JVM内存结构划分
栈
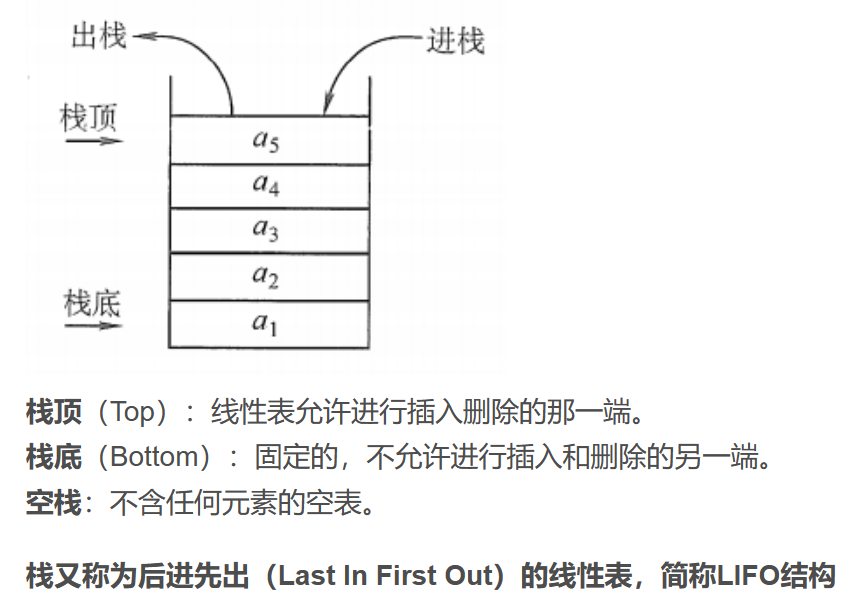
"栈"(Stack)是一种遵循后进先出(Last In First Out,LIFO)原则的抽象数据类型。以下是栈的一些基本特点和操作:
特点:
- LIFO 原则:最后加入栈的元素将是第一个被移除的元素。
- 动态大小:栈的大小可以根据需要动态变化。
- 线性结构:元素存储在栈中的方式是线性的,但只能从一端(栈顶)访问。
基本操作:
- Push:将一个元素添加到栈顶。
- Pop:从栈顶移除元素,并返回被移除的元素。
- Peek/Top:查看栈顶元素,但不移除它。
- IsEmpty:检查栈是否为空。
- Size:获取栈中元素的数量。
示例:
在许多编程语言中,可以使用数组或链表来实现栈。以下是使用数组实现栈的简单示例:
public class Stack<T> {
private T[] stack;
private int top;
private int capacity;
public Stack(int capacity) {
this.capacity = capacity;
this.stack = (T[]) new Object[capacity];
this.top = -1;
}
public void push(T element) {
if (top >= capacity - 1) {
throw new StackOverflowError("Stack is full");
}
stack[++top] = element;
}
public T pop() {
if (isEmpty()) {
throw new IllegalStateException("Stack is empty");
}
return stack[top--];
}
public T peek() {
if (isEmpty()) {
throw new IllegalStateException("Stack is empty");
}
return stack[top];
}
public boolean isEmpty() {
return top == -1;
}
public int size() {
return top + 1;
}
}
代码解释:
Stack类是一个泛型类,可以存储任意类型的元素。- 构造方法接受一个容量参数,初始化栈的大小。
push方法将元素添加到栈顶,如果栈已满,则抛出异常。pop方法从栈顶移除元素并返回它,如果栈为空,则抛出异常。peek方法返回栈顶元素但不移除它,如果栈为空,则抛出异常。isEmpty方法检查栈是否为空。size方法返回栈中元素的数量。
应用场景:
- 函数调用:许多编程语言使用栈来跟踪函数调用,存储局部变量和返回地址。
- 表达式求值:用于评估和简化算术表达式,如后缀表达式(逆波兰表示法)。
- 回溯算法:如迷宫求解、八皇后问题等。
- 撤销操作:在编辑器中实现撤销(Undo)功能。
- 深度优先搜索(DFS):在图和树的遍历中使用。
堆
“堆”(Heap)有两个不同的概念,一个是指数据结构,另一个是指内存管理中的堆。下面分别解释这两个概念:
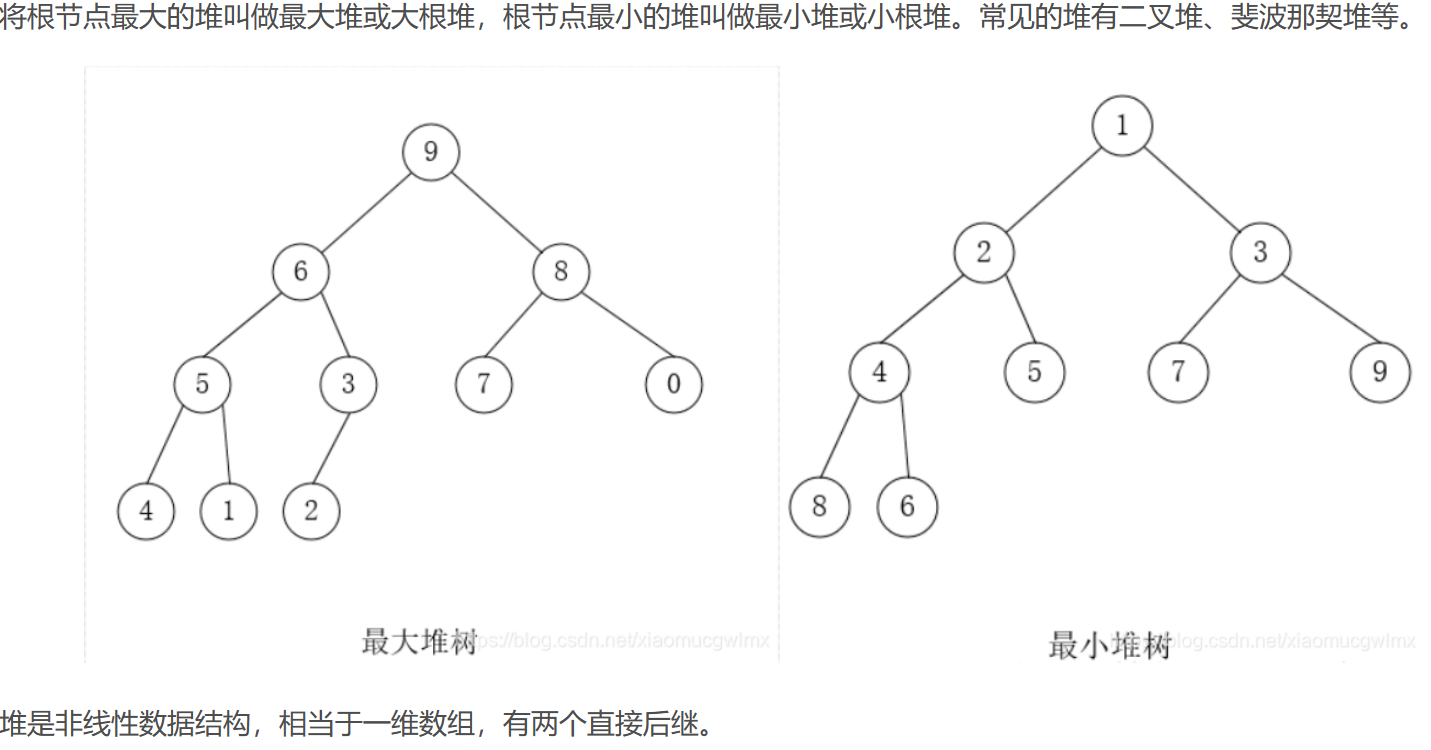
1. 堆(数据结构)
堆是一种特殊的树状数据结构,通常用于实现优先队列。它满足以下特性:
- 结构特性:堆通常是一棵完全二叉树,这意味着除了最后一层外,其他每层都被完全填满,并且最后一层的节点尽可能地集中在左侧。
- 堆序:堆中的每一个节点都必须满足特定的顺序要求。在最小堆中,父节点的值总是小于或等于其子节点的值;在最大堆中,父节点的值总是大于或等于其子节点的值。
基本操作:
- Insert(添加):将新元素添加到堆中,并维持堆的性质。
- Extract(提取):移除并返回堆中的根节点(最小堆中是最小元素,最大堆中是最大元素),然后重新调整堆以维持其性质。
- Peek/Top:返回堆顶元素,但不移除它,对于最小堆是最小元素,对于最大堆是最大元素。
- Decrease Key(降低关键字):将堆中某个元素的值降低,并重新调整堆以维持堆的性质。
- Increase Key(提高关键字):将堆中某个元素的值提高,如果违反了堆的性质,则需要进行调整。
应用场景:
- 优先队列:堆是实现优先队列的理想数据结构,允许快速访问最高或最低优先级的元素。
- 排序算法:堆排序算法使用堆数据结构对数组进行排序。
2. 堆(内存管理)
在计算机内存管理中,堆是用于动态内存分配的内存区域。以下是它的一些关键特点:
- 动态分配:堆用于分配在运行时才知道大小的内存块。
- 碎片化:由于不同大小的内存块被分配和释放,堆内存可能会变得碎片化。
- 垃圾回收:在有垃圾回收机制的语言(如Java、C#)中,堆内存由垃圾收集器定期清理,回收不再使用的对象所占用的内存。
- 性能开销:分配和释放堆内存通常比栈内存慢,因为可能涉及内存管理的额外开销,如垃圾回收。
应用场景:
- 动态内存分配:在程序运行期间,为对象分配内存。
- 垃圾回收:自动管理内存的生命周期,防止内存泄漏。
示例代码(堆数据结构):
import java.util.PriorityQueue;
public class HeapExample {
public static void main(String[] args) {
// 创建一个最小堆的优先队列
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 添加元素到堆中
minHeap.add(20);
minHeap.add(10);
minHeap.add(15);
// 提取堆顶元素
while (!minHeap.isEmpty()) {
System.out.println(minHeap.poll()); // 将按最小堆的顺序输出元素
}
}
}
PriorityQueue 被用来创建一个最小堆,元素按照升序被添加和提取。这个特性使得 PriorityQueue 成为实现堆排序和优先队列的理想选择。
