
第一次个人编程作业
忘记写自己的GitHub了 这里补一下:
https://github.com/comesomemusic/comesomemusic.git
第一次个人编程作业
软件工程第一次个人编程作业
| 软件工程 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812/ |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812/homework/11155 |
| 作业目标 | 论文查重(python实现) |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 8 |
| Development | 开发 | 240 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | · 生成设计文档 | 10 | 15 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 10 |
| · Design | · 具体设计 | 30 | 50 |
| · Coding | · 具体编码 | 200 | 240 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 30 | 20 |
| · Test Repor | · 测试报告 | 20 | 15 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| · 合计 | 755 | 770 |
计算模块接口的设计与实现过程
根据需求:校验重复。得出解决方案就是拆分和计算重复率。
首先要做的就是把文章拆分成词语,这里使用jieba拆分。拆分完成之后放入一个字典。然后就是采取相应的算法计算相似度,我采用Jaccard index计算相似度,即两个词语集合求交除以两个词语集合的并。
算法的关键就是用jieba拆分并选择Jaccard index计算。(因为网上有很多不同的算法,并且抄袭的标准个人也不一样,最终选择这个比较朴实无华,应该和各类标准都比较接近)
计算模块接口部分的性能改进。
总体比较简单,所以改进也不大,主要事件花在jieba的函数上。
性能分析图
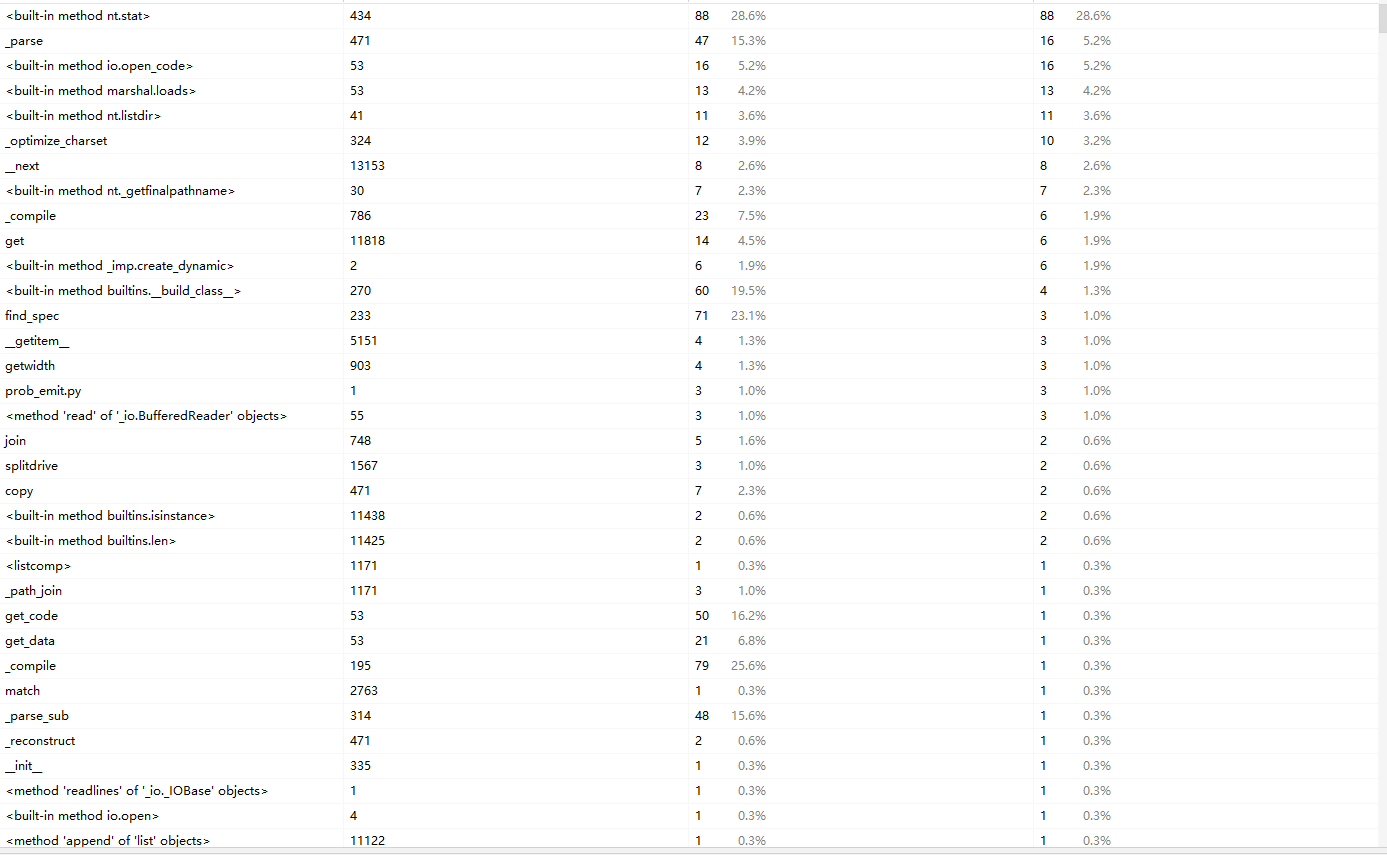
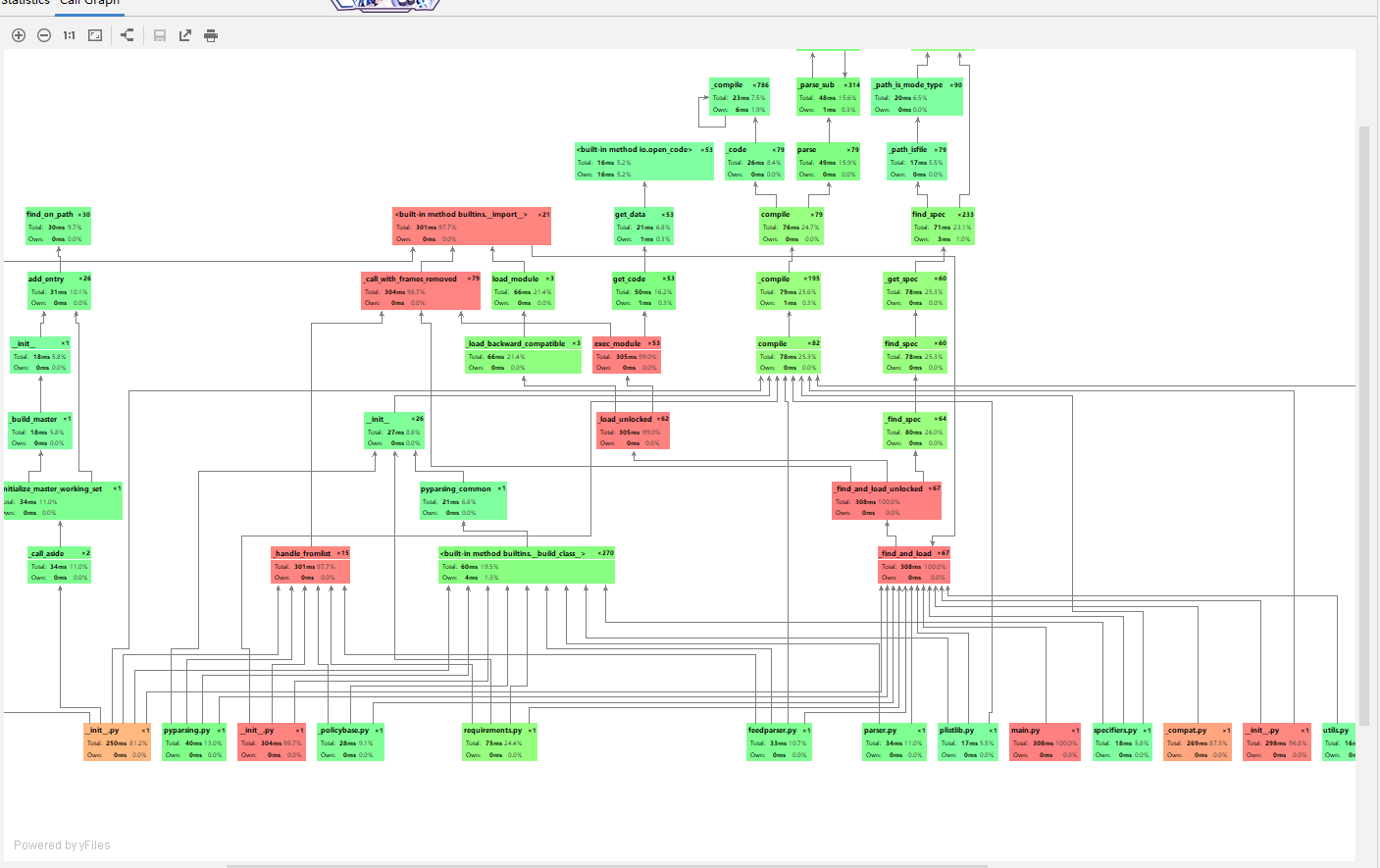
单元测试结果
测试代码:
coding:utf-8
def CalEachWordAp(words): # 文本中记录各词语出现次数r
d = {}
for word in words:
d[word] = 0
for word in words:
d[word] += 1
return d
word = ['一位', '真正', '的', '作家', '永远', '只', '为', '内心', '写作', ',', '只有', '内心', '才', '会', '真实', '地', '告诉', '他', ',', '他', '的', '自私', '、', '他', '的', '高尚', '是', '多么', '突出', '。', '内心', '让', '他', '真实', '地', '了解', '自己', ',', '一旦', '了解', '了', '自己', '也', '就', '了解', '了', '世界', '。', '很多年', '前', '我', '就', '明白', '了', '这个', '原则', ',', '可是', '要', '捍卫', '这个', '原则', '必须', '付出', '艰辛', '的', '劳动', '和', '长', '时期', '的', '痛苦', ',', '因为', '内心', '并非', '时时刻刻', '都', '是', '敞开', '的', ',', '它', '更', '多', '的', '时候', '倒', '是', '封闭', '起来', ',', '于是', '只有', '写作', ',', '不停', '地', '写作', '才能', '使', '内心', '敞开', ',', '才能', '使', '自己', '置身于', '发现', '之中', ',', '就', '像', '日出', '的', '光芒', '照亮', '了', '黑暗', ',', '灵感', '这时候', '才']
dt=CalEachWordAp(word)
print(dt)

测试覆盖率
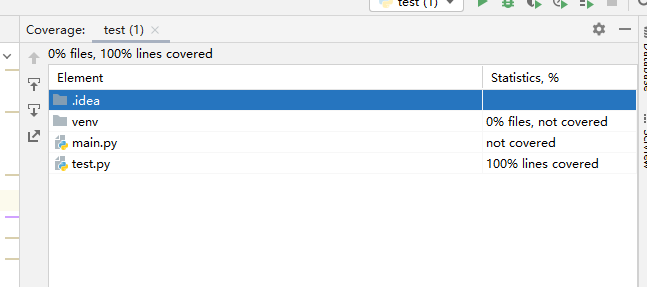
计算模块部分异常处理说明
1.文件读写异常处理
try:
orig_text=open(sys.argv[1], 'r', encoding='utf-8')
tested_text=open(sys.argv[2],'r',encoding='utf-8')
result=open(sys.argv[3],'w',encoding='utf-8')
or_txt=orig_text.read()
te_txt=tested_text.read()
words1=jieba.lcut(or_txt)
words2=jieba.lcut(te_txt)
except Exception as e:
print(e)

2除零异常
try:
J=n/m
except Exception as e:
print(e)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号