针对Raft的一些分享(Figure 8和Figure 7)
1、背景
完成6.824的lab2b,对于Raft有了一定的理解,现在把读论文过程中遇到的一些问题发出来和大家分享下。
2、一些问题
(1)什么情况下会出现votedFor = candidateId
网络环境的原因有概率会导致一个candidate的request vote请求在同一个任期内重复发送,而且重复
发送的两个包在发送链路和接受链路的速率不同,如果单纯的判断votedFor==-1,会导致这两个包的结果不同。

(2)apply到复制状态机是什么操作?
复制状态机是Raft抽象出来的一个一致性服务,每个Raft节点都会存在一个复制状态机,客户端会从Leader的复制状态机中读取命令(Command),6.824中其实体是一个键值数据库。每隔一段时间,节点会把已经committed的日志条目apply到状态机中,并且保证每个节点提交的顺序是一致的。
(3)对committed的定义是什么?
严格意义上说,一个日志条目被复制到大多数节点上,并且leader的commitIndex大于等于日志条目的下标,那么这么一条日志就是committed。
Raft保证每个任期的Leader都会包含之前任期的、已经committed的日志条目。
(3)对论文里两个图示的解读
Figure 7
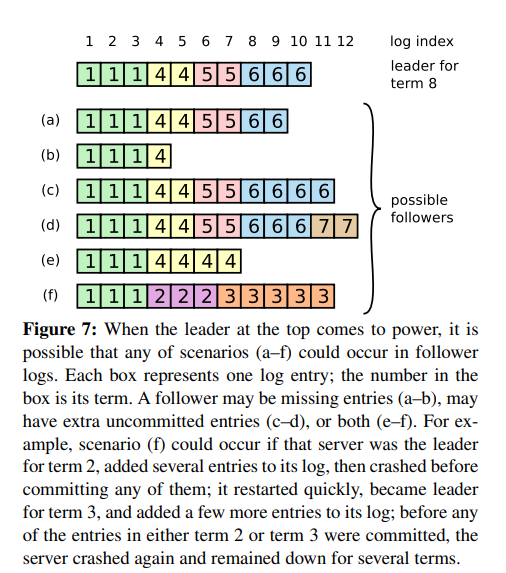
图示解释了leader崩溃可能导致follower出现的日志不一致的情况,主要谈下d,d表示的是follower可能会出现多个没有提交的日志条目。
图中的新Leader的任期是8,下个复制的条目下标是11。follower在11和12上添加了两条任期7的日志。出现这种情况的一种可能是,
在复制完下标10的entry之后,任期6的leader S1宕机,选举超时到达后,S2重新选举为任期7的leader。之后leader发送心跳包,将S3的任期置为7,
然后开始在下标11、12复制日志。但是AE RPC还没有发送出去S2就宕机。同一时刻任期6的leader S1上线,之后S3的选举超时到了,开始选举流程,同一时刻
S2上线,之后S3收到S1的投票,当选为leader,就是图D的情况。
Figure 8

使用图示作者是想引出Raft的另一个限制,leader不能提交前一个任期的日志。用Figure 8来举例,a中S1在少数节点上复制了一条位于index2的日志,然后宕机,b中S5当选为任期3的leader,并且在index2写入了一条日志,还没有开始复制到其他节点,S5就宕机。
图c中作者假设了一种情况,leader可以提交之前任期的日志,这样S1重新成为任期4的leader,并且继续复制index2的日志(忽略index3的entry,对于解释这个限制没用,我就是被误导了),成功的把日志复制到大多数节点。
图d中S1宕机,并且S5收到S2、S3、S4的投票,当选为任期4的leader,同样开始继续复制之前任期---任期3的位于下标2的日志,导致index2的任期2的已经被提交的日志覆盖掉。根据这个例子,作者证明了即使leader发现自己日志内存在一个已经被复制到大多数节点的entry,也不能立即就判断这个日志是已经提交的。并且为了防止图d这种情况的发生,Raft中限制了leader只能主动去提交自己任期的日志,对于之前任期的日志,类似C图中index2的entry,只能通过复制当前任期的日志去被动的复制到其他节点---即figure2中对于rollback操作的描述,见下图。

图e就是对比图d和图e,如果在任期4,S1只提交index3的entry,就可以保证S5不会当选为leader(见figure2对当选的限制)。
在Raft论文客户端交互一章,作者提到为了保证只读操作能够读取到最新的提交的entry。在当选为leader后,节点可以提交一条no-op日志(只包含下标和任期,没有内容的日志),从而间接触发一次rollback保证leader中的最后一条日志一定是提交过的。
3、结论
本文中我对在做6.824实验和阅读raft论文中的一些问题和大家进行了分享,过程中我对raft论文也有了新的理解。
参考
https://stackoverflow.com/questions/60397950/confusion-about-raft-algorithm
https://stackoverflow.com/questions/57212795/why-raft-should-grant-vote-when-votefor-is-candidateid
Raft原文

