MongoDB权威指南三四章学习体会
前言#
最近在学习Mongodb权威指南,其中有些内容,还是比较难理解,和大家分享一下。
1、数组update#
update用于更新文档,更新操作分成两阶段完成,首先找到目标文档,然后修改目标文档。
涉及到数组操作的operator有以下四个:
示例集合 students :
{
"name": "Tom",
"gender": "male",
"class_id": "300",
}
push:push向数组中添加一个元素,一次添加多个元素需要配合each
(1)向集合中加入字段选修课 :
1.db.students.update({"name":"Tom"}, {$push : {"optional lesson": "math"}})
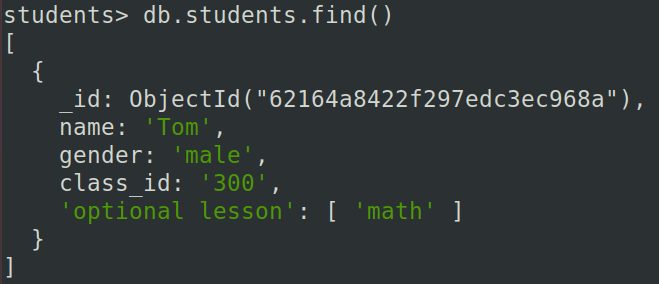
(2)向学生"Tom"的"optional lesson"字段加入多个元素:
db.students.update({"name":"Tom"}, {$push : {"optional lesson": {$each: ["math", "Chinese", "Spanish"]}}})
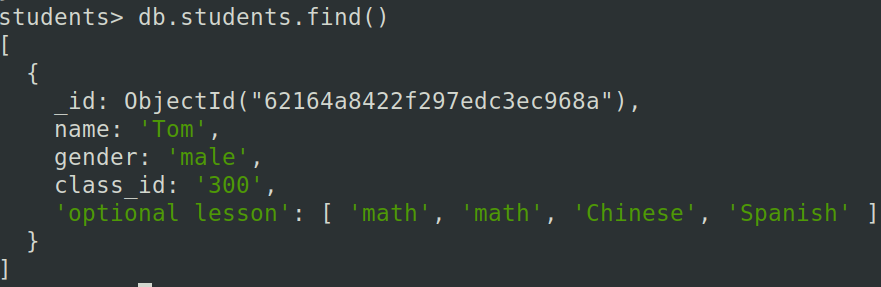
值得注意的是,push操作是允许添加重复值的,因此上面的语句如下图所示:
使用addToSet会将待插入元素和文档中的数组元素进行比较,实现去重添加的效果。
(3) 向学生"Tom"的"optional lesson"字段加入多个元素,并去重:
db.students.update({"name":"Tom"}, {$addToSet : {"optional lesson": {$each: ["math", "Chinese", "Spanish"]}}})
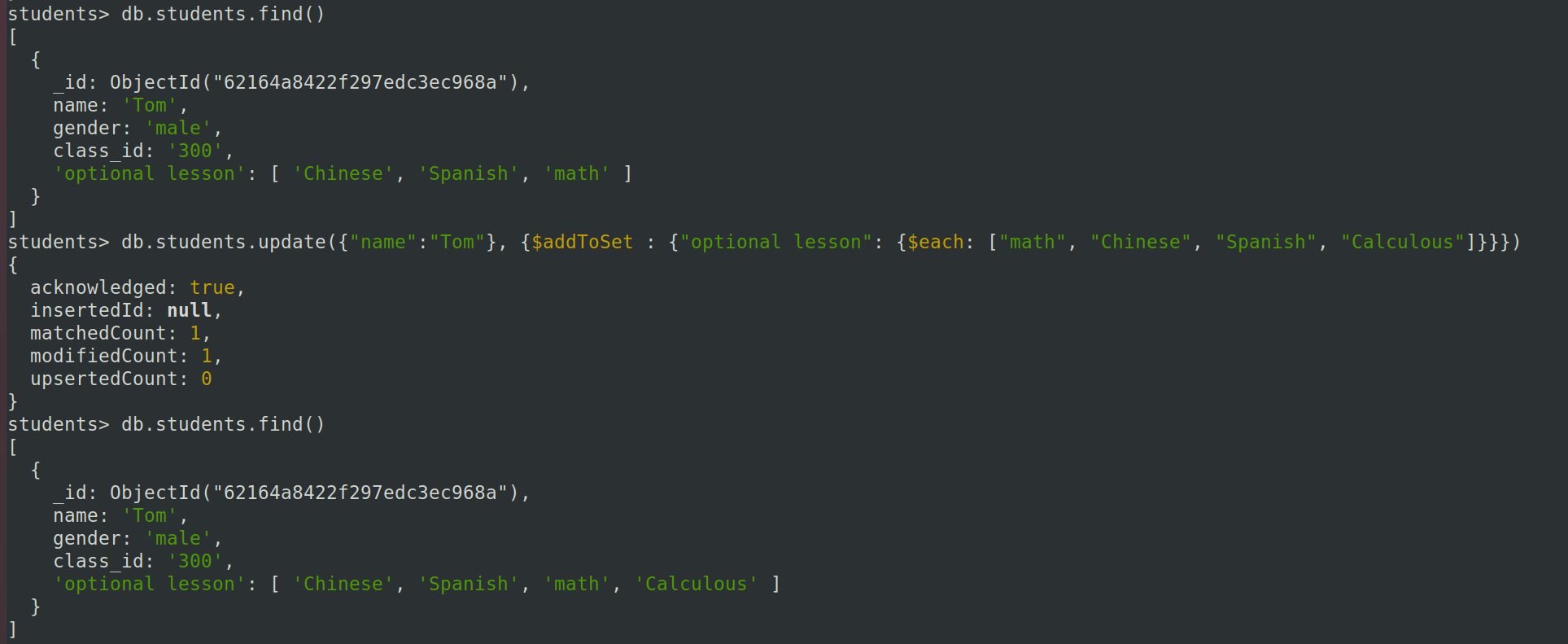
可以看到这样,就达到了去重的效果
2、upsert#
在使用update的时候,可能存在没有找到指定文档的情况,如果在这种情况中,我们想让Mongodb创建出一个默认的文档的话就可以使用upsert。
db.test.update({"count": 25}, {$inc: {"count": 3}}, true)
3、修改器速度#
这一节主要是讲了填充因子和空间分配大小在文档更新时的作用。
每次执行更新操作,都有可能增大文档的大小,如果该文档的前后连续的物理位置都存储有其他文档,那么当我们写入该文档的时候就会把它移动到集合的末尾。
每次执行这样的移动操作的时候,mongodb都会增加集合的填充因子(padding factor)。下一次执行插入操作时,给新文档分配的空间: alloc_space =
actual_space * padding_factor。通过设置padding factor减少了文档搬移的可能性,从而减少了硬盘IO的发生。同时这里也是局部性原理的体现,如果频繁发生
文档的搬移说明当前文档的更新操作比较频繁,后续插入的新文档大概率也会出现搬移的操作。如下图,{b:2}的更新操作导致文档被搬移到集合末尾,从而导致
填充因子增加(>1)。
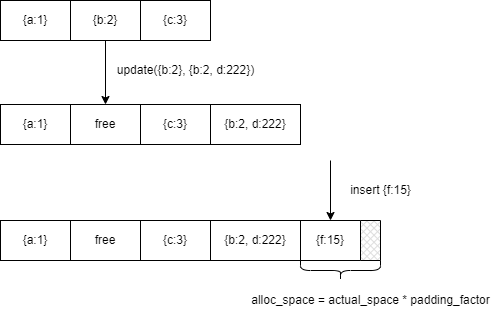
从前文可以看到每次发生文档的搬移操作之后,在原位置就会出现一段空闲空间(free space)。如果没有特殊的分配策略的话,这些空闲空间的大小就是原文档的
大小,意味着这些空间的大小是相当随机的,也就意味着新插入的文档大概率会无法利用这些空闲的空间,这些虽然空闲但是没有办法被利用的空间被称作碎片。
为了减少空间碎片,我们可以采用usePowerOf2Sizes。
db.runCommand({"collMod" : collectionName, "usePowerOf2Sizes": true)
使用该选项之后,每次分配空间是2的幂次。这样留下的空闲空间都会是fixed-size(固定空间),而不是随机大小。从而减少了碎片的产生。
4、数组find#
$all
all用来匹配数组中的多个值。假设我们有一个如下的文档:
{
_id: ObjectId("621b3d2a7c51445f6727e045"),
fruits: [ 'apple', 'banana', 'pineapple', 'orange' ]
}
可以使用如下的语句去搜索指定文档:
db.test.find({"fruits": {$all: ["apple", "banana"]}})
$slice
find的第二个参数可以指定返回的键---find({}, {"return_key": 1})。使用slice语句替换1,可以指定需要返回的数组元素。
test> db.test.find()
[
{
_id: ObjectId("621b3d2a7c51445f6727e045"),
fruits: [ 'apple', 'banana', 'pineapple', 'orange' ]
}
]
test> db.test.find({}, {"fruits": {$slice: 1}})
[ { _id: ObjectId("621b3d2a7c51445f6727e045"), fruits: [ 'apple' ] } ]
返回一个匹配的元素
使用$操作符可以返回第一个满足查询要求的数组元素
db.restaurants.find({"grades.grade": "A"}, {"grades.$": 1})
$elemMatch
使用elemMatch之后,查询条件必须满足每一个数组元素,才会返回。如下图所示,在第一个find中使用了elemMatch返回的结果中是每个元素都满足
80<= elm <=85。而第二个find,由于88是满足条件的,所以也返回了这个数组。
scores> db.scores.find()
[
{ _id: 1, results: [ 82, 85, 88 ] },
{ _id: 2, results: [ 75, 88, 89 ] }
]
scores> db.scores.find( { results: { $elemMatch: { $gte: 80, $lt: 85 } } })
[ { _id: 1, results: [ 82, 85, 88 ] } ]
scores> db.scores.find( { results: {$gte: 80, $lt: 85 } } )
[
{ _id: 1, results: [ 82, 85, 88 ] },
{ _id: 2, results: [ 75, 88, 89 ] }
]
作者:dennis-wong
出处:https://www.cnblogs.com/dennis-wong/p/15943787.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App