
redis数据存储的细节
redis是一个K-V NoSql非关系型数据库,redis有物种数据类型,分别是String,Hash,list,set,zset;这五种类型都是针对K-V中的V设计的。
1.总体介绍:关于redis数据存储的细节,设计到内存分配器(如jemalloc)、简单动态字符串(SDS)、五种对象类型的内部编码、redisObject。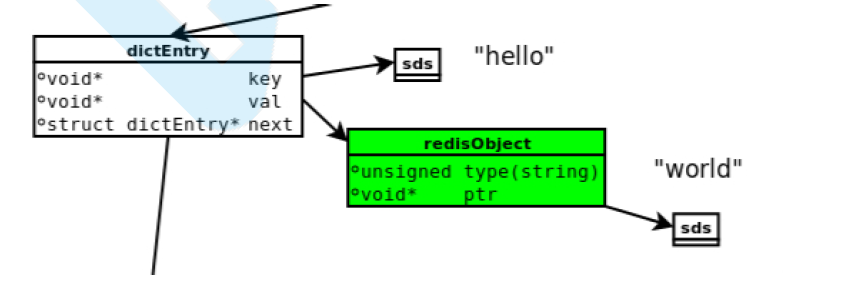
1)、dictEntry:redis时Key-Value数据库,因此每一个键值对都会有一个dictEnry,里面存储了指向key和value的指针和只想下一个dictEntry的指针next。
2)、key:图中右上角可见,key并不是一个直接以字符串存储的,而是存储在SDS结构中
3)、redisObject:value既不是直接以字符串存储,也不象key一样直接存储在SDS中,而是存储在redisObject中,实际上,不论value时5种类型的哪一种,都会通过redisObject来存储,redisObject中的type字段指明了value的类型,ptr字段 则只想对象所在的地址,除了这两个地段外还有其他字段
4)、jemalloc:无论时dictEntry对象,还是redisObject、SDS对象,都需要内存分配器(如jemalloc)分配内存来进行存储 。以dictEntry为例,有三个指针组成,在64为机器上占24字节,jemalloc会为他分配32个字节大小的内存单元。
2.jemalloc:redis在编译时便会指定内存分配器,内存分配器可以是libc、jemalloc或者tcmalloc,默认时jemalloc。
jemalloc作为redis的默认内存分配器,在减少内存碎片方面做得相对比较好。jemalloc在64位操作系统上将内存划分为小、大、巨大三个范围;每个范围内又被划分为许多小的内存单位,当redis村存储数据时,会选择大小最合适的内存进行存储,
3.redisObject
redisObject支持了redis中对象的类型、内部编码、内存回收、共享对象的功能。
redisObject与存储相关的字段
1)、type:表示了对象的类型,占4个比特;
2)、encoding:表示内部编码对象,占4个比特,redis支持的每种类型,至少有两种内部编码。比如字符串,有int、embstr、raw三种编码。通过encoding属性,redis可以根据不同的使用场景来 为对象设置不同的编码,大大提高了redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
3)、lur记录的时该对象最后一次被命令访问的时间。可以计算出该对象的闲置时间。
4)、refcount:记录了该对象被引用的次数,类型为整型,只要在于对象的引用计数和内存回收,当refcount变为0时,对象占用的内存将被释放
redis中多次被使用的对象被称为共享对象,redis为了节约内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象,这个被重复使用的对象就是共享对象,目前共享对象只支持数值的字符串对象。这是因为共享对象虽然可以节省内存,但是判断对象是否相等却需要消耗额外的时间,对于数值的判断,时间复杂度为O(1),对于字符串,判断时间复杂度为O(n),对于hash、list、set、zset,复杂度为 O(n^2),redis服务器 初始化时,会创建10000个字符串对象,分别是0-9999的 整数值。
5)、ptr:指针指向具体的数据。
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节
4.SDS:
SDS结构如下:
`struct` `sdshdr {`` ``int` `len;`` ``int` `free``;`` ``char` `buf[];``};`
其中buf表示的字节数组,用来存储字符串;len为buf已经使用的长度;free为buf未使用的长度
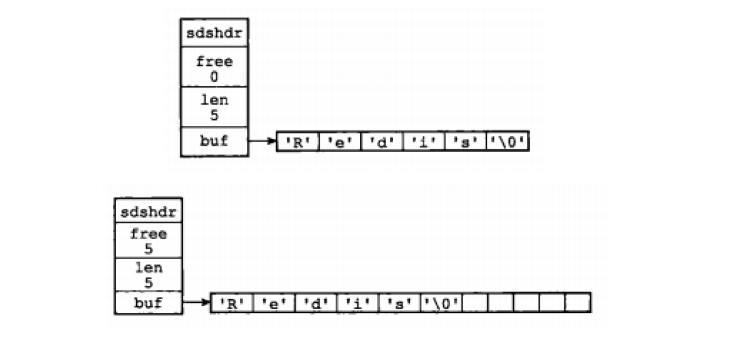
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
SDS与C字符串的比较
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
获取字符串长度:SDS是O(1),C字符串是O(n)
缓冲区溢出:使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重
新分配内存,杜绝了缓冲区溢出。
修改字符串时内存的重分配:对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
存取二进制数据:SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS
以字符串长度len来作为字符串结束标识,因此没有这个问题。
此外,由于SDS中的buf仍然使用了C字符串(即以’\0’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。

