alloc_pages的实现浅析
alloc_pages的使用
struct page *alloc_pages(gft_t gfp, unsigned int order)
alloc_pages定义于 inux/gfp.h 中. 该函数用于分配2^order个 连续 的物理页. 分配失败返回NULL。
alloc_pages的调用链
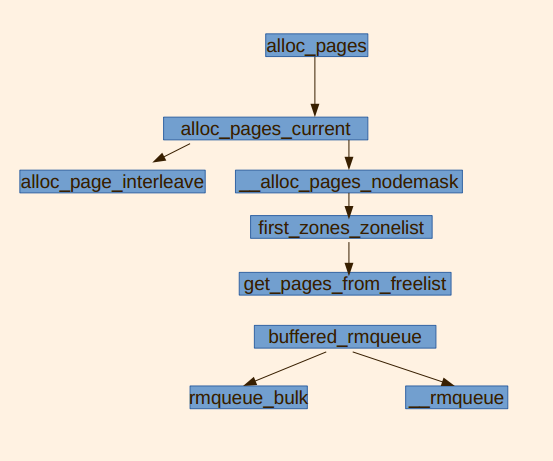
主功能函数
static struct page *
get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask, unsigned int order, struct zonelist *zonelist, int high_zoneidx, int alloc_flags, struct zone *preferred_zone, int migratetype)
static inline
struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, int order, gfp_t gfp_flags,
int migratetype)
static struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
static int rmqueue_bulk(struct zone *zone, unsigned int order,
unsigned long count, struct list_head *list,
int migratetype, int cold)
get_page_from_freelist() 遍历整个 zonelist, 如果找到一个watermark满足要求的zone, 就在这个zone上调用 buffered_rmqueue.
struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, int order, gfp_t gfp_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
//是否使用cold cache
int cold = !!(gfp_flags & __GFP_COLD);
again:
//如果要请求页的数量为1
if (likely(order == 0)) {
struct per_cpu_pages *pcp;
struct list_head *list;
//把当前中断状态保存到flags中,然后禁用当前处理器上的中断发送。flags 被直接传递, 而不是通过指针来传递。
local_irq_save(flags);
//获取本地CPU上的per_cpu_pages结构
pcp = &this_cpu_ptr(zone->pageset)->pcp;
//获取高速缓冲中页框描述符链表的头指针
list = &pcp->lists[migratetype];
//如果链表为空,则向高速缓冲中添加页框
if (list_empty(list)) {
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, list,
migratetype, cold);
if (unlikely(list_empty(list)))
goto failed;
}
if (cold)
// 如果从cold高速缓存中请求页
page = list_entry(list->prev, struct page, lru);
else
//
page = list_entry(list->next, struct page, lru);
//从LRU链表中删除该页
list_del(&page->lru);
//缓存中的页框数减1
pcp->count--;
} else {
//保存当前中断状态到flags, 并请求zonelock
spin_lock_irqsave(&zone->lock, flags);
page = __rmqueue(zone, order, migratetype);
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_page_state(zone, NR_FREE_PAGES, -(1 << order));
}
__count_zone_vm_events(PGALLOC, zone, 1 << order);
zone_statistics(preferred_zone, zone);
local_irq_restore(flags);
VM_BUG_ON(bad_range(zone, page));
if (prep_new_page(page, order, gfp_flags))
goto again;
return page;
failed:
local_irq_restore(flags);
return NULL;
}
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area * area;
struct page *page;
//从指定的order开始,寻找一个指向非空free list的free area
//如果指定的order对应的free area满足要求,则从中返回一个页块
//否则使用expand进一步处理
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
//从指定内存区间中获取的起始地址
area = &(zone->free_area[current_order]);
//判断该空闲区间的指定迁移类型的空闲列表是否为空
//为空查找下一个块
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,
struct page, lru);
//将该页从LRU链表中删除
list_del(&page->lru);
rmv_page_order(page);
//将内存区间的可用页面数减1
area->nr_free--;
//返回的页块大于请求的页块,将页块的剩余页框分配到其他order的free area
expand(zone, page, order, current_order, area, migratetype);
return page;
}
return NULL;
}
假设我们请求分配一个order=2,大小为4的页块,order的最大值是5。 前4个free area都为空。我们从order=5的area得到一个大小为32的页块。所以我们order5的页块分配到order=3和order=4的页块。这时,order2 order3 order4分别得到了大小为4,8和16的页块。
就这样一个32大小的页块被分给了low以上的free area。
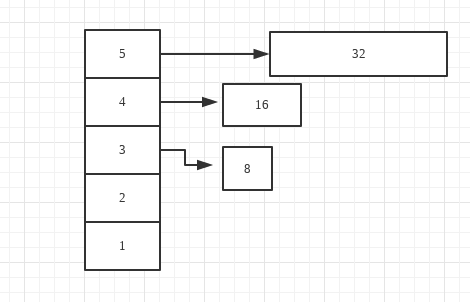
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
//high为实际分配到的页块的order,此处得到页块的大小
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
//低一级页块的大小为上一级页块大小的1/2
size >>= 1;
VM_BUG_ON(bad_range(zone, &page[size]));
list_add(&page[size].lru, &area->free_list[migratetype]);
//area的可用页块数加一
area->nr_free++;
set_page_order(&page[size], high);
}
}

