

深度学习归一化:BN、GN与FRN
在深度学习中,使用归一化层成为了很多网络的标配。最近,研究了不同的归一化层,如BN,GN和FRN。接下来,介绍一下这三种归一化算法。
BN层
BN层是由谷歌提出的,其相关论文为《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,即Inception v2的主要思想。大家也可以看回我以前的博客,关于这个BN层的介绍。
BN层的提出,主要解决的一个问题是Internal Covariate Shift。在BN层提出以前,是很难训练一个深层次的网络的,其主要难点是每层的数据分布均会发生变化,使得神经元需要去学习新的分布,导致模型训练缓慢、难以收敛。因此,作者借助了白化的思想,将每层数据都归一化成均值为0、方差为1的分布,如公式(1)所示,即减去均值、除以方差。这样就能是每层的数据分布不会发生过大变化,从而导致模型容易训练。
$$\hat{x}^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var(x^{(k)})}} \tag{1}$$
但同时也引入了一个问题,我们将数据强行的归一化,会导致原始的数据分布遭到破坏,特征的表达能力就会下降。所以,BN层的核心亮点是重构变换。引入两个可学习的变量$\gamma $和$\beta $,分别表示缩放与偏差,如公式(2)所示。模型通过学习$\gamma $和$\beta $,来重构还原归一化的分布。当$\gamma ^{(k)}=\sqrt{Var[x^{(k)}]}$和$\beta ^{(k)}=E[x^{(k)}]$时,就能完全还原原来的分布了。
$$y^{(k)}=\gamma ^{(k)}\hat {x}^{(k)}+\beta ^{(k)} \tag{2}$$
因此,BN层的算法如下图所示。首先计算该神经元输入的均值$\mu _B $和方差$\sigma ^2_B $,再对数据进行标准化,得到$\hat{x}_i$,最后对进行重构还原,得到$y_i$。所以,BN层的输出应该是$y_i$,而不是$\hat{x}_i$。

那么对于一个深度神经网络而言,具体又是如何操作的呢?在模型训练中,我们一般都是使用一个batch size来对模型进行单次优化。假设某一BN层的输入为$x_i$,其shape为$[B,C,H,W]$,分别表示batch、channels、特征图的高和宽。一个神经元即对应一个通道,需要对$B\times H\times W$个值进行计算均值和方差,然后进行重构变换。在这一层中,需要计算$C$个通道,每个通道会生成一个$\gamma $,一个$\beta $,一个$\mu _B $和一个$\sigma ^2_B $。对于不同的batch,其$\mu _B $和一个$\sigma ^2_B $都是不一样的,$\mu _B $和$\sigma ^2_B $对应的是当前batch的均值与方差。而$\gamma $和$\beta $对应的是该通道(神经元)的缩放和偏移。
而在测试中,由于输入只有一个样本,如果用着一个样本来进行估计均值与方差,会导致巨大的偏差。所以,测试阶段,$\gamma $和$\beta $是使用当前通道的缩放和偏移,是网络学习来的参数;而该神经元的均值与方差使用的是所有训练样本在该神经元上的均值与方差的无偏估计。
具体要如何操作呢?在训练阶段,会把所有均值和方差都保存下来,最后再计算一个无偏估计即可。对于Pytoch而言,同通过公式(3)来保存以往的均值和方差。其中,$\hat{x}_\text{new}$是新的均值或者方差,$momentum$是动量,与优化器的动量不一样,这里默认是0.1,$\hat{x}$是上一次的估计量(均值或者方差),$x_t$是当前的估计量(均值或者方差)。通过这样的计算,将均值和方差保存下来用于测试阶段。但是,这个保存下来的均值和方差是用于测试阶段的,训练时用的是当前batch的均值和方差。
$$\hat{x}_\text{new} = (1 - \text{momentum}) \times \hat{x} + \text{momentum} \times x_t \tag{3}$$
所以,一个BN层,会保存下来$4C$个参数,分别是$C$个$\gamma $,$C$个$\beta $,$C$个$\mu _B $和$C$个$\sigma ^2_B $。
BN层有很多优点,例如加速训练速度、缓解梯度弥散等,但可以从上述分析看出,BN层与batch size密切关系,如果batch size过小,会受到过多干扰。在很多大型网络中,如语义分割,受到显存的限制,batch size可能是1、2或者4,即比较小的batch size,此时,无法正确估计出当前batch的均值与方差。
当然,这个可以通过工程上的trick来进行解决,即训练多几次才进行参数更新。在pytorch中,可以训练N个batch后,将N个参数进行相加,再进行更新;在caffe中,可以在solver中设置iter_size来使训练N步后再进行参数更新。这样做,就可以就相当于使用了$N\times batch$的样本进行训练,解决了batch size过小引起的问题。
GN层
BN算法受到batch size的影响,因此,就有很多研究员想如何通过消除batch size的影响来实现归一化。有很多优秀的方法,例如Layer Norm,Instance Norm和Group Norm。在这里,重点介绍一个Group Norm。
Group Normalization来自于2018年Facebook《Group Normalization》,其主要解决的一个问题就是,当batch size很小时,如何才能正确的归一化。
无论BN、LN、IN还是GN,其归一化都是执行公式(4):
$$\hat{x}_i=\frac{1}{\sigma _i}(x_i-\mu _i) \tag{4}$$
其中,$\mu$和$\sigma $表示均值和标准差:
$$\mu_i=\frac{1}{m}\sum _{k\in S_i}x_k,\ \sigma _i=\sqrt{\frac{1}{m}\sum _{k\in S_i}(x_k-\mu _i)^2+\epsilon } \tag{5}$$
其中,$\epsilon $是一个很小的常数;而$S_i$表示对哪些像素集合进行求均值和方差。不同的归一化方式,造成$S_i$的不同。
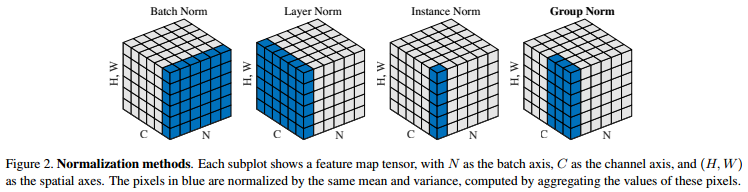
下图是不同归一化方式的$S_i$取值方式。蓝色表示选取哪些集合来计算均值和方差。BN层是沿着维度C的方向,计算$(N,H,W)$的均值和方差;LN层是沿着维度N的方向,计算$(C,H,W)$的均值和方差;IN层是验证维度N和维度C的方向,计算$(H,W)$的均值和方差。
当将特征归一化完后,通常都会进行“变换重构”:
$$y_i=\gamma \hat{x}_i+\beta \tag{6}$$
其中,$\gamma $和$\beta $是可学习的变量。
对于GN层,在某一层中,将一个样本的C个特征通道分成G组(默认情况下,$G=32$),每组中包含$\left \lfloor \frac{C}{G} \right \rfloor$个特征通道。我们将使用每个样本下的每个分组来计算均值和方差,即计算$\frac{C}{G}\times H\times W$个值得均值和方差。在这里,$G$值是超参,$\left \lfloor \cdot \right \rfloor$是地板除法(向下取整)。以上图中最右边的GN图例为例,batch size为6,每个样本中有$C=6$个特征通道,我们将其分成两组$G=2$,此时每组具有$C/G=3$个通道,即蓝色部分,对蓝色部分计算均值和方差。
在同一组中,每个特征值使用当前组计算出来的均值$\mu $和方差$\sigma $。同样,GN也需要变换重构,对于公式(6),GN会计算每个通道(不是每个组)的可学习变量$\gamma $和$\beta $。论文中给出了Tensorflow的代码,和BN层很类似。

可以看出,如果$G=1$的话,即使用所有特征通道,等于变成了LN;若$G=C$的话,即只使用一个通道,等于变成了IN。与LN对比,GN约束性小了,可以更加灵活的学习到不同分组之间的不同分布,能有效提高模型的表达能力;与IN相比,GN利用了通道之间的关系。
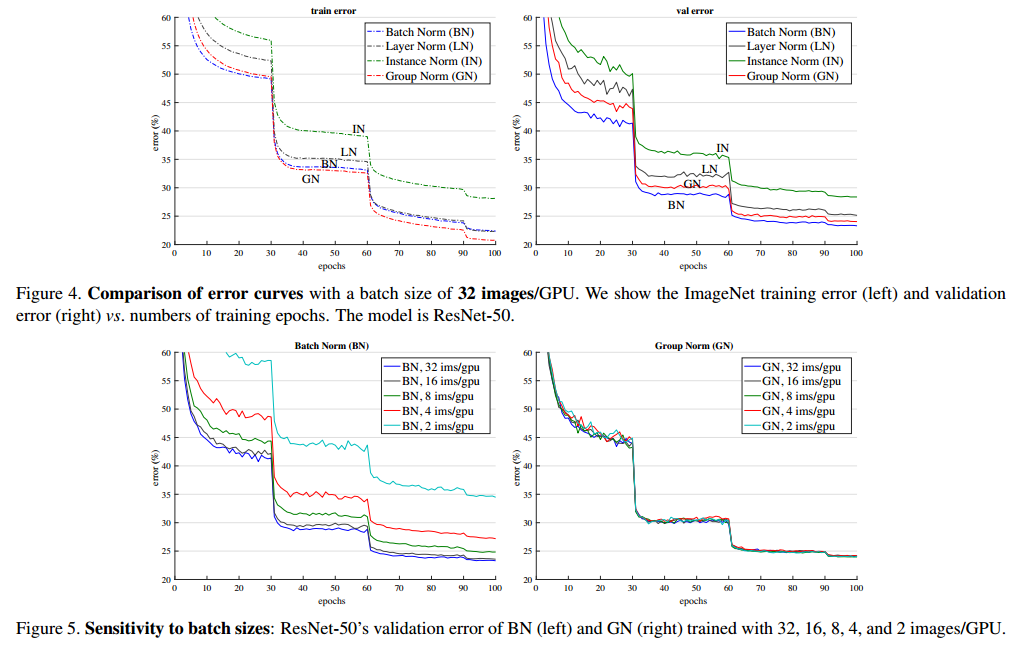
从实验结果来看,当batch size为32时,验证集上,BN的效果略好于GN层,两者差异不是特别大。但当batch size变小时,使用BN层的模型的性能迅速下降,而GN层不怎么受batch size的影响,表现稳定,比BN效果好很多。
另外值得注意一点是,论文中作者对实验细节的表述特别棒,论文中提及到一点,目标检测或者语义分割时,头结构使用GN比使用BN的效果更好,因为在目标检测中,ROI区域是从相同的图片采样得到的,它们不满足独立同分布,而非独立同分布会弱化BN层的均值和方差分布,所以导致在头结构中使用BN层效果更差。
为什么GN层会有这样的效果呢?最主要的原因是,用于表示物体特征的通道并非完全独立的,可能会存在多个通道表示同一个特征的情况。所以在这一组特征通道中,这些特征值具有同分布的性质。对这一组内的特征进行group normalization,是一种比较合理的方法。(但这里不明确的是,表示统一特征之间的通道被分配到多个不同的组,这种情况该如何解决。)
最后,介绍一下GN层在pytorch中的用法,如下所示。其中, num_groups 表示需要分成多少组, num_channel 表示输入通道数, eps 表示一个很小的常数, affine 表示是否需要进行变换重构。
import torch import torch.nn as nn nn.GroupNorm(num_groups=32, num_channel=64, eps=1e-5, affine=True)
综上所述,GN层解决了batch size较小时引起的问题,通过将通道分成G组,以此来计算均值和方差,实现对一个样本的归一化。
FRN层
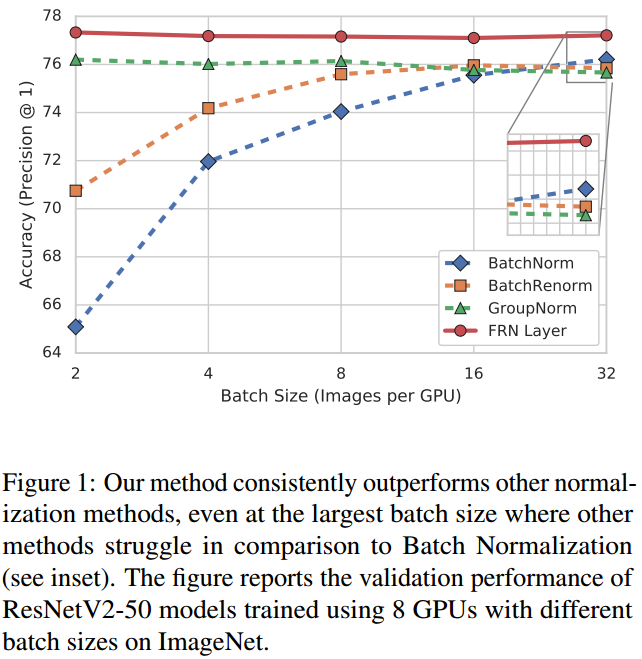
FRN层是谷歌在2019年的《Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks》中提出的。虽然GN解决了小batch size时的问题,但在正常的batch size时,其精度依然比不上BN层,如下图所示。因此,有什么办法能解决归一化既不依赖于batch,又能使精度高于BN呢?FRN就是为了解决这个问题。
FRN层由两部分组成,Filtere Response Normalization (FRN)和Thresholded Linear Unit (TLU)。
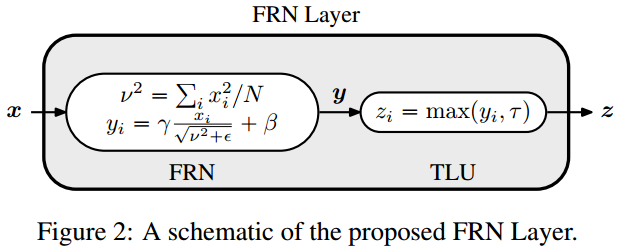
假设输入x的shape为$(B,C,H,W)$,分别表示batch size、通道数,特征图的高宽。首先,先对每一个样本的每一个通道单独进行归一化,即使用$N=H\times W$个特征值来求取平均平方和$\nu ^2$。然后对这$N=H\times W$个特征值进行公式(7)的计算:
$$\hat{x}_i=\frac{x_i}{\nu ^2+\epsilon } \tag{7}$$
其中,$\epsilon $是一个很小的正常数,防止除以零。这样的操作注意,有利于消除又中间操作引起的尺寸变化问题[2]。这里并不是传统意义上的归一化,它没有减去均值,除以的也不是方差。然后对于每个通道,同样进行变换重构。
由于在FRN操作中没有减去均值,会导致“归一化”后的特征值不是关于零对称,会以任意的方式偏移零值。如果使用ReLU作为激活函数的话,会引起误差,产生很多零值,性能下降。所以需要对ReLU进行增强,即TLU,引入一个可学习的阈值$\tau $:
$$z_{TLU}=max(y,\tau )=max(y-\tau ,0)+\tau =ReLU(y-\tau )+\tau \tag{8}$$
从上面来看,FRN层引入了$\gamma $、$\beta $和$\tau $三个可学习的参数,分别学习变换重构的尺度、偏移和阈值,他们都具有$C$个值,对应每一个通道。
一般情况下,特征图的大小$N=H\times N$都比较大,但也有$N=1$的情况(全连接或者特征图为$1 \times 1$)。在$N=1$的情况下,对于公式(7),若$\epsilon $很小,则会变成一个sign函数,梯度值变得很小,不利于优化;若$\epsilon $相对较大,则曲线会平滑一点,容易优化。如下图所示。因此,$\epsilon $的取值对于$N=1$的情况有重要影响。
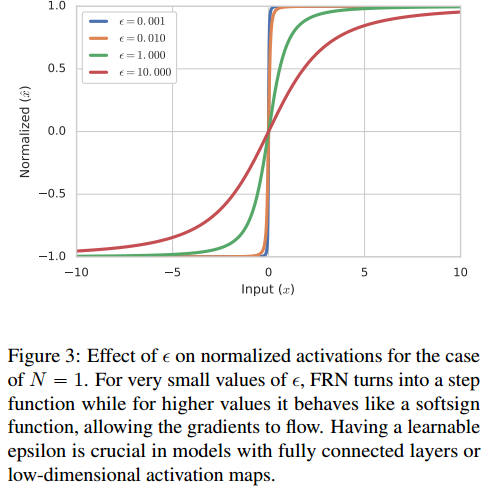
在$N=1$的情况下,将$\epsilon $变成一个可学习的参数(初始化为$10^{-4}$);而对于$N\neq 1$时,将$\epsilon $固定成$10^{-6}$。为了保证可学习参数$\epsilon >0$,对其进行一定限制,$\epsilon =10^{-6}+\left | \epsilon _l \right |$。
在Tensorflow中,FRN层的代码如下。

另外,在实验上,存在几个可以关注的细节:
- 由于FRN层没有均值中心化,所以会有一些模型对初始学习率的选择十分敏感,特别是那些使用了多个最大池化层的网络。为了缓解这个问题,作者建议使用warm-up来对学习率进行调整。
- 一般而言,FC层后一般都不会接归一化层,这是因为均值和方差计算的数量太少,难以正确估计。但如果FC层后接FRN层,性能不会下降,反而会有上升。
- 作者对BN+TLU或者GN+TLU或者FRN+ReLU等系列都做过实验对比,还是发现FRN+TLU的搭配是 最好的。
总结
BN层是现在大部分网络的标配,但其若batch size较小时,性能会表现较差;GN层就是为了解决batch size较小时,依然能使网络具有较好的性能,但是在大batch size时,性能依然比不上BN层;FRN层同时解决了mini-batch size的问题,同时又保证性能比BN层好。
参考文献:

