2)原理
Spark Streaming是在 Spark Core API基础上扩展出来的,以微批模式实现的近实时计算框架,它认为流是批的特例,将输入数据切分成一个个小的切片,利用Spark引擎作为一个个小的batch数据来处理,最终输出切片流,以此实现近似实时计算。如下图所示:

2.2.2.3 Flink-2014
1)介绍
Apache Flink是一个框架和分布式处理引擎,用于无界和有界数据流的有状态计算。Flink创造性地统一了流处理和批处理,作为流处理看待时输入数据流是无界的,而批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。2015年发布了第一个版本,目前Flink已成为流处理领域的实际标准,且大有一统某些场景的批流一体方案的计算引擎。

同时支持有界、无界:

2)原理
Flink 架构也遵循Master-Slave架构设计原则,JobManager为Master节点,TaskManager为Slave节点。架构图如下:

2.2.3 分布式存储
相比于计算领域的百花齐放,分布式存储技术栈就显得独树一帜了。最早的Hadoop HDFS分布式文件系统,以及基于HDFS衍生出来的Hbase。

1)介绍
HBase是一个分布式的、面向列的开源数据库。建立在 HDFS 之上。Hbase的名字的来源是 Hadoop database。HBase 的计算和存储能力取决于 Hadoop 集群。它介于NoSql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过Hive支持来实现多表join等复杂操作)。
HBase中表的特点:
- 大:一个表可以有上十亿行,上百万列。
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
2)原理
hbase的系统架构如下:

HBase由三种类型的服务器以主从模式构成:
- Region Server:负责数据的读写服务,用户通过与Region server交互来实现对数据的访问。
- HBase HMaster:负责Region的分配及数据库的创建和删除等操作。
- ZooKeeper:负责维护集群的状态(某台服务器是否在线,服务器之间数据的同步操作及master的选举等)。
HBase 表数据模型如下:

与nosql数据库一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
- 通过单个row key访问
- 通过row key的range
- 全表扫描
2.3 数据应用
本节聚焦大数据OLAP,讲解主流技术栈。OLAP技术发展至今,已经是”百花齐放“之势,可简单分三类:
- ROLAP(Relational OLAP,关系型OLAP):使用关系数据库存储管理数据仓库,以关系表存储多维数据,有较强的可伸缩性。其中维数据存储在维表中,而事实数据和维 ID 则 存储在事实表中,维表和事实表通过主外键关联。
- MOLAP(Multidimensional OLAP,多维型OLAP):MOLAP 支持数据的多维视图,采用多维数据组存储数据,它把维映射到多维数组的下标或下标的范围,而事实数据存储在数组单元中, 从而实现了多维视图到数组的映射,形成了立方体的结构。
- HOLAP(Hybrid OLAO,混合型OLAP): 混合存储,如低层是关系型的,高层是多维矩阵型的,灵活性强。将明细数据保留在关系型数据库的事实表中,聚合后数据保存在Cube中,查询效率比 ROLAP 高,但性能低于 MOLAP。

2.3.1 ROLAP
Rolap(Relational OLAP),即关系型OLAP。Rolap基于关系型数据库,它的OLAP引擎就是将用户的OLAP操作,如上钻下钻过滤合并等,转换成SQL语句提交到数据库中执行,并且提供聚集导航功能,根据用户操作的维度和度量将SQL查询定位到最粗粒度的事实表上去。分为两大类:1、MPP数据库 2、SQL on Hadoop。

2.3.1.1 MPP数据库
MPPDB即基于MPP架构(Massive Parallel Processing,海量并行处理)的数据库。典型技术栈有:Doris/StarRocks、ClickHouse、GreenPlum。
Doris-2018
Apache Doris是由百度开源的一款MPP数据库,支持标准的SQL语言,兼容MYSQL协议,可直接对接主流BI系统。2018年捐给apache,后在2022年成为Apache 顶级项目。使用简单、生态完善、运维方便、稳定可靠、国产之光----一站式开箱即用,无脑推荐使用。Doris定位如下图:

ClickHouse-2016
ClickHouse是俄罗斯的Yandex于2016年开源的一个用于联机分析(OLAP)的列式数据库管理系统。性能极高,运维难度较大,全球风靡---推荐使用。看官网介绍的定位支持任何数据源的快速查询,如下图:

GreenPlum
2.3.1.2 SQL on Hadoop
2.3.1.2.1 基于MPP架构
为了提高SQL on Hadoop的性能,第一个重要技术流派的就是MPP(Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。 其中的代表就是 Presto & Impala。
1)Presto
Presto是 Facebook 推出分布式SQL交互式查询引擎,完全基于内存的并行计算,这也是为啥Presto比Hive快的原因。Presto架构图如下:

2)Impala
Impala是 Cloudera 在受到 Google 的 Dremel 启发下开发的实时交互SQL大数据查询工具,其也是基于内存的并行计算框架,缺点是仅适用于 HDFS/Hive 系统的查询。

3)其它
- Drill: Drill 是2012年,MapR 公司开源的一个低延迟的大数据集的分布式SQL查询引擎,是谷歌Dremel的开源实现。它支持对本地文件、HDFS、HBASE等数据进行数据查询。它与同是源自 Dremel 的 Impala 比较类似。
- HAWQ:HAWQ(Hadoop With Query) 是 Pivotal 公司开源的一个 Hadoop 原生大规模并行SQL分析引擎,基于 GreenPlum 实现,采用主从改进MPP架构,将MPP与批处理系统有效的结合。
2.3.1.2.2 通用型
Blink诞生于2015年,在Alibaba内部使用,2019年开源并于Flink1.9.0版本。Flink SQL 可以做到 API 层的流与批统一,这是一个极大的进步,让用户关注核心API即可而不用关注底层细节。
2.3.2 MOLAP
2.3.2.1 Kylin

- 优点:快。
- 缺点:只读分析引擎,不支持insert,update,delete等SQL操作;cube建模有成本。
2.3.2.2 Druid
Druid是由广告公司 MetaMarkets 于2012年开源的实时大数据分析引擎。Druid 作为MOLAP引擎,也是对数据进行预聚合。只不过预聚合的方式与Kylin不同,Kylin是Cube化,Druid的预聚合方式只是全维度进行Group-by,相当于是Kylin Cube 的 base cuboid。
- 优点:快、不需要专业建模能力。
- 缺点:只适合聚合查询和报告查询,且速度没有Kylin快;
如果你觉得本文对你有点帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号